Pine Script®入门指南
第一步
l 简介
l 使用脚本
u 从图表中加载脚本
u 浏览社区脚本
u 更改脚本设置
l 读取脚本
l 编写脚本
简介
欢迎阅读《Pine Script® v5用户手册》,该手册将陪伴您学习如何使用Pine Script®编写自己的交易工具。
在本页中,我们将为您提供一个循序渐进的方法,让您逐步熟悉TradingView上使用Pine Script®编程语言编写的指标和策略(也称为脚本)。我们将帮助您开始以下旅程:
l 使用平台上数以万计的现有脚本。
l 阅读现有脚本的Pine Script®代码。
l 编写Pine Script®脚本。
使用脚本
如果您有兴趣在TradingView上使用技术指标或策略,您可以首先开始探索我们平台上已有的数千种指标。您可以通过两种不同的方式访问平台上的现有指标:
l 1使用图表的 "指标与策略 "按钮,或
l 2浏览TradingView的社区脚本,这是世界上最大的交易脚本库,拥有超过100,000个脚本,其中大部分都是免费开源的,这意味着您可以看到它们的Pine Script®代码。
从图表中加载脚本
使用"指标与策略"按钮,探索并加载图表中的脚本:
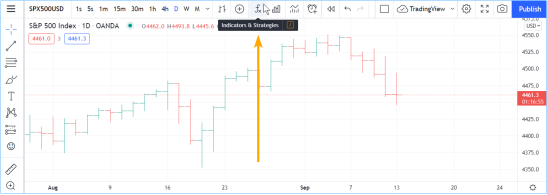
对话框左侧窗格显示不同类别的脚本:
l "收藏"(Favorites)列出了你 "已收藏 "的脚本,通过点击脚本名称左侧的星号即可加入“收藏”。
l 我的脚本(My scripts)显示您在 Pine Script® 编辑器中编写并保存的脚本。它们保存在TradingView的云中。
l 技术(Built-ins) 将所有 TradingVIew 内置工具分为四类:指标、策略、(图表)形态和(成交量)分布图。其中大部分使用 Pine Script® 编写,可免费使用。
l Community Scripts(社区脚本):您可以从 TradingView 用户编写的 100,000 多个已发布脚本中进行搜索。
l Invite-only scripts(只接受邀请的脚本)包含作者授予您访问权限的只接受邀请的脚本列表。
这里选择了包含 TradingView 技术(Built-ins)的部分:
点击其中一个指标或策略(名称后带有绿色和红色箭头的是策略)后,它们就会加载到您的图表上。
浏览社区脚本
在TradingView主页上,您可以从"Community(社区)"菜单调出社区脚本流。在这里,我们指向的是"Editors’ Picks(编辑精选)"部分,但还有许多其他类别供您选择:
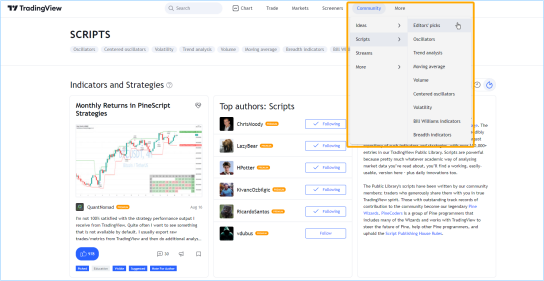
您还可以使用主页的 “Search(搜索)” 字段搜索脚本,并使用不同的条件过滤脚本。帮助中心有一个页面解释了可用脚本的不同类型。
脚本库陈列了脚本展示窗口,每个展示位显示了发布脚本的图表、说明及其作者。通过点击它,您可以打开脚本页面,在这里您可以在图表上看到脚本,阅读作者的描述,点赞脚本,留下评论或阅读脚本的源代码(如果脚本是开源发布的)。
当你在社区脚本中找到感兴趣的脚本后,请按照帮助中心的说明将其加载到图表。
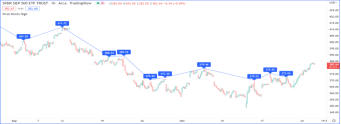
更改脚本设置
在图表上加载脚本后,可以双击脚本名称(#1),弹出 "设置/输入 "选项卡(#2):
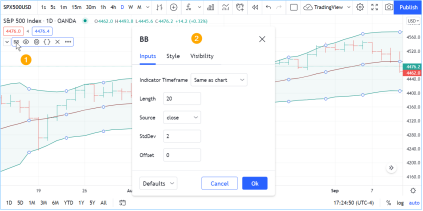
“Inputs”(输入)选项卡允许您更改脚本作者决定可编辑的设置。您可以使用同一对话框的“Style样式”选项卡配置脚本的某些视觉效果,还可以使用“Visibility可见性”选项卡配置脚本应在哪些时间段出现。
所有脚本都可以通过鼠标移至其名称右侧的按钮和 "更多More"菜单(三个圆点)进行其他设置:
阅读脚本
阅读优秀程序员编写的代码是加深对编程语言理解的最佳途径。这一点对于 Pine Script® 和其他编程语言一样适用。寻找优秀的开源 Pine Script® 代码相对容易。在TradingView上可以找到由优秀程序员编写的可靠代码来源:
l TradingView 内置指标built-in indicators
l 被选为编辑精选的脚本
l PineCoders账户关注的作者编写的脚本
l 许多脚本的作者都具有很高的声誉并发表过开源文章。
阅读社区脚本中的代码非常简单:如果你在脚本窗口右上角没有看到灰色或红色的"lock"图标,则表明该脚本是开源的。打开脚本页面,就能看到其源代码。
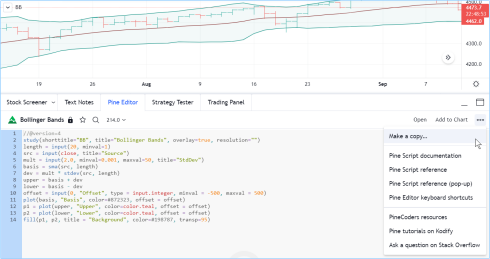
要查看TradingView内置程序的代码,请在图表上加载该指标,然后将鼠标悬停在其名称上,选择“Source code”大括号图标(如果看不到该图标,那是因为该指标的源代码不可用)。点击该图标后,Pine Script® 编辑器就会打开,在这里你可以看到脚本的代码。如果你想使用它,需要使用编辑器窗格右上方的 "更多 "菜单按钮,并选择 "复制..."。然后,您就可以修改并保存代码了。由于您创建的是不同版本的脚本,因此需要使用编辑器的 "添加到图表 "按钮将新副本添加到图表中。
图中显示的是我们从图表上的指标中选择 "查看源代码 "按钮后刚刚打开的 Pine Script® 编辑器。由于该指标目前为只读状态(编辑器中文件名附近的 "锁"图标表示),因此我们即将复制该指标的源代码:
您也可以使用 "打开/新建默认内置脚本... "菜单选项,从 Pine Script® 编辑器(可从图表底部的"Pine Script® 编辑器"选项卡访问)中打开 TradingView 内置指标。
编写脚本
我们创建Pine Script®的目的是让新手和经验丰富的交易者都能创建自己的交易工具。我们设计的脚本对于初学者来说相对简单易学(当然,跟学习交易一样,学习第一门编程语言对于任何人来说同样不是一件容易的事情),但其强大的功能足以让知识渊博的程序员开发出复杂程度适中的工具。
Pine Script®允许你编写三种类型的脚本:
l 指标,如RSI、MACD等。
l 策略,包括发出交易指令的逻辑,可进行回溯测试和前瞻测试。
l 库:高级程序员使用的库,用于打包其他脚本可以重复使用的常用函数。
我们建议的下一步是编写第一个指标。
第一个指标
Pine Script®编辑器
Pine Script®编辑器是您编写脚本的地方。虽然你可以使用任何你想要编写Pine脚本的文本编辑器,但使用我们的编辑器有许多优点:
l 它突出显示遵循Pine Script®的语法。
l 当鼠标悬停在内置函数和库函数上时,它会弹出语法提醒。
l 当您按住ctrl 或 cmd 键并点击 Pine Script®关键字时,它提供了快速访问Pine Script®v5参考手册的弹出框。
l 它提供了一个自动补全功能,你可以用ctrl +空格/ cmd +空格激活。
l 它使编写/编译/运行周期快速,因为加载在图表上的脚本的新版本保存后会立即执行它。
l 虽然不像顶级编辑器那样功能丰富,但它提供了搜索和替换、多光标和版本控制等关键功能。
要打开编辑器,请单击TradingView图表底部的“Pine Script®Editor”选项卡。这将打开编辑器窗格。
第一个模本
我们现在将创建我们的第一个工作的Pine脚本,在Pine script®中实现MACD指标:
1 2 3 4 5 6 7 8 910 | //@version=5 |
l 首先在编辑器的右上角打开“Open”下拉菜单,然后选择“New blank indicator”。
l 然后复制上面的示例脚本,注意不要包含你选择的行号。
l 选择编辑器中已经存在的所有代码,并用示例脚本替换它。
l 点击“保存”并为你的脚本选择一个名称。您的脚本现在保存在TradingView的云里,并在您的帐户名下。除了你,没人能用。
l 点击编辑器菜单栏中的“添加到图表”。MACD指标出现在图表下方的单独窗口中。
你的第一个Pine脚本正在图表上运行,看起来应该像这样:
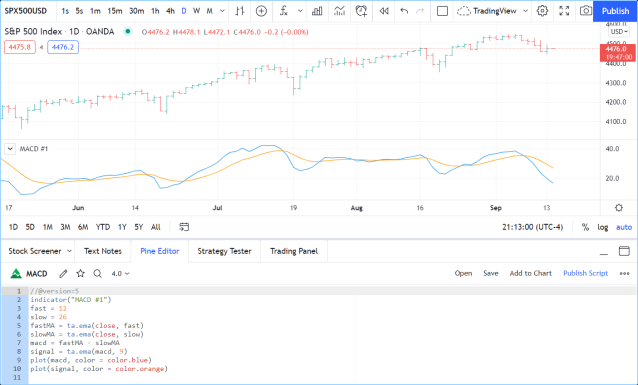
让我们逐行看一下脚本的代码:
Line 1: //@version=5
这是一个编译器注释,告诉编译器脚本将使用Pine script®的版本5。
Line 2: indicator("MACD #1")
定义将出现在图表上的脚本的名称为“MACD”。
Line 3: fast = 12
定义一个快速整型变量,它是快速EMA的长度。
Line 4: slow = 26
定义一个慢速整型变量,它是慢速EMA的长度。
Line 5: fastMA = ta.ema(close, fast)
定义变量fastMA,由一系列收盘价(即K线的收盘价)为基准计算EMA值(指数移动平均线),计算长度等于fast(12),计算结果赋值给fastMA。
Line 6: slowMA = ta.ema(close, slow)
定义变量slowMA,长度等于slow(26)的收盘价来计算出的EMA的结果,赋值。
Line 7: macd = fastMA - slowMA
定义变量macd为两个ema的差值。
Line 8: signal = ta.ema(macd, 9)
使用EMA算法(指数移动平均)将变量signal定义为macd的平滑值,长度为9。
Line 9: plot(macd, color = color.blue)
调用plot函数,用蓝色线输出变量macd。
Line 10: plot(signal, color = color.orange)
调用plot函数,用橙色线输出变量signal。
第二个模本
我们的第一个脚本模本是“手动”计算MACD,由于Pine script®旨在编写指标和策略,内置的Pine script®函数包涵了许多常见指标,其中就有MACD: ta.macd()。
这是我们脚本的第二个模本:
1234567 | //@version=5 |
注意,此模本:
· 增加了输入功能,这样用户可以改变MAs的长度
· 使用内置ta.macd()函数来计算MACD,这样可以节省3行代码,并使代码更易于阅读。
让我们重复之前的过程,将代码复制到一个新指标中:
· 首先在编辑器的右上角打开“Open”下拉菜单,然后选择“New blank indicator”(新指标)。
· 然后复制上面的示例脚本,同样注意不要复制行号。
· 选中编辑器中已经存在的所有代码,并用我们复制的第二个模本的代码将其替换。
· 单击“保存”,并选择一个不同于前一个脚本的名称为您的脚本命名。
· 点击编辑器菜单栏中的“添加到图表”。“MACD #2”指标出现在“MACD #1”指标下方的单独窗格中。
你的第二个Pine脚本便在你的图表上运行了。如果你双击图表上指标的名称,将弹出“设置/输入”选项卡,在那里你可以更改慢速线和快速线的长度:
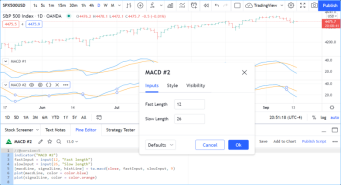
让我们看一下脚本第二个模本中修改的那些行:
Line 2: indicator("MACD #2")
我们将#1改为了#2,这样我们指标的第二个模本在图表中显示的名称不同。
Line 3: fastInput = input(12, "Fast length")
这里我们没有用常量来给变量赋值,而是用input()函数-通过“Settings/Inputs”选项卡来更改参数值。12是默认参数值,“Fast length”是字段标签。如果在“Inputs”选项卡中更改参数值,fastInput变量将被赋予新值,脚本将使用新值在图表上重新执行。请注意,根据《Pine Script® 样式指南》的变量命名建议,我们在变量名的后面加了Input,以便出现在后面的脚本中时提醒我们此变量的值来自用户输入。
Line 4: slowInput = input(26, "Slow length")
我们对慢速线的取值长度做同样的处理,注意要使用不同的变量名、默认值,并使用不同的文本字符串来命名字段标签。
Line 5: [macdLine, signalLine, histLine] = ta.macd(close, fastInput, slowInput, 9)
在这里,我们调用内置ta.macd()来用一行代码执行第一个模本中的所有计算。这个函数需要4个参数(函数名后面括号里的值)。它向三个变量返回三个值,而不是像之前使用的函数那样只返回一个值,这就是为什么我们要将接收函数结果的三个变量列在“=”左边的方括号中。请注意,我们传递给函数的两个值是包含快速长度和慢速长度的“输入”变量:fastInput和slowInput。
第6行和第7行:
这里绘图函数的变量名发生了变化,但线条的绘制与第一个模本相同。
第二个模本的计算结果与第一个版本相同,但可以改变用于计算的两个长度值。代码也更简单,缩短了3行,优化了脚本。
下一步
“指标”vs“策略”
Pine Script®里的策略用于历史数据的回测和公开市场的前向测试。除了指标计算之外,它们还包含strategy.*()调用,用于将交易订单发送到Pine Script®的经纪人模拟器,然后该模拟器可以进行模拟执行。Strategies(策略)在图表底部“Strategy Tester”选项卡中显示回测结果,紧挨着“Pine Script®Editor”选项卡。
Pine Script®指标也包含计算,但不能用于回测。因为它们不需要代理模拟器,所以它们使用的资源更少,运行速度更快。因此,尽可能使用指标是有好处的。
指标和策略都可以在覆盖模式(显示在图表的K线上)或窗格模式(显示在图表的上方或下方的单独窗格中)中运行。它们都可以在各自的空间中绘制信息,也都可以生成警报事件。
脚本如何执行
Pine 脚本不像许多编程语言中的程序,执行一次就会停止。在 Pine Script® 的运行环境中,脚本的运行相当于一个无形的循环,从左到右,每一个图表K线都会执行一次脚本。执行脚本时,已经收盘的图表K线称为历史K线。当脚本执行到图表的最后一个K线且市场处于开放状态时,脚本就会在实时K线上执行。然后,每次检测到价格或成交量变化时,脚本都会执行一次,并在该实时K线关闭时最后执行一次。此时,该实时K线就成了一个失效的实时K线。注意,当脚本实时执行时,它不会在每次价格/成交量更新时对图表的所有历史K线进行重新计算。脚本已经对这些K线计算过一次,因此不需要在每个图表刻度上重新计算。更多信息请参阅执行模型页面。
当脚本在历史K线上执行时,内置变量close会保存该K线的收盘价。当脚本在实时K线上执行时,close返回交易品种的当前价格,直到K线区间收盘。
与指标相反,策略通常只在实时K线收盘时执行一次。如果你需要,也可以配置为在每次价格/成交量更新时执行。有关更多信息,请参阅关于策略的页面,并了解策略与指标的不同计算方式。
时间序列
Pine Script®中使用的主要数据结构称为时间序列。时间序列包含脚本在每个K线上执行的一个值,因此随着脚本在更多的K线上执行,时间序列不断扩展。可以使用history-referencing操作符引用时间序列的过去值:[],例如:Close[1],指的是脚本执行位置前一个K线的收盘价。
这种索引机制会让许多程序员想到数组,但时间序列与数组不同。如果从数组的角度思考时间序列,将不利于理解这个关键的Pine Script®概念。在理解Pine脚本如何工作时,对执行模型和时间序列的良好理解是必不可少的。如果你以前从未处理过时间序列数据,那么你就需要多加练习,让它们为你所用。一旦熟悉了这些关键概念,你就会发现通过将时间序列与我们专为高效处理时间序列而设计的内置函数相结合,只需几行代码就能完成很多工作。
发布脚本
TradingView是Pine Script®程序员大军和来自世界各地的数百万交易员群体的家园。一旦您熟练掌握了Pine Script®,您就可以选择与其他交易者分享您的脚本。在此之前,请花些时间充分学习Pine Script®,以便为交易者提供一个原创的、可靠的工具。所有公开发布的脚本都将由我们的版主团队进行分析,且必须符合我们的脚本发布规则,要求脚本必须是原创的,并有详细的文档说明。
如果你只是自己使用Pine脚本,只需在Pine Script®编辑器中编写,并直接从那里添加到图表中;您无需发布就能使用它们。如果您只想与几个朋友分享您的脚本,您可以私下发布它们,并将浏览器的链接发送给您的朋友。有关更多信息,请参阅发布页面。
了解Pine Script®文档
从已发布的脚本中阅读代码无疑是有用的,但要达到熟练掌握 Pine Script® 的程度,还需要花时间阅读我们的文档。我们有关Pine Script®的两个主要文档来源是:
· 本Pine Script®v5用户手册
· 我们的Pine Script®v5参考手册
Pine Script®v5用户手册是HTML格式的,只有英文版。
Pine Script®v5参考手册记录了每个变量、函数或关键字的功能。它是所有Pine Script®程序员的必备工具;如果你不参考它就去编写复杂的脚本,你将万分痛苦。参考手册有两种格式:一种是我们刚刚链接到的 HTML 版本,另一种是弹出式版本。弹出式版本可以在编辑器中通过ctrl + clicking 点击关键字,或使用的 “More/Pine Script® reference (pop-up)” 下拉菜单进行访问。《参考手册》有多种语言版本。
另外Pine Script® 有五个不同版本。请确保你使用的版本与你使用的Pine Script®版本一致。
从这里到哪里去?
这本《Pine Script® v5 用户手册》包含了大量的示例代码,用于说明我们所讨论的概念。通过阅读本手册,你既能学习Pine Script®的基础知识,又能研究示例脚本。阅读关键概念并立即用实际代码进行尝试,是学习任何编程语言的有效方法。希望你已经在 "第一个指标 "页面中完成了这一步骤,在编辑器中复制本文档的示例,并使用它们。探索!你不会弄坏任何东西。
这是您正在阅读的Pine Script®v5用户手册的组织方式:
· Language section(语言部分)解释了Pine Script®语言的主要组成部分以及脚本的执行方式。
· Concepts section(概念部分)以任务为导向。它解释如何在Pine Script®中执行任务。
· Writing section(编写部分)介绍了帮助您编写和发布脚本的工具和技巧。
· FAQ section(常见部分)回答了Pine Script®程序员的常见问题。
· Error messages page(错误消息页面)记录了最常见的运行和编译错误产生的原因和修复方法。。
· Release Notes(发布说明)页面,您可以了解Pine Script®更新情况。
语法
执行模型
· 基于历史K线的计算
· 基于实时K线的计算
· 触发脚本执行的事件
· 更多的信息
· 函数的历史价值
Pine Script®运行时的执行模型与Pine Script®的时间序列和类型系统密切相关。理解这三者是充分发挥Pine Script®强大功能的关键。
执行模型决定了脚本在图表中的执行方式,也决定了脚本中的代码如何运行。如果Pine Script®没有运行,你的代码将什么也做不了。当你的代码编译并遇到触发执行脚本的事件,运行就会启动,并将代码在图表上执行。
当在图表上加载Pine脚本时,它会使用每个K线的可用OHLCV(打开、高、低、关闭、成交量)值在每个历史K线上执行一次。一旦脚本执行到达数据集中最右边的K线,如果当前图表上的品种交易活跃,那么每次更新(即价格或成交量变化)时,Pine Script® 指标都会执行一次。Pine Script®策略默认只在最右边的K线收盘时执行,但通过修改参数也可以像指标一样,在每次更新时执行。
交易品种/时间框架对(symbol/timeframe pairs)都有一个包含有限数量K线的数据集。当你向左滚动图表以查看数据集之前的K线时,图表上会加载相应的K线。当没有更多特定交易品种/时间框架对的K线或您的帐户类型允许加载的最大K线数时,加载过程停止。你可以向左滚动图表,直到数据集的第一个K线,它的索引值为0(参见bar_index)。
当脚本第一次在图表上运行时,数据集中的所有K线都是历史K线,最右边的K线除外--如果交易时段处于活动状态时。当最右边的K线交易活跃时,它被称为实时K线。当检测到价格或成交量变化时,实时K线就会更新。当实时K线关闭时,它将成为一个已失效的实时K线,并打开一个新的实时K线。
基于历史K线的计算
让我们看一个简单的脚本,并跟踪它在历史K线上的执行情况:
//@version=5
indicator("My Script", overlay = true)
src = close
a = ta.sma(src, 5)
b = ta.sma(src, 50)
c = ta.cross(a, b)
plot(a, color = color.blue)
plot(b, color = color.black)
plotshape(c, color = color.red)
在历史K线上,当已知该K线的OHLCV值时,脚本会在K线收盘时刻执行。在K线上执行脚本前,内置变量如open、high、low、close、volume和time,被重赋值为该K线上相应的值。每个历史K线执行一次脚本。
我们的示例脚本首先在数据集索引为0的第一个K线上执行。每条语句都使用当前K线的值执行。相应地,在数据集的第一个K线上,使用下面的语句:
src = close
用第一个K线的收盘价初始化变量src,然后依次执行后面的每一行代码。因为脚本对每个历史K线只执行一次,所以脚本将始终对特定的历史K线使用相同的收盘价进行计算。
脚本中每一行语句的执行都会产生计算,这些计算进而生成指标的输出值,然后将其绘制在图表上。我们的例子中,在脚本末尾调用了plot和plotshape函数来绘制这些值。在使用策略的情况下,计算的结果可用于绘制数值或决定下单。
执行并在第一个K线上绘图后,脚本在数据集的第二个K线上执行,它的索引为1。然后重复该过程,直到处理完数据集中的所有历史K线,脚本到达图表上最右边的K线。
Pine 脚本在实时K线上的行为与在历史K线上的行为截然不同。回想一下,当图表上的交易品种交易活跃时,实时K线是图表上最右边的K线。此外,策略在实时K线上有两种不同的行为方式。默认情况下,策略仅在实时K线收盘时执行,但可以在策略的声明语句calc_on_every_tick中设置参数为"true",使其像指标一样在实时K线每次更新时都执行。因此,这里描述的指标行为只适用于使用 calc_on_every_tick=true 的策略。
在历史K线和实时K线上执行脚本的最大区别在于,脚本在历史K线上只执行一次,而在实时K线中,脚本在每次更新时都会执行一次。这就意味着,在历史K线上从未改变的内置变量(如最高价、最低价和收盘价),在实时K线上会在脚本的每次重新计算时发生改变。脚本计算中使用的内置变量发生变化,反过来也会导致计算结果发生变化。这是脚本跟随实时价格走势所必需的。因此,同一脚本在实时K线中的每次执行都可能产生不同的结果。
注意:在实时K线中,close变量总是代表当前价格。类似地,内置变量high和low表示自实时K线开盘以来达到的最高和最低价。Pine Script®的内置变量将只保留实时K线最后一次更新的最终值。
让我们跟随着我们的脚本示例了解一下实时K线中的运行:
当脚本运行到实时K线时,它会第一次被执行。使用内置变量的当前值生成一系列结果,若需要可绘制出来。在K线下一次更新发生脚本再次执行前,用户定义变量根据前一条K线收盘时最后提交状态,被重置为一个已知的状态。如果变量初始化时(变量在每个K线都会被初始化)没有被明确规定,那么将被重新初始化。在这两种情况下,它们最后计算的状态都会丢失。绘制的标签和线条的状态也会被重置。在实时K线中每次迭代脚本之前,用户定义变量和绘图的重置称为回滚。其作用是将脚本重置为实时K线开盘时的已知状态,因此实时K线中的计算总是从干净的状态开始执行。
随着实时K线中价格或交易量的变化,不断重新计算脚本的值可能会导致这样一种情况,即我们示例中的变量c变为真值,因为出现了交叉,因此脚本最后一行绘制的红色标记将出现在图表上。如果在下一次价格更新中,价格以这样的方式移动,收盘价不再产生使c为真的计算,因为不再有十字,那么先前绘制的标记消失。
当实时K线关闭时,脚本执行最后一次。像往常一样,变量会在执行之前被回滚。然而,由于这次迭代是实时K线上的最后一次迭代,因此当计算完成时,变量将保持为该K线的最终值。
总结一下实时K线流程:
l 脚本在实时K线开盘时执行,然后在每次更新时执行一次。
l 变量在每次实时更新之前被回滚。
l 变量在K线收盘更新时被确定。
触发脚本执行的事件
当发生以下事件之一时,将在图表上的全部K线上执行脚本:
l 新的交易品种或时间框架加载到图表上。
l 脚本从Pine脚本编辑器或图表的“指标和策略”对话框中保存或添加到图表中。®
l 在脚本的“设置/输入”对话框中修改参数值。
l 在策略的“设置/属性”对话框中修改参数值。
l 检测到浏览器刷新事件。
当交易处于活动状态时,脚本在实时K线上执行,并且:
l 出现上述情况之一,导致脚本在实时K线打开时执行,或
l 实时K线会因为检测到价格或交易量变化而更新。
请注意,当市场处于活跃状态时,如果图表未被触发,则已打开然后关闭的一系列实时K线将跟随当前的实时K线。因变量都已确定,这些结束的实时K线也因此确定,但脚本尚未在它们的历史状态下对其执行,因为脚本上次在图表数据集上运行时历史状态并不存在。
当事件触发在图表上执行脚本并使其在现已成为历史K线的K线上运行时,脚本的计算结果有时会与实时K线上同一K线最后一次收盘更新时的计算结果不同。这可能是由于实时K线收盘时保存的 OHLCV 值与相同K线变为历史K线时从数据源获取的 OHLCV 值之间存在细微差别造成的。这种行为是重绘的可能原因之一。
更多信息
l 内置的barstate.* 变量提供了有关执行脚本的K线类型或事件的信息。例如,记录这些变量的页面还包含一个脚本,可以直观显示实时K线和历史K线之间的差异。
l 策略页面解释了策略计算的详细信息,这些计算与指标计算的细节不同。
函数的历史值
Pine 中的每次函数调用都会留下历史值的痕迹,脚本可以使用 [] 运算符在后续K线上访问这些历史值。函数的历史序列依靠连续调用来记录每个K线上的输出。只有确保历史序列的连续性,脚本才能按预期运行。如果脚本不在每个K线上调用函数,可能会产生前后矛盾的历史记录,影响计算和结果。在这些情况下,编译器会警告用户,让他们意识到函数中的值(无论是内置的还是用户定义函数)可能会产生了错误。
为了演示,让我们编写一个脚本来计算当前K线的索引,并在每隔一根K线上输出该值。在下面的脚本中,我们定义了一个calcBarIndex()函数,该函数会在被调用的每条K线内部的索引变量(indes)的前值上加1。脚本中,我们只在条件返回true的K线(每隔一个K线)上调用该函数,来更新customIndex的值。脚本会将该值与内置的bar_index一并绘制,以验证输出结果:
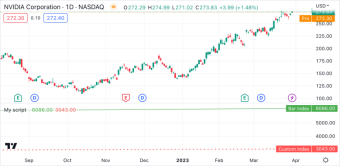
//@version=5
indicator("My script")
//@function 计算当前K线的指数,方法是将上一K线的指数值加上 1。
// 第一个K线的索引为 0.
calcBarIndex() =>
int index = na
index := nz(index[1], replacement = -1) + 1
//@variable 每隔一个K线返回 `true.
condition = bar_index % 2 == 0
int customIndex = na
// 条件为 `true` 时调用 `calcBarIndex()`。这将提示编译器发出警告.
if condition
customIndex := calcBarIndex()
plot(bar_index, "Bar index", color = color.green)
plot(customIndex, "Custom index", color = color.red, style = plot.style_cross)
请注意:
l 函数nz()将na值替换成指定的replacement 值(默认值为0)。在脚本的第一个K线中,当index序列没有历史记录时,在加1之前na值被替换为-1,以返回初始值0。
在检查图表时,我们看到两个图表有很大的不同。这种行为的原因是,脚本在if结构范围内的相隔K线上调用calcBarIndex(),使历史输出值与bar_index系列不一致。当相隔一个K线调用一次函数时,在内部引用index的前一个值将得到相隔K线上的值,即函数执行的最后一个K线。这种行为导致customIndex的值是内置bar_index的一半。
为了将calcBarIndex()的输出值与bar_index的值一致,我们可以将函数调用扩展到脚本的全局作用域。这样,该函数将在每个K线上执行,对所有历史K线进行记录和引用,而不仅仅是作用于间隔K线。在下面的代码中,我们在全局作用域中定义了一个globalScopeBarIndex变量,并将其赋值给calcBarIndex()的返回值,而不是局部调用函数。当条件发生时,脚本将customIndex设置为globalScopeBarIndex 的值:
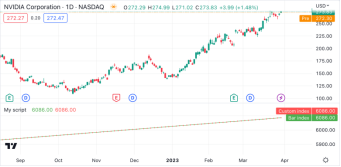
//@version=5
indicator("My script")
//@function 计算当前K线的指数,方法是将上一K线的指数值加 1。
// 第一个K线的索引为 0。 确保有效
calcBarIndex() =>
int index = na
index := nz(index[1], replacement = -1) + 1
//@variable 每第二个K线返回 `true.
condition = bar_index % 2 == 0
globalScopeBarIndex = calcBarIndex()
int customIndex = na
// 当`condition`为`true`时,将`customIndex`指定为`globalScopeBarIndex`。这不会产生警告.
if condition
customIndex := globalScopeBarIndex
plot(bar_index, "Bar index", color = color.green)
plot(customIndex, "Custom index", color = color.red, style = plot.style_cross)
这种行为也会从根本上影响那些从内部引用历史记录的内置函数。例如,ta.sma() 函数会在“后台”引用它的历史值。如果脚本是在某种条件下调用这个函数,而不是在每个K线上都调用,那么计算的值就会产生明显变化。为了确保计算的一致性,可以将ta.sma()赋值给全局作用域中的一个变量,并根据需要引用历史记录。
下面的例子计算三个SMA序列:controlSMA、localSMA和globalSMA。该脚本在一个if结构的全局作用域中计算controlSMA,在局部作用域中计算localSMA。在if结构中,它使用controlSMA的值更新globalSMA的值。我们可以看到,globalSMA和controlSMA的值组成的序列是重合的,而localSMA序列与其他两个序列不同,因为它引用了不完整的历史记录,这些记录影响了它的计算结果:
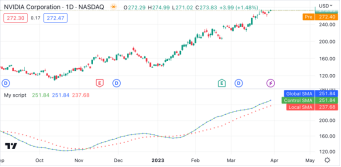
//@version=5
indicator("My script")
//@variable 每第二个K线返回 `true.
condition = bar_index % 2 == 0
controlSMA = ta.sma(close, 20)
float globalSMA = na
float localSMA = na
// 当`条件`为`true`时,更新`globalSMA`和`localSMA`。.
if condition
globalSMA := controlSMA // No warning.
localSMA := ta.sma(close, 20) //引发警告。该函数依赖于其历史记录才能正常工作.
plot(controlSMA, "Control SMA", color = color.green)
plot(globalSMA, "Global SMA", color = color.blue, style = plot.style_cross)
plot(localSMA, "Local SMA", color = color.red, style = plot.style_cross)
为什么会有这种行为?
这种行为是必需的,因为在所有K线上强制执行函数会导致异常结果。如某些函数就可能产生副作用,比如label.new()函数,这类函数除了返回值外,还会执行某些其他操作。label.new()函数会在图表上创建一个标签,在每个K线上强制调用它,哪怕位于 if 结构内部,逻辑上仍会在不该出现标签的地方创建标签。
异常
并非所有内置函数都会在计算中引用它的历史值,这意味着并非所有内置函数都需要在每个K线上执行。例如,math.max()会比较传入它的所有参数并返回最大值。像这种不以任何形式与历史值相互作用的函数就不需要特殊处理。
如果在条件区块中使用函数没有出现编译器警告,那么使用它就是安全的,不会影响计算。否则,应将函数调用移到全局区域,以强制确保执行的一致性。当不顾警告仍将函数调用保留在条件块中时,最少也要确认输出是正确的,以避免意外的结果。
时间序列
Pine Script®的强大功能主要源于它可以高效地处理时间序列。时间序列不是一种形式或类型,而是 Pine Script® 用来存储时间变量连续值的基本结构,其中每个值都与某个时间点相关联。由于图表是由K线组成的,每个K线代表一个特定的时间点,因此时间序列是处理随时间变化的数值的理想数据结构。
时间序列的概念与 Pine Script® 的执行模型及类型系统概念密切相关。了解这三者是充分发挥Pine Script®强大功能的关键。
以内置的open变量为例,它包含数据集中每个K线的"open",数据集涵盖给定的图表上的所有K线。如果脚本在5分钟图表上运行,那么open时间序列中的每个值就是连续 5分钟K线的"open"价格。当脚本调用open时,它调用的是脚本正在执行的K线的"开盘"价格。我们使用[]历史引用运算符来调用时间序列中的过去值。当脚本在给定的K线上执行时,open[1]指的是前一个K线的开盘值。
虽然时间序列可能会让程序员联想到数组,但它们完全不同。Pine Script® 的确使用了数组数据结构,但它与时间序列是完全不同的概念。
Pine Script® 中的时间序列,加上其特殊的运行时引擎和内置函数,使得计算收盘价的累计总和变得非常容易,这无需使用 for 循环,只需使用 ta.cum(close)。之所以能做到这一点,是因为虽然 ta.cum(close) 在脚本中看起来相当静态,但实际上它在每个K线上都会被执行。因此当每个新K线的收盘价被添加到 ta.cum(close) 中时,它的值会变得越来越大。当脚本到达图表最右边的K线时,ta.cum(close) 返回图表上所有K线的收盘价之和。
同样,最近 14 个最高值和最低值之差的平均值可以用 ta.sma(high-low,14)来表达,或者用 barssince(rising(high,5))来表达图表自上次连续创出 5 个较高点以来的距离。
即使是连续K线上的函数调用结果,也会在时间序列中留下值的痕迹,可以使用[]历史引用运算符进行引用。例如,在测试当前K线的收盘价是否突破过去 10个 K线中的最高价(但不包括当前K线)时,这就非常有用,我们可以将其写成 breach = close > highest(close,10)[1]。同样的语句也可以写成 breach = close > highest(close[1],10)。
所有K线上的循环逻辑同样适用于函数调用,如 plot(open),它将在每个K线上重复执行,在图表上连续绘制每个K线的开盘值。
不要混淆“时间序列”(time series)和“序列”(series)的形式两个概念。time series的概念解释了在 Pine Script® 里变量中连续的值是如何存储的;而series的形式是变量的符号(变量值可沿K线变化)。例如,timeframe.period内置变量为形式为 "simple"、类型为"string",即"简单字符串"。"simple"意味着,变量值在0号K线(脚本执行的第一条K线)上是已知的,并且在执行脚本期间不会在任何K线上变化。变量值表示图表的时间框架,格式为字符串,例如,"D"表示1D图表。尽管变量值在脚本执行过程中不会发生变化,但在Pine Script®中,使用timeframe.period[10]来引用10个K线前的变量值在语法上是正确的(尽管用处不大)。这样做是可行的,因为每条K线的timeframe.period的连续值都存储在一个时间序列中,即使该时间序列中的所有值都是相同的。不过请注意,当使用[]运算符访问变量的过去值时,会返回"series"形式的结果,即使此变量是另一种形式,例如timeframe.period中的"simple"。
当你掌握了如何使用 Pine Script® 的语法和执行模式高效处理时间序列后,你就可以用少量代码定义复杂的计算了。
脚本结构
版本
以下形式的编译注释会告诉编译器脚本是用哪个版本的 Pine Script® 编写的:
//@version=5
l 版本号为1 ~ 5。
l 编译器注释不是必需的。如果省略,则假定版本1。强烈建议始终使用该语言的最新版本。
l ·虽然将版本编译器注释放在脚本中的任何位置从语法上讲都是正确的,但如果它出现在脚本的顶部,则对读者更有用。
Release notes(版本说明)中记录了当前版本Pine Script®的显著变化。
声明语句
所有 Pine 脚本都必须包含一条声明语句,即对这些函数之一的调用:
· ·指标indicator()
· ·策略strategy()
· ·库 library()
声明语句:
· 确定脚本的类型,进而决定允许在脚本中包含哪些内容,以及如何使用和执行脚本。
· 设置脚本的关键属性,如名称、添加到图表时的显示位置、显示值的精度和格式,以及控制其运行行为的特定值,如在图表上显示绘制对象的最大数量。对于策略,属性包括控制回测的参数,如初始资金、佣金、滑点等。
每种类型的脚本都有不同的要求:
· 指标必须至少包含一个在图表上产生输出的函数调用,如 plot()、plotshape()、barcolor()、line.new() 等。
· 策略必须至少包含一个strategy.*(),如 strategy.entry()。
· 库(Libraries)必须至少包含一个导出函数或用户定义类型。
代码
脚本中不是注释或编译器注解的行都是语句,用于实现脚本的算法。语句可以是以下其中之一:
· ·变量声明
· ·变量重分配
· ·函数声明
· ·内置函数调用、用户定义函数调用或库函数调用
· ·if、for、while、switch 或类型结构。
语句可以有多种排列方式:
· 单行语句。有些语句可以用一行表达,如大多数变量声明、仅包含函数调用的行、单行函数声明。多行也可以封装成一个语句(一个语句通过多行延续):使用逗号作为分隔符,可以将多个单行语句连接成一个语句。
· 多行语句。结构声明或多行函数声明等语句总是需要多行,因为它们需要一个局部代码块。一个局部代码块必须用一个跳格或四个空格来缩进。每个局部块定义一个局部作用域。
· 脚本全局范围内的声明(即不属于局部代码块的声明)不能以空白(空格或制表符)开始。它们的第一个字符也必须是该行的第一个字符。从行的第一个位置开始的代码行,将定义为脚本全局作用域的一部分。
使用 "打开 "按钮并选择 "新建空白指标",即可在 Pine Script® 编辑器中生成一个简单有效的 Pine Script® v5 指标:
//@version=5
indicator("My Script")
plot(close)
该指标包括三个局部语句块,一个在barIsUp() 函数声明中,两个在使用 if 结构的变量声明中:
//@version=5
indicator("", "", true) // 声明语句 (全局域)
barIsUp() => // 函数声明 (全局域)
close > open // 局部语句块 (局部域)
plotColor = if barIsUp() // 变量声明 (全局域)
color.green // 局部语句块 (局部域)
else
color.red // 局部语句块 (局部域)
bgcolor(color.new(plotColor, 70))//调用内置函数(全局域)
您可以通过选择 "新建空白策略 "生成一个简单的 Pine Script® v5 策略:
//@version=5
strategy("My Strategy", overlay=true, margin_long=100, margin_short=100)
longCondition = ta.crossover(ta.sma(close, 14), ta.sma(close, 28))
if (longCondition)
strategy.entry("My Long Entry Id", strategy.long)
shortCondition = ta.crossunder(ta.sma(close, 14), ta.sma(close, 28))
if (shortCondition)
strategy.entry("My Short Entry Id", strategy.short)
双斜线 (//) 在Pine Script®中定义注释。注释可以从一行的任何地方开始。注释也可以跟在Pine Script®代码后面:
//@version=5
indicator("")
// 此行是注释
a = close //这里是注释
plot(a)
Pine Script® 编辑器有一个注释/取消注释行的快捷键:ctrl + /。 您可以在多行上使用该快捷键,方法是先高亮显示这些行(光标移到该行即可)。
语句行封装
长语句行可以分割成多行,也叫 "封装"。封装的行必须缩进任意数量的空格,只要不是四的倍数(这些缩进用于限定局部域的语句块):
a = open + high + low + close
可封装为:
a = open +
high +
low +
close
长语句函数调用plot() 可封装为:
plot(ta.correlation(src, ovr, length),
color = color.new(color.purple, 40),
style = plot.style_area,
trackprice = true)
用户自定义函数声明中的语句也可以封装。不过,由于局部块在语法上必须以一个缩进单位(4 个空格或 1 个制表符)开始,因此在将其拆分到下一行时,语句的续行必须以一个以上的缩进单位(不等于 4 个空格的倍数)开始。例如:
updown(s) =>
isEqual = s == s[1]
isGrowing = s > s[1]
ud = isEqual ?
0 :
isGrowing ?
(nz(ud[1]) <= 0 ?
1 :
nz(ud[1])+1) :
(nz(ud[1]) >= 0 ?
-1 :
nz(ud[1])-1)
您可以在封装行中使用注释:
//@version=5
indicator("")
c = open > close ? color.red :
high > high[1] ? color.lime : // 注释
low < low[1] ? color.blue : color.black
bgcolor(c)
编译器注释
编译器注释是为脚本发出特殊指令的注释:
· ·//@version= 指定编译器将使用的 PineScript™ 版本。此注释中的版本号不应与脚本的修订版本号混淆,修订版本号随代码的每次保存更改而更新。
· ·//@description 为使用 library() 声明语句的脚本设置自定义描述。
· ·//@function, //@param 和 //@returns 为用户定义函数、其参数和结果添加自定义描述,并置于函数声明之上。
· ·//@type 和 //@field 为用户定义类型(UDT)及其字段添加自定义描述(在类型声明上方)。
· ·//@variable 为变量添加自定义描述(在变量声明上方)。
· ·//@strategy_alert_message 为策略提供默认信息,用在警报创建对话框中预先填写"信息"字段。
· ·//#region 和 //#endregion一起使用,可在Pine编辑器中创建可折叠的代码区域。点击//#region旁边的下拉箭头,可折叠两个注释之间的代码行。
该脚本使用图表上交互选择的三个点绘制了一个矩形。它说明了如何使用编译器注释:
//@version=5
indicator("Triangle", "", true)
int TIME_DEFAULT = 0
float PRICE_DEFAULT = 0.0
x1Input = input.time(TIME_DEFAULT, "Point 1", inline = "1", confirm = true)
y1Input = input.price(PRICE_DEFAULT, "", inline = "1", tooltip = "Pick point 1", confirm = true)
x2Input = input.time(TIME_DEFAULT, "Point 2", inline = "2", confirm = true)
y2Input = input.price(PRICE_DEFAULT, "", inline = "2", tooltip = "Pick point 2", confirm = true)
x3Input = input.time(TIME_DEFAULT, "Point 3", inline = "3", confirm = true)
y3Input = input.price(PRICE_DEFAULT, "", inline = "3", tooltip = "Pick point 3", confirm = true)
// @type 用于表示绘制三角形的坐标和颜色。
// @字段 time1 第一个点的时间。
// @字段 time2 第二点的时间。
// @字段 time3 第三点的时间。
// @field price1 第一个点的价格。
// @字段 price2 第二点的价格。
// @field price3 第三点的价格。
// @字段 lineColor 用于绘制三角形线条的颜色。
type Triangle
int time1
int time2
int time3
float price1
float price2
float price3
color lineColor
//@function 使用 `t` 对象的坐标绘制三角形。
//@param t (Triangle) 表示要绘制的三角形的对象。
//@returns 最后绘制线条的 ID。
drawTriangle(Triangle t) =>
line.new(t.time1, t.price1, t.time2, t.price2, xloc = xloc.bar_time, color = t.lineColor)
line.new(t.time2, t.price2, t.time3, t.price3, xloc = xloc.bar_time, color = t.lineColor)
line.new(t.time1, t.price1, t.time3, t.price3, xloc = xloc.bar_time, color = t.lineColor)
// 只在最后一个历史K线上绘制一次三角形.
if barstate.islastconfirmedhistory
//@variable 用于保存要绘制的三角形对象.
Triangle triangle = Triangle.new()
triangle.time1 := x1Input
triangle.time2 := x2Input
triangle.time3 := x3Input
triangle.price1 := y1Input
triangle.price2 := y2Input
triangle.price3 := y3Input
triangle.lineColor := color.purple
drawTriangle(triangle)
标示符
标识符是用户定义的变量和函数的名称:
l 必须以大写字母 (A-Z) 或小写字母 (a-z) 或下划线 (_) 开头。
l 接下来的字符可以是字母、下划线或数字(0-9)。
l 它们区分大小写。
下面是一些示例:
myVar
_myVar
my123Var
functionName
MAX_LEN
max_len
maxLen
3barsDown // 无效!
《Pine Script® 样式指南》建议常量使用大写字母的蛇形拼写法(SNAKE_CASE),其他标识符使用骆驼拼写法(camelCASE):
GREEN_COLOR = #4CAF50
MAX_LOOKBACK = 100
int fastLength = 7
// 如果参数为 "true",则返回 1;如果为 "false "或 "na",则返回 0。
zeroOne(boolValue) => boolValue ? 1 : 0
运算符
运算符简介
某些运算符用于构建返回结果的表达式:
l 算术运算符
l 比较运算符
l 逻辑运算符
l ?:三元运算符
l []历史引用运算符
其他运算符用于为变量赋值:
l ·= 用于为变量赋值,但仅限于声明变量时(第一次使用时)。
l ·:= 用于为先前声明的变量赋值。下列运算符也可以这样使用: +=, -=, *=, /=, %=
正如 "类型系统 "页面所述,形式和类型在决定表达式产生的结果类型方面起着至关重要的作用。这反过来又会影响到如何使用这些结果以及使用哪些函数。表达式总是返回表达式中使用的最强形式,例如,如果将"input int"与"series int"相乘,表达式将产生一个"series int"结果,而这个结果不能用作ta.ema()中length的参数。
该脚本将产生编译错误:
//@version=5
indicator("")
lenInput = input.int(14, "Length")
factor = year > 2020 ? 3 : 1
adjustedLength = lenInput * factor
ma = ta.ema(close, adjustedLength) // Compilation error!编译错误!
plot(ma)
编译器会报错:无法调用ta.ema的参数‘length’=adjustedLength,这里我们期望使用simple int类型的参数,但却使用了series int。因为lenInput是一个“input int”类型,而factor是一个“series int”类型(只能通过查看每个K线上的year值来确定)。因此,变量adjustedLength被赋值为“series int”。我们的问题是,ta.ema()的参考手册条目告诉我们,它的length参数需要“simple”形式的值,而"simple"形式比"series"形式更弱,因此“series int”值是不允许的。
解决这个难题需要:
l 使用另一个移动平均函数,支持“series int”长度,如ta.sma(),或
l 不使用计算生成“series int”值的长度。
Pine Script® 中有五个算术运算符:
+ | 加法和字符串连接 |
- | 减法 |
* | 乘法 |
/ | 除法 |
% | 模数(除法后的余数) |
上述算术运算符都是二元运算符(表示它们需要两个操作数或值来运算,如 1 + 2)。+ 和 - 同时也是一元运算符(意味着它们只对一个操作数起作用,如 -1 或 +1)。
如果两个操作数都是数字,但其中至少有一个是浮点型,那么结果也将是浮点型。如果两个操作数都是 int 类型,结果也将是一个 int。如果至少一个操作数是 na,结果也是 na。
+ 运算符也是字符串的连接运算符。 "EUR "+"USD" 得到 "EURUSD "字符串。
%运算符通过将商舍入到可能的最小值来计算模数。下面是一个简单的示例,说明模数是如何在幕后计算的:
//@version=5
indicator("Modulo function")
modulo(series int a, series int b) =>
a - b * math.floor(nz(a/b))
plot(modulo(-1, 100))
比较运算符
Pine Script® 中有六个比较运算符::
< | 小于 |
<= | 小于或等于 |
!= | 不相等 |
== | 相等 |
> | 大于 |
>= | 大于或等于 |
比较运算是二元的。如果两个操作数都是数值,结果将是 bool 类型,即 true、false 或 na。
示例:
1 > 2 // false
1 != 1 // false
close >= open // 取决于 "关闭 "和 "打开 "的值
逻辑运算符
not | 否定 |
and | 逻辑与 |
or | 逻辑或 |
Pine Script®中有三种逻辑运算符:
not运算符是一元运算符。当应用于true值时,操作结果返回false,反之亦然。
and运算符真值表:
a | b | a and b |
true | true | true |
true | false | false |
false | true | false |
false | false | false |
or 运算符真值表:
a | b | a or b |
true | true | true |
true | false | true |
false | true | true |
false | false | false |
?:三元运算符
?: 三元运算符可以创建如下形式的表达式:
condition ? valueWhenConditionIsTrue : valueWhenConditionIsFalse
三元运算符返回的结果取决于条件的值。如果条件为真,则返回valueWhenConditionIsTrue。如果条件为false或na,则返回valueWhenConditionIsFalse。
三元表达式的组合可以达到与 switch 结构相同的效果,例如:
timeframe.isintraday ? color.red : timeframe.isdaily ? color.green : timeframe.ismonthly ? color.blue : na
示例从左到右计算:
u 如果timeframe.isintraday为true,则返回color.red。如果为假,则评估timeframe.isdaily。
u 如果timeframe.isdaily为true,则返回color.green。如果为假,则评估timeframe.isdaily。
u 如果 timeframe.ismonthly 为 true,则返回 color.blue,否则返回 na。
请注意:两边的返回值是表达式,而不是局部块,因此不会影响每个作用域500个局部块的限制。
[]历史引用运算符
使用[]history-referencing操作符可以引用时间序列过去的值。过去值是变量在脚本当前执行的K线(当前K线)之前的K线上的值。有关在K线上执行脚本的更多信息,请参阅执行模型页面。
[]操作符用于变量、表达式或函数之后。操作符方括号内的值是我们要引用的过去偏移量。要引用距离当前K线两个K线以外的volume内置变量的值,可以使用volume[2]。
由于序列是动态增长的,当脚本在连续的K线上移动时,与运算符一起使用的偏移量将指向不同的K线。让我们来看看相同偏移量返回的值是如何动态变化的,以及为什么数列与数组截然不同。在Pine Script®中,close变量或close[0](与之相当)保存着当前K线的"收盘价"。如果你的代码现在在数据集(图表上所有K线的集合)的第三条K线上执行,close将包含该条K线的收盘价,close[1]将包含前一条K线(数据集的第二条K线)的收盘价,close[2]则是第一条K线的收盘价。close[3]将返回na,因为该位置不存在K线,因此它的值不可用。
当对数据集中的第4个K线执行相同的代码时,close将包含该K线的收盘价,而代码中使用的相同close[1]将指向数据集中第3个K线的“收盘价”。数据集中第一个K线的结束位置现在是close[3],而这次close[4]将返回na。
在Pine Script®运行时环境中,由于您的代码对数据集中的每个历史K线执行一次,从图表的左侧开始,Pine Script®在索引0处添加系列中的新元素,并将系列1索引中现有的元素进一步推开。相比之下,数组的大小可以是常量,也可以是可变的,而且它们的内容或索引结构不会被运行时环境修改。因此,Pine Script®系列与数组非常不同,只能通过它们的索引语法来熟悉它们。
当图表中交易品种的市场处于开放状态,且脚本在图表的最后一个K线(即实时K线)上执行时,close 返回当前交易价格。只有当该K线收盘、该实时K线上最后一次执行脚本时,它将包含实际收盘价。
Pine Script® 有一个变量,包含脚本执行时的K线编号:bar_index。在第一个K线上,bar_index 等于 0,脚本每执行一个K线,bar_index 就增加 1。在最后一个K线上,bar_index 等于数据集中K线的数量减去 1。
在 Pine Script® 中使用 [] 运算符时,还有一个重要的注意事项。na代表的不是一个数字,在任何表达式中使用它都会产生一个结果na(类似于NaN)。这种情况通常发生在数据集早期K线的脚本计算过程中,但在某些条件下也可能发生在后面的K线中。如果您的代码没有明确规定如何处理这些特殊情况,就会在脚本计算中引入无效结果,并一直波及到实时K线。na 和 nz 函数就是为了处理这些情况而设计的。
这些都是 [] 操作符的有效用法:
high[10]
ta.sma(close, 10)[1]
ta.highest(high, 10)[20]
close > nz(close[1], open)
请注意,[]操作符只能在同一个值上使用一次。这是不允许的:
close[1][2] // 错误: 错误使用 [] 操作符
运算符优先级
运算顺序由运算符的优先级决定。优先级高的运算符优先计算。以下是按优先级递减排序的运算符列表:
Precedence | Operator |
9 | [] |
8 | 一元+, 一元-, not |
7 | *, /, % |
6 | +, - |
5 | >, <, >=, <= |
4 | ==, != |
3 | and |
2 | or |
1 | ?: |
如果一个表达式中有多个具有相同优先级的运算符,那么它们将从左到右依次计算。
如果表达式的计算顺序与优先级要求的不同,则可以用括号将表达式的各个部分组合在一起。
= 运算符用于在变量初始化或声明时(即第一次使用时)对其进行赋值。它表示这是我要使用的一个新变量,我希望它在每个K线上都以这个值开始。
这些都是有效的变量声明:
i = 1
MS_IN_ONE_MINUTE = 1000 * 60
showPlotInput = input.bool(true, "Show plots")
pHi = pivothigh(5, 5)
plotColor = color.green
有关如何声明变量的更多信息,请参阅变量声明页面。
`:=` 重赋值操作符
:= 用于为现有变量重新赋值。它表示使用脚本中先前声明的这个变量,并赋予它一个新值。
先前声明过,然后使用 := 重新赋值的变量称为可变变量。以下所有示例都是有效的变量重新赋值。有关 var 如何工作的更多信息,请参阅 `var` 声明模式一节:
//@version=5
indicator("", "", true)
//仅在第一条K线上 声明并初始化 `pHi`.
var float pHi = na
// 对`pHi`重新赋值
pHi := nz(ta.pivothigh(5, 5), pHi)
plot(pHi)
请注意:
l 我们用以下代码声明pHi:var float pHi = na。var关键字告诉Pine Script®,我们只希望在数据集的第一个K线上用na初始化该变量。float关键字告诉编译器,我们要声明一个类型为"float"的变量。这是必要的,因为与大多数情况相反,编译器无法自动判断 = 符号右侧值的类型。
l 虽然因为它使用了var,变量声明只在第一个K线上执行,但pHi := nz(ta.pivothigh(5, 5), pHi)行将在图表的所有K线上执行。在每个K线上,它都会评估pivothigh()调用是否返回na,因为当函数没有找到新的枢轴时,它就会这样做。nz()函数就是执行"检查na"部分的函数。当它的第一个参数(ta.pivothigh(5, 5))为na时,它会返回第二个参数(pHi),而不是第一个参数。当pivothigh()返回发现新枢轴的价格点时,该值将赋值给pHi。当没有找到新的枢轴而返回 na 时,我们会将pHi以前的值赋值给它自己,实际上是保留它以前的值。
我们的脚本输出如下:
请注意:
l 在找到新的枢轴之前,该线保留其先前的值。
l 枢轴是在枢轴实际出现五格后检测到的,因为我们的 ta.pivothigh(5,5)调用表明,我们需要在高点两侧有五个较低的高点才能将其检测为枢轴。
有关如何为变量重新赋值的更多信息,请参阅变量重新赋值部分。
变量是保存值的标识符。在使用之前,必须在代码中声明变量。变量声明的语法如下:
[<declaration_mode>] [<type>] <identifier> = <expression> | <structure>
or
<tuple_declaration> = <function_call> | <structure>
其中:
l | 表示 "或",方括号([])中的部分可以出现 0 次或 1 次。
l ·<declaration_mode> 是变量的声明模式。可以是 var 或 varip,也可以什么都不是。
l ·<type> 是可选项,与几乎所有 Pine Script® 变量的声明一样(参见类型)。
l ·<identifier> 是变量的名称。
l ·<expression> 可以是文字、变量、表达式或函数调用。
l ·<structure> 可以是 if、for、while 或 switch 结构。
l ·<tuple_declaration> 是以逗号分隔的变量名列表,用方括号([])括起来,例如 [ma、upperBand、lowerBand]。
这些都是有效的变量声明。最后一个需要四行:
BULL_COLOR = color.lime
i = 1
len = input(20, "Length")
float f = 10.5
closeRoundedToTick = math.round_to_mintick(close)
st = ta.supertrend(4, 14)
var barRange = float(na)
var firstBarOpen = open
varip float lastClose = na
[macdLine, signalLine, histLine] = ta.macd(close, 12, 26, 9)
plotColor = if close > open
color.green
else
color.red
注意:
上述语句都包含 = 赋值操作符,因为它们都是变量声明。当你看到使用 := 重赋值操作符的类似行时,代码正在将一个值重新赋值给一个已经声明的变量。这就是变量重赋值。请务必理解其中的区别,因为这是Pine Script®新手的常见绊脚石。详情请参阅下一节的变量重新赋值。
变量声明的正式语法是:
<variable_declaration>
[<declaration_mode>] [<type>] <identifier> = <expression> | <structure> | <tuple_declaration> = <function_call> | <structure>
<declaration_mode>
var | varip
<type>
int | float | bool | color | string | line | linefill | label | box | table | array<type> | matrix<type> | UDF
使用 `na` 进行初始化
在大多数情况下,显式类型声明是多余的,因为在编译时,类型会自动从 = 右边的值推断出来,所以是否使用显式类型声明往往是一个偏好问题。例如:
baseLine0 = na // 编译时错误!
float baseLine1 = na // OK
baseLine2 = float(na) // OK
在示例的第一行中,编译器无法确定 baseLine0 变量的类型,因为 na 是一个没有特定类型的通用值。baseLine1 变量的声明是正确的,因为它明确声明了 float 类型。baseLine2 变量的声明也是正确的,因为它的类型可以从表达式 float(na) 中导出,表达式 float(na) 是将 na 值显式地转换为 float 类型。baseLine1 和 baseLine2 的声明是等价的。
元组声明
函数调用或结构类型允许返回多个值。当我们调用它们并希望存储它们返回的值时,必须使用元组声明,即用逗号分隔的一组或一组以上的值,并用括号括起来。这样我们就可以同时声明多个变量。例如,用于布林带的 ta.bb() 内置函数会返回三个值:
[bbMiddle, bbUpper, bbLower] = ta.bb(close, 5, 4)
变量重赋值是使用 := 重赋值操作符完成的。只有在首次声明变量并赋予其初始值后才能进行。在计算中经常需要为变量重新赋值,当必须在结构的局部块中为全局作用域中的变量赋值时,就必须这样做,例如:
//@version=5
indicator("", "", true)
sensitivityInput = input.int(2, "Sensitivity", minval = 1, tooltip = "数值越大,对颜色变化的敏感度越低.")
ma = ta.sma(close, 20)
maUp = ta.rising(ma, sensitivityInput)
maDn = ta.falling(ma, sensitivityInput)
// 只在第一条K线初始化color, 赋值 gray
var maColor = color.gray
if maUp
// MA 上升或2条K线齐平,颜色重新赋值为lime.
maColor := color.lime
else if maDn
// MA 下降或2条K线齐平,颜色重新赋值为fuchsia.
maColor := color.fuchsia
plot(ma, "MA", maColor, 2)
l 我们仅在第一个K线上初始化 maColor,因此它的值在不同K线之间保持不变。
l 在每个K线中,if 语句都会检查 MA 是否在用户指定的K线数量(默认为 2)内一直上升或下降。当出现这种情况时,必须在 if 局部块中重新为 maColor 赋值。为此,我们使用 := 重新分配操作符。
l 如果我们不使用 := 重分配操作符,结果将是初始化一个新的 maColor 局部变量,它的名称与全局作用域的名称相同,但实际上是一个非常令人困惑的独立实体,只在局部块的范围内存在,然后消失得无影无踪。
Pine Script® 中的所有用户定义变量都是可变的,这意味着可以使用 := 重赋值操作符来改变它们的值。为变量赋值可能会改变变量的形式(更多信息请参见 Pine Script® 类型系统页面)。在一个K线上执行脚本时,变量可以根据需要被多次赋值,因此一个脚本可以包含任意数量的变量重赋值。变量的声明模式决定了如何保存分配给变量的新值。
声明模式
要理解声明模式对变量行为的影响,需要事先了解 Pine Script® 的执行模式。
当你声明一个变量时,如果指定了声明模式,那么必须先声明模式。可以使用三种模式:
l ·"在每个K线上",当没有指定时
l ·var
l ·varip
在每一条K线上
如果没有指定明确的声明模式,即没有使用 var 或 varip 关键字,变量将在每一条K线上进行声明和初始化,例如本页介绍中第一组示例中的以下声明:
BULL_COLOR = color.lime
i = 1
len = input(20, "Length")
float f = 10.5
closeRoundedToTick = math.round_to_mintick(close)
st = ta.supertrend(4, 14)
[macdLine, signalLine, histLine] = ta.macd(close, 12, 26, 9)
plotColor = if close > open
color.green
else
color.red
var
使用 var 关键字时,变量只被初始化一次,如果声明是在全局范围内,则在第一条K线时初始化;如果声明是在局部代码块内,则在局部代码块第一次执行时初始化。之后,它将在连续的K线中保持上次的值,直到我们为其重新赋值。在许多情况下,变量的值必须在脚本迭代的连续K线中保持不变,这种行为非常有用。例如,假设我们要计算图表中绿色K线的数量:
//@version=5
indicator("Green Bars Count")
var count = 0
isGreen = close >= open
if isGreen
count := count + 1
plot(count)
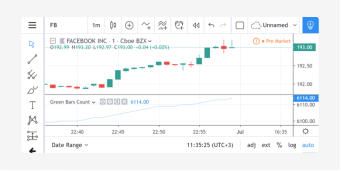
如果没有 var 修饰符,每次新的K线更新触发脚本重新计算时,变量计数就会重置为零(从而失去其值)。
只在第一个K线上声明变量通常有助于更有效地管理绘图。假设我们想将上一K线的收盘线延伸到右侧图表的右边。我们可以这样写:
//@version=5
indicator("Inefficient version", "", true)
closeLine = line.new(bar_index - 1, close, bar_index, close, extend = extend.right, width = 3)
line.delete(closeLine[1])
但这样做效率很低,因为我们要在每个历史K线和实时K线的每次更新中创建和删除该行。使用这种方法效率更高:
//@version=5
indicator("Efficient version", "", true)
var closeLine = line.new(bar_index - 1, close, bar_index, close, extend = extend.right, width = 3)
if barstate.islast
line.set_xy1(closeLine, bar_index - 1, close)
line.set_xy2(closeLine, bar_index, close)
l 我们仅在第一条K线上使用var声明模式初始化closeLine。
l 我们将更新行的代码封装在 if barstate.islast 结构中,从而将其余代码的执行时间限制在图表的最后一个K线上。
使用 var 声明模式在性能上会有很小的影响。因此,在声明常量时,如果考虑到性能问题,最好不要使用 var,除非初始化涉及的计算时间超过了维护惩罚的时间,例如具有复杂代码或字符串操作的函数。
varip
要理解使用 varip 声明模式的变量的行为,需要事先了解 Pine Script® 的执行模型和K线状态。
varip 关键字可以用来声明回滚过程的变量,这在 Pine Script® 的执行模式页面有详细解释。
脚本只在历史K线收盘时执行一次,而当脚本在实时状态下运行时,每当图表馈送检测到价格或成交量更新时,脚本就会执行一次。在每次实时更新时,Pine Script® 的运行时通常会将脚本变量的值重置为上次的提交值,即上一K线收盘时的值。这通常很方便,因为每次实时脚本执行都是从一个已知状态开始的,从而简化了脚本逻辑。
但有时,脚本逻辑要求代码能够在实时K线的不同执行时保存变量值。使用 varip 声明变量就可以做到这一点。varip中的"ip"代表K线内不变。
让我们看看下面这段没有使用 varip 的代码:
//@version=5
indicator("")
int updateNo = na
if barstate.isnew
updateNo := 1
else
updateNo := updateNo + 1
plot(updateNo, style = plot.style_circles)
在历史K线中,barstate.isnew始终为真,图形显示值为"1",if结构的else部分从未执行过。在实时K线上,只有当脚本在K线的"open"位置首次执行时,barstate.isnew才为真。随后,图形将短暂显示"1",直到后续执行发生。在实时K线的下一次执行中,if语句的第二个分支将被执行,因为barstate.isnew不再为真。由于updateNo在每次执行时都被初始化为na,因此updateNo + 1表达式的结果是na,所以在脚本的后续实时执行中不会绘制任何图形。
如果使用 varip 来声明updateNo变量,脚本行为截然不同:
//@version=5
indicator("")
varip int updateNo = na
if barstate.isnew
updateNo := 1
else
updateNo := updateNo + 1
plot(updateNo, style = plot.style_circles)
现在的区别在于,updateNo 会追踪每个实时K线的实时更新次数。之所以会出现这种情况,是因为 varip 声明允许 updateNo 的值在每次实时更新之间保持不变;在每次实时执行脚本时,它不再回滚。对 barstate.isnew 的测试允许我们在出现新的实时K线时重置更新计数。
由于 varip 只影响代码在实时K线中的行为,因此使用基于 varip变量的逻辑设计的策略的回溯测试结果将无法在历史K线中重现该行为,这将导致在历史K线中的测试结果无效。这也意味着在历史K线上绘制的图形将无法再现脚本在实时K线上的行为。
条件结构简介
Pine Script® 中的条件结构是 if 和 switch。它们可以用于
l 用于它们的副作用,即:当它们不返回值但做一些事情,比如重新赋值给变量或调用函数。
l 返回一个值或一个元组,然后将其赋值给一个(或多个)变量。
条件结构中,可以被嵌入像 for 和 while等语句;你可以在其他结构中使用 if 或 switch。
有些 Pine Script® 内置函数不能在条件结构的局部块中调用。它们是:alertcondition()、barcolor()、fill()、hline()、indicator()、library()、plot()、plotbar()、plotcandle()、plotchar()、plotshape()、strategy()。这并不意味着它们的功能不能通过脚本评估的条件来控制,只是不能通过将它们包含在条件结构中来实现。请注意,虽然局部代码块中允许调用 input*.() 函数,但它们的功能与脚本全局范围中的功能相同。
条件结构中的局部代码块必须缩进四个空格或一个制表符。
`if` 结构
1.用于其副作用的 `if` 结构
用于产生副作用的 if 结构的语法如下:
if <expression>
<local_block>
{else if <expression>
<local_block>}
[else
<local_block>]
其中:
l 方括号([])中的部分可以出现 0 次或 1 次,而大括号({})中的部分可以出现 0 次或多次。
l <expression> 必须是 "bool "类型或可自动转换为该类型,只有 "int "或 "float "值才可能自动转换为该类型(请参阅类型系统页面)。
l <local_block> 由零个或多个语句组成,后面跟一个返回值,返回值可以是元组值。它必须缩进四个空格或一个制表符。
l 可以有零个或多个 else if 子句。
l 可以有零个或一个 else 子句。
当 if 后面的 <表达式>求值为 true 时,将执行第一个局部代码块,结束 if 结构的执行,并返回局部代码块末尾的求值。
如果if后面的<expression>值为false,则会对连续的else if子句(如果有)进行求值。如果其中一个子句的<表达式>的值为真,则执行其局部代码块,结束if结构的执行,并返回局部代码块末尾的值。
当没有 <表达式> 的值为 true 且存在 else 子句时,将执行其局部代码块,结束 if 结构的执行,并返回局部代码块末尾的值。
如果没有<表达式>求值为true且不存在else子句,则返回na。
例如,策略中可以使用 if 结构的副作用帮助管理订单流。虽然在 strategy.*() 调用中使用 when 参数通常也能实现相同的功能,但使用 if 结构的代码更易于阅读:
if (ta.crossover(source, lower))
strategy.entry("BBandLE", strategy.long, stop=lower,
oca_name="BollingerBands",
oca_type=strategy.oca.cancel, comment="BBandLE")
else
strategy.cancel(id="BBandLE")
使用 if 结构可以将代码的执行限制在特定的K线中,就像我们这里所做的那样,将标签的更新限制在图表的最后一个K线中:
indicator("", "", true)
var ourLabel = label.new(bar_index, na, na, color = color(na), textcolor = color.orange)
if barstate.islast
label.set_xy(ourLabel, bar_index + 2, hl2[1])
label.set_text(ourLabel, str.tostring(bar_index + 1, "# bars in chart"))
请注意:
l 仅在第一个K线上初始化ourLabel变量,因为我们使用的是var声明模式。初始化变量的值由label.new()函数调用提供,该函数返回一个指向其创建的标签的label ID。我们使用该调用来设置标签的属性,因为一旦设置,这些属性就会一直存在,直到我们进行更改。
l 接下来,Pine Script®运行时将跳过对ourLabel的初始化,并对if的条件(barstate.islast)进行评估。在最后一个K线之前的所有K线上,都返回"false",因此在首K线之后的大多数历史K线上都不会做任何操作。
l 在最后一个K线上,barstate.islast变为true,然后执行结构的局部块,在每个K线上修改更新标签的属性,标签显示数据集中的K线数量。
l 我们希望在没有背景色的情况下显示标签的文本,因此在调用label.new()函数时将标签的背景设置为na,并使用hl2[1]作为标签的y位置,因为我们不希望标签一直移动。通过使用上一栏的最高值和最低值的平均值,直到下一个实时栏打开时,标签才会移动。
l 我们在label.set_xy()调用中使用bar_index + 2,将标签向右偏移两格。
2.用于返回值的 if
用于返回一个或多个值的 if 结构的语法如下:
[<declaration_mode>] [<type>] <identifier> = if <expression>
<local_block>
{else if <expression>
<local_block>}
[else
<local_block>]
其中:
l 方括号([])中的部分可以出现 0 次或 1 次,大括号({})中的部分可以出现 0 次或多次。
l <declaration_mode> 是变量的声明模式
l <type> 是可选项,与几乎所有 Pine Script® 变量的声明一样(参见类型)
l <identifier> 是变量的名称
l <expression> 可以是文字、变量、表达式或函数调用。
l <local_block> 由零个或多个语句组成,后面跟一个返回值,返回值可以是一个数值元组。它必须缩进四个空格或一个制表符。
l 分配给变量的值是 <local_block> 的返回值,如果没有执行局部代码块,则为 na。
下面是一个示例:
//@version=5
indicator("", "", true)
string barState = if barstate.islastconfirmedhistory
"islastconfirmedhistory"
else if barstate.isnew
"isnew"
else if barstate.isrealtime
"isrealtime"
else
"other"
f_print(_text) =>
var table _t = table.new(position.middle_right, 1, 1)
table.cell(_t, 0, 0, _text, bgcolor = color.yellow)
f_print(barState)
也可以省略 else 块。在这种情况下,如果条件为 false,将向 var_declarationX 变量分配一个空值(na、false 或"")。
下面的示例显示了在不执行局部代码块时如何返回 na。如果 close > open 为 false,则返回 na:
x = if close > open
close
脚本可以包含嵌套 if 结构和其他条件结构。例如:
if condition1
if condition2
if condition3
expression
不过,从性能角度考虑,不建议嵌套这些结构。在可能的情况下,通常用多个逻辑运算符组成一个 if 语句比用多个嵌套 if 块更为理想:
if condition1 and condition2 and condition3
expression
switch结构有两种形式。一种是切换键表达式的不同值:
[[<declaration_mode>] [<type>] <identifier> = ]switch <expression>
{<expression> => <local_block>}
=> <local_block>
另一种形式不使用表达式作为键,而是基于不同表达式的评估进行切换:
[[<declaration_mode>] [<type>] <identifier> = ]switch
{<expression> => <local_block>}
=> <local_block>
l 方括号([])中的部分可以出现 0 次或 1 次,大括号({})中的部分可以出现 0 次或多次。
l <declaration_mode> 是变量的声明模式
l <type> 是可选项,与所有变量的声明一样(参见类型)
l <identifier> 是变量的名称
l <expression> 可以是文字、变量、表达式或函数调用。
l <local_block> 由零个或多个语句组成,后面跟一个返回值,返回值可以是一个数值元组。它必须缩进四个空格或一个制表符。
l 分配给变量的值是 <local_block> 的返回值,如果没有执行局部代码块,则为 na。
l 结尾处的 => <local_block>允许您指定一个返回值,作为默认值,在不执行结构中的其他情况下使用。
一个switch结构只执行一个局部块。它是一个结构化的开关,不会在不同情况下切换。因此,没有必要使用break语句。
两种形式都可以作为变量的初始化值。
与if结构一样,如果没有执行局部代码块,则返回na。
下面我们来看一个使用表达式进行切换的示例:
//@version=5
indicator("Switch using an expression", "", true)
string maType = input.string("EMA", "MA type", options = ["EMA", "SMA", "RMA", "WMA"])
int maLength = input.int(10, "MA length", minval = 2)
float ma = switch maType
"EMA" => ta.ema(close, maLength)
"SMA" => ta.sma(close, maLength)
"RMA" => ta.rma(close, maLength)
"WMA" => ta.wma(close, maLength)
=>
runtime.error("No matching MA type found.")
float(na)
plot(ma)
请注意:
l 我们切换的表达式是变量maType,它属于" input int"类型(有关"input"形式的解释,请参见此处)。由于它在脚本执行期间不会改变,这就保证了用户选择的 MA 类型将在每个K线上执行,这也是 ta.ema() 等函数的要求,因为这些函数的长度参数需要一个 "simple int "参数。
l 如果没有找到与maType匹配的值,开关将执行由=>引入的最后一个局部代码块,该代码块起着承上启下的作用。我们会在该代码块中生成运行时错误。我们还用float(na)结束它,这样局部代码块返回的值的类型就与结构中其他局部代码块的类型兼容,以避免编译错误。
这是一个不使用表达式的 switch 结构示例:
//@version=5
strategy("Switch without an expression", "", true)
bool longCondition = ta.crossover( ta.sma(close, 14), ta.sma(close, 28))
bool shortCondition = ta.crossunder(ta.sma(close, 14), ta.sma(close, 28))
switch
longCondition => strategy.entry("Long ID", strategy.long)
shortCondition => strategy.entry("Short ID", strategy.short)
l switch根据longCondition或shortCondition "bool "变量是否为真来选择适当的策略顺序。·
l longCondition和shortCondition 的构建条件是排他的。它们可以同时为假,但不能同时为真。因此,switch 结构中只有一个局部块被执行这一事实对我们来说并不重要。
l 在进入switch结构之前,我们会评估对ta.crossover()和 ta.crossunder()的调用。如果不这样做(如下面的示例),就无法在每个K线上执行这些函数,这将导致编译器警告和不稳定的行为:
//@version=5
strategy("Switch without an expression", "", true)
switch
// 编译器警告!无法正确计算!
ta.crossover( ta.sma(close, 14), ta.sma(close, 28)) => strategy.entry("Long ID", strategy.long)
ta.crossunder(ta.sma(close, 14), ta.sma(close, 28)) => strategy.entry("Short ID", strategy.short)
匹配本地块类型要求
在结构体中使用多个局部块时,其所有局部块的返回值类型必须匹配。这仅适用于结构体用于在声明中为变量赋值的情况,因为变量只能有一种类型,如果语句在其分支中返回两种不兼容的类型,则无法正确确定变量类型。如果结构体没有在任何地方赋值,其分支就会返回不同的值。
这段代码可以正常编译,因为close和open都是float类型:
x = if close > open
close
else
open
这段代码无法编译,因为第一个局部代码块返回的是浮点数值,而第二个局部代码块返回的是字符串,并且 if 语句的结果被赋值给了 x 变量:
// Compilation error!
x = if close > open
close
else
"open"
循环语句
简介
不需要循环时
Pine Script®的运行时和内置函数在很多情况下都不需要循环。对Pine Script®运行时和内置函数还不熟悉的Pine Script®新手程序员,如果想计算最近10个收盘值的平均值,通常会编写如下代码:
//@version=5
indicator("Inefficient MA", "", true)
MA_LENGTH = 10
sumOfCloses = 0.0
for offset = 0 to MA_LENGTH - 1
sumOfCloses := sumOfCloses + close[offset]
inefficientMA = sumOfCloses / MA_LENGTH
plot(inefficientMA)
在 Pine 中完成这样的任务时,for 循环是不必要的,也是低效的。应该这样做:这段代码不使用循环,而是使用 ta.sma() 内置函数来完成任务,因此更简短,运行速度也更快:
//@version=5
indicator("Efficient MA", "", true)
thePineMA = ta.sma(close, 10)
plot(thePineMA)
计算最后几个K线中出现的事件也是一项任务,初学 Pine Script® 的程序员通常认为必须用循环来完成。要计算最后 10 个K线中的上涨K线数,他们会使用:
//@version=5
indicator("Inefficient sum")
MA_LENGTH = 10
upBars = 0.0
for offset = 0 to MA_LENGTH - 1
if close[offset] > open[offset]
upBars := upBars + 1
plot(upBars)
在 Pine 中高效的写法是使用 math.sum() 内置函数来完成这项任务(对于程序员来说,因为这样可以节省时间,实现最快的图表加载速度,并最公平地共享我们的公共资源):
//@version=5
indicator("Efficient sum")
upBars = math.sum(close > open ? 1 : 0, 10)
plot(upBars)
这里发生了什么:
l 使用 ?: 三元运算符建立一个表达式,在上涨K线中产生 1,在其他K线中产生 0。
l 我们使用内置函数 math.sum(),对过去 10 个K线的该值进行连续求和。
需要循环时
循环的存在是有道理的,因为即使在 Pine Script® 中,循环在某些情况下也是必要的。这些情况通常包括
l 对集合(数组、矩阵和地图)的操作。
l 回溯历史,使用只能在当前K线中获知的参考值分析K线,例如,找出有多少个过去的高点高于当前K线的高点。由于当前K线的高点只能在脚本运行的K线上获知,因此需要一个循环来回溯历史并分析过去的K线。
l 对过去的K线进行计算,而这些计算无法使用内置函数完成。
for
for 结构允许使用计数器重复执行语句。其语法如下:
[[<declaration_mode>] [<type>] <identifier> = ]for <identifier> = <expression> to <expression>[ by <expression>]
<local_block_loop>
其中:
l 方括号([])中的部分可以出现 0 次或 1 次,大括号({})中的部分可以出现 0 次或多次。
l <declaration_mode> 是变量的声明模式
l <type> 是可选项,与几乎所有 Pine Script® 变量声明一样(参见类型)
l <identifier> 是变量的名称
l <expression> 可以是文字、变量、表达式或函数调用。
l <local_block_loop> 由零个或多个语句组成,后面跟一个返回值,返回值可以是一个数值元组。它必须缩进四个空格或一个制表符。它可以包含用于退出循环的 break 语句,或用于退出当前迭代并继续下一个迭代的 continue 语句。
l 分配给变量的值是 <local_block_loop> 的返回值,即循环最后一次迭代计算出的最后一个值,如果循环未执行,则为返回 na。
l <identifier> 中的标识符是循环的计数器初始值。
l =<expression>中的表达式是计数器的起始值。
l 中的表达式 to <expression> 是计数器的结束值。 只有在进入循环时才对其进行求值。
l 表达式 in by <expression> 是可选项。它是循环计数器在循环的每次迭代中增加或减少的步长。当起始值 < 终止值时,其默认值为 1。当起始值 > 终止值时,默认值为-1。默认使用的步长(+1 或-1)由起始值和结束值决定。
本例使用 for 语句回溯用户定义的K线数量,以确定有多少K线的高点高于或低于图表中最后一个K线的高点。由于脚本只能访问图表最后一个K线的参考值,因此这里必须使用 for 循环。由于脚本是逐条执行的,因此无法使用 Pine Script® 的运行时进行即时计算:
indicator("`for` loop")
lookbackInput = input.int(50, "Lookback in bars", minval = 1, maxval = 4999)
higherBars = 0
lowerBars = 0
if barstate.islast
var label lbl = label.new(na, na, "", style = label.style_label_left)
for i = 1 to lookbackInput
if high[i] > high
higherBars += 1
else if high[i] < high
lowerBars += 1
label.set_xy(lbl, bar_index, high)
label.set_text(lbl, str.tostring(higherBars, "# higher bars\n") + str.tostring(lowerBars, "# lower bars"))
下面的示例在checkLinesForBreaches()函数中使用了一个循环,以遍历枢轴线数组,并在价格越过这些线时删除它们。这时循环是必要的,必须在每个K线上检查hiPivotLines和loPivotLines数组中的所有线,而没有内置函数可以帮我们做到这一点:
MAX_LINES_COUNT = 100
indicator("枢轴线中止", "", true, max_lines_count = MAX_LINES_COUNT)
color hiPivotColorInput = input(color.new(color.lime, 0), "High pivots")
color loPivotColorInput = input(color.new(color.fuchsia, 0), "Low pivots")
int pivotLegsInput = input.int(5, "Pivot 长度")
int qtyOfPivotsInput = input.int(50, "最后记住的最大枢轴数", minval = 0, maxval = MAX_LINES_COUNT / 2)
int maxLineLengthInput = input.int(400, "以K线为单位的最大线长", minval = 2)
// —————将数组中的新元素放入队列,并将其第一个元素取出队列。
qDq(array, qtyOfElements, arrayElement) =>
array.push(array, arrayElement)
if array.size(array) > qtyOfElements
// 只有当阵列达到容量时才需要y.
array.shift(array)
// —————— 循环浏览数组线条,扩展价格未交叉的线条,删除已交叉的线条。.
checkLinesForBreaches(arrayOfLines) =>
int qtyOfLines = array.size(arrayOfLines)
// 如果没有要检查的行,就不要循环,因为此时 "to "的值将是 `na` 。.
for lineNo = 0 to (qtyOfLines > 0 ? qtyOfLines - 1 : na)
//需要检查数组大小是否仍然需要循环,因为我们可能在循环中删除了数组元素
if lineNo < array.size(arrayOfLines)
line currentLine = array.get(arrayOfLines, lineNo)
float lineLevel = line.get_price(currentLine, bar_index)
bool lineWasCrossed = math.sign(close[1] - lineLevel) != math.sign(close - lineLevel)
bool lineIsTooLong = bar_index - line.get_x1(currentLine) > maxLineLengthInput
if lineWasCrossed or lineIsTooLong
// 线条保留在图表上,但在以后的条形图中不再延伸.
array.remove(arrayOfLines, lineNo)
// 将两个本地块的类型强制为相同类型.
int(na)
else
line.set_x2(currentLine, bar_index)
int(na)
// 包含非交叉枢轴线的线段数组.
var line[] hiPivotLines = array.new_line(qtyOfPivotsInput)
var line[] loPivotLines = array.new_line(qtyOfPivotsInput)
// Detect new pivots.删除新枢轴
float hiPivot = ta.pivothigh(pivotLegsInput, pivotLegsInput)
float loPivot = ta.pivotlow(pivotLegsInput, pivotLegsInput)
// 在新枢轴上创建新线条.
if not na(hiPivot)
line newLine = line.new(bar_index[pivotLegsInput], hiPivot, bar_index, hiPivot, color = hiPivotColorInput)
line.delete(qDq(hiPivotLines, qtyOfPivotsInput, newLine))
else if not na(loPivot)
line newLine = line.new(bar_index[pivotLegsInput], loPivot, bar_index, loPivot, color = loPivotColorInput)
line.delete(qDq(loPivotLines, qtyOfPivotsInput, newLine))
// 如果价格没有越线,则延长线.
checkLinesForBreaches(hiPivotLines)
checkLinesForBreaches(loPivotLines)
while语句
while 结构允许重复执行语句,直到某个条件为假。其语法如下:
[[<declaration_mode>] [<type>] <identifier> = ]while <expression>
<local_block_loop>
其中:
l 方括号([])中的部分可以出现 0 次或 1 次。
l <declaration_mode> 是变量的声明模式
l <type> 是可选项,与几乎所有 Pine Script® 变量的声明一样(参见类型)
l <identifier> 是变量的名称
l <expression> 可以是文字、变量、表达式或函数调用。循环的每次迭代都会对其进行评估。当评估结果为 true 时,循环执行。当评估结果为 false 时,循环停止。请注意,表达式的评估只在每次迭代之前进行。在循环内对表达式值的更改只会对下一次迭代产生影响。
l <local_block_loop> 由零个或多个语句组成,后面跟一个返回值,返回值可以是一个数值元组。它必须缩进四个空格或一个制表符。它可以包含用于退出循环的 break 语句,也可以包含用于退出当前迭代并继续下一个迭代的 continue 语句。
l 分配给 <identifier> 变量的值是 <local_block_loop> 的返回值,即循环最后一次迭代计算出的最后一个值,如果循环未执行,则为 na。
↓下面的脚本,使用 while 结构而不是 for 结构编写的 for 部分的第一个代码示例:
//@version=5
indicator("`for` loop")
lookbackInput = input.int(50, "Lookback in bars", minval = 1, maxval = 4999)
higherBars = 0
lowerBars = 0
if barstate.islast
var label lbl = label.new(na, na, "", style = label.style_label_left)
// 将循环计数器初始化为起始值.
i = 1
// 循环,直到 `i` 计数器的值 <= `lookbackInput` 值.
while i <= lookbackInput
if high[i] > high
higherBars += 1
else if high[i] < high
lowerBars += 1
// 计数器必须 "手动 "管理.
i += 1
label.set_xy(lbl, bar_index, high)
label.set_text(lbl, str.tostring(higherBars, "# higher bars\n") + str.tostring(lowerBars, "# lower bars"))
l i 计数器必须在 while 的局部代码块中明确地加一。
l 我们使用 += 操作符为计数器加一。lowerBars += 1 相当于 lowerBars := lowerBars + 1。
让我们使用 while 结构计算阶乘函数:
//@version=5
indicator("")
int n = input.int(10, "Factorial of", minval=0)
factorial(int val = na) =>
int counter = val
int fact = 1
result = while counter > 0
fact := fact * counter
counter := counter - 1
fact
// 只在第一个K线上评估函数.
var answer = factorial(n)
plot(answer)
l 我们使用 input.int() 作为输入,因为我们需要指定一个minval值来保护我们的代码。虽然input()也支持输入"int"类型的值,但它不支持minval参数。·
l 我们已将脚本的功能打包到一个 factorial() 函数中,该函数接受它必须计算的阶乘值作为参数。我们使用 int val = na 来声明函数的参数,这意味着如果在调用 factorial() 时没有参数,那么 val 参数将初始化为 na,这将阻止 while 循环的执行,因为其计数器 > 0 表达式将返回 na。因此,while 结构会将结果变量初始化为 na。反过来,由于 result 的初始化是我们函数局部块的返回值,因此函数将返回 na。
l 请注意 while 的局部代码块的最后一行:fact。这是局部代码块的返回值,也就是 while 结构最后一次迭代时的值。
我们并不要求对 result 进行初始化,这样做是为了便于阅读。我们也可以使用:
while counter > 0
fact := fact * counter
counter := counter - 1
fact
类型系统
· 简介
o Forms
o Types
o Forms
§ const
§ input
§ simple
§ series
o Types
§ int
§ float
§ bool
§ color
§ string
§ line, linefill, label, box and table
§ void
· `na` 的值
· Type 的属性
· Type 的转换
简介
Pine Script®的类型系统非常重要,因为它决定了在调用Pine Script®函数时可以使用什么样的值,而这是在Pine Script®中做任何事情的必要条件。虽然不了解类型系统也能写出非常简单的脚本,但要熟练使用Pine Script®语言,就必须对类型系统有一定的了解,而深入了解其精妙之处,能让你充分发挥Pine Script®的潜力。
类型系统使用form type pairs(形式类型对)来限定所有值的类型,无论是文字、变量、表达式的结果、函数返回值,还是调用函数时提供的参数。
form用来表达什么时候值是已知的。
type用来指定值的性质。
注意:
我们经常使用 "type"来指代 "form type "对。
类型系统与 Pine Script® 的执行模型和时间序列概念密切相关。理解这三者是充分发挥Pine Script®强大功能的关键。
Forms形式
Pine Script®的形式(forms)用于确定变量的已知值。它们是:
l "const",表示编译时值已知(在图表中添加指标或在Pine Script®编辑器中保存指标时)。
l "input "用于输入时值已知(在脚本的 "设置/input"选项卡中更改数值时)。
l "simple"(simple),用于第一条K线时值已知(当脚本在图表的第一个历史K线上开始执行时)
l "series",用于每个K线上值已知(在任何K线上执行脚本期间的任何时间)
形式(form)按以下层次结构排序:const < input < simple < series,其中 "const "比 "input "弱,"series "比 "simple" 强。form等级结构的规则是,当给出需要的形式时,较弱的形式也是允许的。
表达式的结果总是使用表达式计算结果的最强形式。此外,变量一旦获得较强的形式,其状态就不可逆转,永远不能再转换回较弱的形式。因此,"series"形式的变量永远无法转换回"simple"形式,来用于需要该形式参数的函数。
需要注意的是,在所有这些形式中,只有"series"形式允许在执行脚本时,在图表历史的每个K线之间动态改变值。这些值包括收盘价、hlc3 或使用"series"形式的值计算的任何变量。一旦脚本开始执行,"const"、"input"或"simple"形式的变量的值就不能更改。
Types类型
Pine Script® 类型可识别数值的性质。它们是:
l 基本类型:"int"、"float"、"bool"、"color "和 "string"。
l 特殊类型:"plot", "hline", "line", "linefill", "label", "box", "table", "array", "matrix", and "map".
l 用户自定义类型 (UDTs)
l "void"
每个基本类型都指变量中包含的值的性质: 1 是"int"类型,1.0 是"float"类型,"AAPL"是"string"类型,等等。特殊类型的变量包含一个ID,指向该类型名称的对象。如,label类型的变量包含一个指向标签的 ID(或指针),以此类推。"void"类型表示不返回任何值。
Pine Script® 编译器会自动将某些类型的值转换为其他类型的值。自动转换规则如下:int→float→bool. 有关类型转换的更多信息,请参见本章节的"类型转换"部分。
除了出现在函数标识中的参数定义外,Pine Script® 的形式在代码中是隐式的;它们从不被声明,因为它们总是由编译器决定。然而,类型可以在声明变量时指定,例如:
indicator("", "", true)
int periodInput = input.int(100, "Period", minval = 2)
float ma = ta.sma(close, periodInput)
bool xUp = ta.crossover(close, ma)
color maColor = close > ma ? color.lime : color.fuchsia
plot(ma, "MA", maColor)
plotchar(xUp, "Cross Up", "▲", location.top, size = size.tiny)
使用形式和类型
Forms(形式)
const
“const”形式的值必须在编译时知道,在您的脚本能够访问任何与它正在运行的商品品种/时间框架信息相关的信息之前。当您在Pine script®编辑器中保存脚本时,甚至不需要它已经在图表上运行,就会发生编译。“const”变量不能在脚本执行期间更改。
“const”形式的变量可以用字面量来初始化,也可以用只使用字面量的表达式或其他“const”形式的变量来计算。我们的《样式指南》推荐使用大写的SNAKE_CASE来命名“const”形式的变量。虽然这不是必须的,但“const”变量可以使用var关键字声明,这样它们只会在数据集的第一个K线上初始化。更多信息参见`var`部分。
下面是一些字面量的例子:
l ·int字面量: 1、-1、42
l ·float字面量:1. 、1.0、3.14、6.02E-23、3e8
l ·bool字面量:true、false
l ·string字面量:"A text literal", "Embedded single quotes'text'"
'Embedded double quotes "text"'
l ·color字面量:#FF55C6, #FF55C6ff
请注意:
在Pine Script®中,内置变量open, high, low, close, volume, time, hl2, hlc3, ohlc4等是“series”形式,因为它们的值可以一个K线一个K线地改变。
例如," const "形式是 indicator()中title和shorttitle参数的必要参数。这些都是有效的变量,在调用函数时可以作为这些形参的实参:
//@version=5
NAME1 = "My indicator"
var NAME2 = "My Indicator"
var NAME3 = "My" + "Indicator"
var NAME4 = NAME2 + " No. 2"
indicator(NAME4, "", true)
plot(close)
下面的脚本将引发编译错误:
//@version=5
var NAME = "My indicator for " + syminfo.type
indicator(NAME, "", true)
plot(close)
出现错误的原因是NAME的形式取决于syminfo.type的值,syminfo.type是一个"simple string"。syminfo.type返回string类型商品品种板块,如"crypto"(加密货币)、"forex"(外汇)等。
请注意,使用 := 操作符为先前声明的 "const "变量赋新值时,会将其转换为 "simple"变量,例如这里的 name1,由于它不是 "const "形式,所以我们没有使用大写名称:
var name1 = "My Indicator "
var NAME2 = "No. 2"
name1 := name1 + NAME2
当确定通过input.*()函数初始化的值时,"input "形式的值就已知了。这些函数决定了脚本用户可以在脚本的"设置/输入"选项卡中修改的值。当这些值被修改时,总是会触发从图表历史的起点(首条K线)重新执行脚本,因此"input"形式的变量在脚本开始执行时总是已知的,在脚本执行期间不会发生变化。
注意:
input.source()函数产生的是"series"类型的值,而不是 "input"类型的值。这是因为诸如开盘价、最高价、最低价、收盘价、hl2、hlc3、ohlc4 等内置变量都是"series"类型的。
下面的脚本,用户通过输入确定商品品种和时间框架,据此绘制由用户自定义的数据源和长度的移动平均线:
//@version=5
indicator("", "", true)
symbolInput = input.symbol("AAPL", "Symbol")
timeframeInput = input.timeframe("D", "Timeframe")
sourceInput = input.source(close, "Source")
periodInput = input(10, "Period")
v = request.security(symbolInput, timeframeInput,
ta.sma(sourceInput, periodInput))
plot(v)
l symbolInput、timeframeInput 和 periodInput 变量是 "input"形式。
l sourceInput 变量是 "series"形式,因为它是通过调用 input.source() 确定的。
l request.security()调用是有效的,因为它symbol和timeframe参数需要一个"simple"参数,而我们使用的"input"形式比"simple"弱。函数的表达式参数需要"series"形式的参数,而我们的sourceInput变量就是这种形式。请注意,由于此处需要使用"series"形式,因此我们也可以使用"const"、"input" 或"simple"形式。
l 根据《样式指南》的建议,我们在输入变量中使用了 "Input"后缀,以帮助代码读者记住这些变量的来源。
在需要使用 "input "形式的地方,也可以使用 "const "形式。
simple形式的值只有在图表历史记录的第一个K线开始执行脚本时才会知道,在脚本执行过程中这些值永远不会改变。例如,syminfo.*、timeframe.* 和ticker.* series的内置变量都返回"simple"形式的结果,因为它们的值取决于商品品种,而商品品种只有在执行脚本时才能被检测到。
此外,ta.ema()或ta.rma()等函数的长度参数也需要 "simple"形式参数,因为这些函数无法处理脚本执行过程中可能发生变化的动态长度。
使用"simple"形式的地方,也可以使用"const"或"input"。
series"形式的值(有时也称为动态值)具有最大的灵活性,因为它们可以在任何K线或甚至在同一K线的多次循环中发生变化。诸如开盘价、收盘价、最高价、时间或成交量等内置变量都是"series"形式,使用它们计算的表达式结果也是"series"形式。诸如barssince()或crossover()等函数产生的结果是"series"形式,因为每个K线的结果都不同,用于访问时间序列过去值的[]历史引用运算符的结果也是如此。虽然"series"形式是 Pine Script® 中最常用的形式,但它并不总是允许作为内置函数的参数。
假设你想在图表中显示枢轴点的值。这就需要将数值转换为string,因此你的代码将使用"series string"类型的字符串值。可以使用label.new() 函数在图表上显示这种"series string"类型的文本,因为它的文本参数接受"series"形式的参数:
//@version=5
indicator("", "", true)
pivotBarsInput = input(3)
hiP = ta.pivothigh(high, pivotBarsInput, pivotBarsInput)
if not na(hiP)
label.new(bar_index[pivotBarsInput], hiP, str.tostring(hiP, format.mintick),
style = label.style_label_down,
color = na,
textcolor = color.silver)
plotchar(hiP, "hiP", "•", location.top, size = size.tiny)
请注意:
l 调用str.tostring(hiP, format.mintick)将枢轴高点的值("series int"类型)转换为字符串("series string"类型),可以与label.new()一起使用。
l 虽然枢轴点价格刚好显示在枢轴点上,但实际上枢轴点需要经历pivotBarsInput条K线后才能检测到。之所以枢轴点价格出现在枢轴点上,是因为我们在检测到枢轴点后,使用bar_index[pivotBarsInput]参数(目前K线的bar_index值,向前偏移pivotBarsInput),将枢轴价格绘制在过去的K线上。若实时显示,价格将显示在实际枢轴点后的第pivotBarsInput条K线上。
l 检测到枢轴点时,使用plotchar()打印一个"•"。
l Pine Script®的plotshape()也可用于在图表上定位文本,但由于其文本参数需要一个"const string"参数,因此我们无法在脚本中用它代替label.new()。
使用"series"的地方也可以使用"const"、"input "或"simple"。
Types(类型)
int类型
整数字面量必须用十进制表示,例如:1、-1、750
bar_index、time、timenow、time_close或dayofmonth等内置变量的返回值均为"int"类型。
float类型
浮点数字面量包含一个分隔符(符号.),还可能包含符号e或E(表示"乘以10的X次方",其中X 符号e后面的数字),例如:3.14159 // Pi (π), -3.0, 6.02e23 // 6.02 * 10^23 1.6e-19
Pine Script® 中浮点数的内部精度为 1e-10。
bool类型
表示 bool 值的字面量只有两个:ture / false。
当"bool"类型的表达式返回"na",并用于测试条件语句或操作符时,将执行"false "分支。
color字面量形式的格式如下 #RRGGBB 或 #RRGGBBAA。其中,字母对代表 00 至 FF 十六进制值(十进制为 0 至 255):
l RR、GG 和 BB 是颜色的红、绿、蓝成分值。
l AA是颜色透明度(或Alpha分量)的可选值,其中00表示不可见,FF表示不透明。如果没有提供AA对,则使用FF。
l 十六进制字母可以是大写或小写字母
示例:#000000 #FF0000 #00FF00 #0000FF #FFFFFF #808080 #3ff7a0
Pine Script® 还内置了颜色常量,如 color.green、color.red、color.orange、color.blue(plot()和其他绘图函数中使用的默认颜色)等。
使用内置颜色常量时,可以使用 color.new 为其添加透明度信息。
请注意,在 color.*() 函数中指定红色、绿色或蓝色成分时,必须使用 0-255 的十进制值。在此类函数中指定透明度时,其形式为 0-100 值(可以是 "浮点 "类型,以访问底层的 255 个潜在值),其中颜色字面的 00-FF 标度是反转的: 100 表示透明,0 表示不透明。
下面是一个例子:
//@version=5
indicator("Shading the chart's background", "", true)
BASE_COLOR = color.navy
bgColor = dayofweek == dayofweek.monday ? color.new(BASE_COLOR, 50) :
dayofweek == dayofweek.tuesday ? color.new(BASE_COLOR, 60) :
dayofweek == dayofweek.wednesday ? color.new(BASE_COLOR, 70) :
dayofweek == dayofweek.thursday ? color.new(BASE_COLOR, 80) :
dayofweek == dayofweek.friday ? color.new(BASE_COLOR, 90) :
color.new(color.blue, 80)
bgcolor(bgColor)
有关在Pine Script®使用颜色的更多信息,请参阅 colors 页面。
string字面量可以用单引号或双引号括起来,例如:
"This is a double quoted string literal",'This is a single quoted string literal'
单引号和双引号在功能上是等同的。双引号内的string可以包含任意数量的单引号,反之亦然:
"It's an example",'The "Star" indicator'
可以使用反斜杠对string中的string分隔符进行转义。例如:
'It\'s an example',"The \"Star\" indicator"
使用 + 运算符可以连接string。
plot 和 hline 类型
Pine Script®的fill()函数会在两K线之间填充颜色。这两K线必须是通过调用plot()或hline()函数绘制的。在fill()函数中,每条绘制的线条都使用"plot"或"hline"类型的 ID,例如:
//@version=5
indicator("", "", true)
plotID1 = plot(high)
plotID2 = plot(math.max(close, open))
fill(plotID1, plotID2, color.yellow)
请注意,没有使用plot或hline关键字来明确声明plot()或hline()的 ID 的类型。
图形类型
Pine Script®从第4版开始使用图形。每种图形都有自己的类型:line, linefill, label, box, table。
每种类型还被用作一个命名空间,包含操作每种类型图形的所有内置函数。其中new()函数用于创建图形类型的对象:line.new()、linefil .new()、label.new()、box.new()和table.new()。
这些函数都会返回一个ID,这是唯一标识图形对象的引用。ID始终为"series"形式,因此其形式和类型为"series line"、"series label"等。图形ID的作用类似于指针,在图形命名空间的所有功能中,都被用来引用图形的特定实例。例如,在使用line.delete()删除线条时,line.new()调用返回的line ID将用于引用该线条。
图表点类型
图表点是表示图表坐标的特殊类型。脚本使用 chart.point 对象中的信息来确定lines, boxes, polylines和 labels的图表位置。
这种类型的对象包含三个字段:time, index和 price。绘图实例是使用 chart.point 中的时间还是价格字段作为 x 坐标,取决于绘图的 xloc 属性。
Collections(集合类型)
Pine Script® 中的集合(arrays, matrices, and maps数组、矩阵和映射)与其他特殊类型(如label)一样,都使用引用ID。ID的类型定义了集合所包含元素的类型。在Pine 中,我们通过在数组、矩阵或映射关键字后附加类型模板来指定数组、矩阵和映射类型:
n array<int>定义包含“int”类型元素的数组。
n array<label>定义一个包含“label”id的数组。
n array<UDT>定义一个包含用户定义类型(UDT)对象的数组。
n matrix<float>定义一个包含“float”元素的矩阵。
n matrix<UDT>定义一个包含用户定义类型(UDT)对象的矩阵。
n map<string,float>定义一个“string”键和“float”值的映射。
n map<int, UDT>定义一个含“int”键和(UDT)值的映射。
例如,你可以使用下列任何一种等价的方式声明一个单元素为10的“int”数组:
a1 = array.new<int>(1, 10)
array<int> a2 = array.new<int>(1, 10)
a3 = array.from(10)
array<int> a4 = array.from(10)
l int[]语法也可以指定由"int"元素组成的数组,但不鼓励使用。目前还不存在以这种方式指定矩阵或映射类型的等效语法。
l 针对特定类型的内置数组,如array.new_int(),我们更倾向于使用更通用的array.new<type>形式,即用 array.new<int>() 来创建一个包含 "int "元素的数组。
用户定义类型
使用 type 关键字可以创建用户定义类型(UDT),并从中创建对象。UDT是复合类型,包含任意数量的字段,可以是任何类型。定义用户定义类型的语法为:
l export 用于从库中导出 UDT。有关详细信息,请参阅库页面Libraries 。
l <UDT_identifier> 是用户定义类型的名称。
l <field_type> 是字段的类型。
l <field_name> 是字段的名称。
l <value> 是字段的可选默认值,将在创建该 UDT 的新对象时分配给该字段。如果没有指定默认值,则字段的默认值为 na。管理函数标识中参数缺省值的规则与管理字段缺省值的规则相同。例如,不能使用 [] 历史引用操作符,也不允许使用表达式。
在本例中,我们创建了一个包含两个字段的 UDT,用于保存枢轴点信息,即枢轴点的K线时间和价格水平:
type pivotPoint
int openTime
float level
用户自定义类型可以嵌入,因此字段可以与所属的 UDT 类型相同。在这里,我们为之前的 pivotPoint 类型添加了一个字段,该字段将保存另一个枢轴点的枢轴点信息:
type pivotPoint
int openTime
float level
pivotPoint nextPivot
UDT 可以使用两个内置方法:new() 和 copy()。请参阅对象页面了解它们。
Pine Script®中有一种 "void "类型。只有副作用且不返回可用结果的函数会返回 "void "类型。例如,alert()函数就有这样的功能(触发警报事件),但它不会返回任何有用的值。
void 结果不能用于表达式或赋值给变量。Pine Script® 中不存在 void 关键字,因为变量不能使用 "void "类型声明。
在 Pine Script® 中,有一种特殊的值叫做 na,它是 not available 的缩写,意思是表达式或变量的值是未定义的。它类似于 Java 中的 null 值或 Python 中的 None。
na 值几乎可以自动转换为任何类型。但在某些情况下,编译器无法自动推断 na 值的类型,因为可以应用多个自动类型转换规则。例如:
// Compilation error!编译错误!
myVar = na
在这里,编译器无法确定 myVar 是否将用于绘制某幅图,如 plot(myVar),其类型为 "float";或用于设置某些文本,如 label.set_text(lb,text=myVar),其类型为 "string";或用于其他目的。这种情况必须通过两种方法之一明确解决:
float myVar = na
myVar = float(na)
要测试某个值是否为na,必须使用一个特殊函数na()。例如:
myClose = na(myVar) ? 0 : close
不要使用 == 运算符测试 na 值,因为这种方法不可靠。
将计算设计成抗 na 值通常很有用。在本例中,我们定义了一个条件,当K线的收盘价高于前一个收盘价时,该条件为真。如果数据集的第一个K线不存在前一个收盘价,close[1] 将返回 na,为了使该计算在这种特殊情况下正确工作,我们使用 nz() 函数用当前K线的开盘价替换它:
bool risingClose = close > nz(close[1], open)
保护 na 值也可以防止初始 na 值在所有K线的计算结果中传播。这里出现这种情况是因为 ath 的初始值是 na,如果 math.max() 的参数之一是 na,它就会返回 na:
//在首条K线上,声明并初始化 `ath` 的值为 `na` .
var float ath = na
// 在所有K线上, 计算 `high` 和`ath`前值之间的最大值.
ath := math.max(ath, high)
为了避免这种情况,我们可以改用:
var float ath = na
ath := math.max(nz(ath), high)
这里,我们用零替换 ath 的任何 na 值。更好的办法是:
var float ath = high
ath := math.max(ath, high)
类型的模板
类型模板指定了集合(arrays, matrices, and maps数组、矩阵和映射)可包含的数据类型。
arrays数组和matrices矩阵的模板由尖括号包围的单一类型标识符组成,例如<int>、<label>和<PivotPoint>(其中PivotPoint是用户定义类型(UDT))。
maps映射模板由尖括号括起来的两个类型标识符组成,其中第一个指定了每个键/值对中键的类型,第二个指定了值的类型。例如,<string, float>是一个类型模板,用于保存string键和浮点值的映射。
用户可以使用以下方式构建类型模板:
l 基本类型:" int "、" float "、" bool "、" color "和" string"
l 特殊类型:" line "," linefill "," label "," box "和" table"
l 用户定义类型(udt)
注意:
· maps可以使用任何这些类型作值,但它们只能接受基本类型作键。
脚本使用类型模板来声明指向集合的变量,以及创建新的集合实例。例如:
//@version=5
indicator("Type templates demo")
//@variable 一个初始化并赋值`na`的变量,接受`int`值的数组。
array<int> intArray = na
//@variable 一个空矩阵,存放 `float`值 .
floatMatrix = matrix.new<float>()
//@variable 存放string键和color值的空映射.
stringColorMap = map.new<string, color>()
类型转换
Pine Script® 中有一种自动类型转换机制,可以将某些类型转换成另一种类型。自动类型转换规则如下: 当需要使用 "float "值时,可以使用 "int "值代替;当需要使用 "bool "值时,可以使用 "int "或 "float "值代替。
请参阅本代码中的自动转换操作:
//@version=5
indicator("")
plotshape(close)
请注意:
· plotshape() 的第一个参数名为 series,需要一个 "series bool "参数。该 "bool "参数的真/假值决定了函数是否绘制形状。
· 我们在调用 plotshape() 时,将 close 作为其第一个参数。如果没有 Pine 的自动转换规则(允许将 "float "转换为 "bool"),这种情况是不允许的。在将 "float "转换为 "bool "时,任何非零值都会转换为 true,而零值则会转换为 false。因此,只要 close 不等于零,我们的代码就会在所有K线上绘制一个 "X"。
有时需要将一种类型转换为另一种类型,因为自动转换规则无法满足要求。对于这些情况,存在显式类型转换函数。它们是:int(), float(), bool(), color(), string(), line(), linefill(), label(), box(), and table()。
这是一段无法编译的代码,因为在调用 ta.sma() 时,我们没有转换用于 length 的参数类型:
//@version=5
indicator("")
len = 10.0
s = ta.sma(close, len) // Compilation error!
plot(s)
代码编译失败,出现以下错误:无法调用参数'length'='len'的函数ta.sma。使用了一个"const float "类型的参数,但应该使用 "series int"类型。编译器告诉我们,我们提供了一个"float "值,而需要的是一个"int "值。没有自动转换规则可以将 "float "自动转换为 "int",因此我们需要自己进行转换。为此,我们使用int() 函数强制将作为长度提供给ta.sma()的值由"float "转换为 "int":
//@version=5
indicator("")
len = 10.0
s = ta.sma(close, int(len))
plot(s)
在声明变量并将其初始化为na时,显式类型转换也很有用。以下方式是等效的,将 na显式声明为label类型:
// 将 `na` 转换成 "label" 类型.
lbl = label(na) 或:
// 显示声明新变量类型.
label lbl = na
Tuples元组
元组是用逗号分隔的一组表达式,用括号括起来。当函数或局部代码块必须返回一个以上的变量结果时,可以使用元组。例如:
calcSumAndMult(a, b) =>
sum = a + b
mult = a * b
[sum, mult]
在本例中,函数代码块的最后一条语句中有一个双元素元组,即函数返回的结果。元组元素可以是任何类型。调用返回元组的函数还有一种特殊的语法,即在多变量声明的等号左侧使用元组声明。返回元组的函数(如 calcSumAndMult())的结果必须赋值给元组声明,即一组逗号分隔的新变量列表,这些新变量将接收函数返回的值。在这里,函数计算出的 sum 和 mult 变量的值将分配给 s 和 m 变量:
[s, m] = calcSumAndMul(high, low)
请注意,s 和 m 的类型不能明确定义,总是根据函数返回结果的类型推断。
元组对于在一次 request.security() 调用中请求多个值非常有用:
roundedOHLC() =>
[math.round_to_mintick(open), math.round_to_mintick(high), math.round_to_mintick(low), math.round_to_mintick(close)]
[op, hi, lo, cl] = request.security(syminfo.tickerid, "D", roundedOHLC())
or:
[op, hi, lo, cl] = request.security(syminfo.tickerid, "D", [math.round_to_mintick(open), math.round_to_mintick(high), math.round_to_mintick(low), math.round_to_mintick(close)])
如果不需要四舍五入,则使用此表格
[op, hi, lo, cl] = request.security(syminfo.tickerid, "D", [open, high, low, close])
元组还可以用作局部块的返回结果,例如在 if 语句中:
[v1, v2] = if close > open
[high, close]
else
[close, low]
但是,它们不能在三元语句中使用,因为三元语句的返回值不被视为局部块。这是不允许的:
// 不允许.
[v1, v2] = close > open ? [high, close] : [close, low]
请注意,函数返回的元组中的项目可能是simple形式,也可能是series形式,具体取决于其内容。如果一个元组包含一个series值,那么元组中的所有其他元素也将是series形式。例如:
//@version=5
indicator("tuple_typeforms")
makeTicker(simple string prefix, simple string ticker) =>
tId = prefix + ":" + ticker // simple string
source = close // series float
[tId, source]
// 这时所有变量都是 series
[tId, source] = makeTicker("BATS", "AAPL")
// 异常,不能调用'request.security',因数'series string' tId.
r = request.security(tId, "", source)
plot(r)
内置系统
· ·简介
· ·内置变量
· ·内置函数
简介
Pine Script® 拥有数百个内置变量和函数。它们为你的脚本提供有价值的信息,并为你进行计算,让你无需再编写代码。你对内置变量了解得越多,你就能用 Pine 脚本做更多的事情。
在本章节中,我们将概述 Pine 脚本®的一些内置变量和函数。在本手册中,我们将对这些内置变量和函数进行更详细的介绍。
《Pine Script® v5 参考手册》中定义了所有内置变量和函数。之所以称之为 "参考手册",是因为它是 Pine Script® 语言的权威参考资料。无论你是初学者还是专家,它都是你使用 Pine 编程时不可或缺的工具。如果你正在学习第一门编程语言,请把《参考手册》当作你的朋友。忽略它将使你的Pine Script®编程经历变得困难和令人沮丧,就像其他编程语言一样。
同族变量和函数共享相同的命名空间,命名空间是函数名称的前缀。例如,ta.sma()函数属于ta命名空间,代表"技术分析"。命名空间既可以包含变量,也可以包含函数。
有些变量也有函数版本,例如:
l ta.tr 变量返回当前K线的 "真实范围"。调用 ta.tr(true) 函数也会返回 "True Range"(真实范围),但计算时如果通常需要的前收盘价不存在,它就会改用 high - low 值来计算。
l time变量给出当前K线的开盘时间。time(timeframe) 函数从指定的timeframe返回K线的开盘时间,即使图表的时间框架不同。time(timeframe,session)函数从指定的时间框架返回K线的开盘时间,但前提是它在交易时段内。time(timeframe, session, timezone)函数从指定的时间框架返回K线的开盘时间,但前提是该时间必须在特定时区的交易时段内。
内置变量
内置变量有不同的用途。下面是几个例子:
l 价格和成交量相关变量:开盘价、最高价、最低价、收盘价、hl2、hlc3、ohlc4 和成交量。
l syminfo命名空间中与符号相关的信息:syminfo.basecurrency,syminfo.currency, syminfo.description, syminfo.mintick, syminfo.pointvalue, syminfo.prefix, syminfo.root, syminfo.session, syminfo.ticker, syminfo.tickerid, syminfo.timezone, 和 syminfo.type。
l Timeframe(又称 "时间框架 "或 "分辨率",如 15 秒、30 分钟、60 分钟、1D、3M)时间框架命名空间中的变量: timeframe.isseconds, timeframe.isminutes, timeframe.isintraday, timeframe.isdaily, timeframe.isweekly, timeframe.ismonthly, timeframe.isdwm, timeframe.multiplier, and timeframe.period。
l barstate命名空间中的K线状态(请参阅Bars tates页面):barstate.isconfirmed, barstate.isfirst, barstate.ishistory, barstate.islast, barstate.islastconfirmedhistory, barstate.isnew, 和 barstate.isrealtime。
l strategy命名空间中与策略相关的信息:strategy.equity, strategy.initial_capital,strategy.grossloss,strategy.grossprofit, strategy.wintrades, strategy.losstrades, strategy.position_size,strategy.position_avg_price,strategy.wintrades。
内置函数
许多函数都用于返回结果。下面是几个例子:
· math命名空间中与数学相关的函数:math.abs(), math.log(), math.max(), math.random(), math.round_to_mintick()等。
· ta 命名空间中的技术指标:ta.sma()、ta.ema()、ta.macd()、ta.rsi()、ta.supertrend() 等。
· ta命名空间中常用于计算技术指标的支持函数:ta.barssince()、ta.crossover()、ta.highest() 等。
· request命名空间中用于请求其他商品品种或时间框架数据的函数:request.dividends()、 request.arnings()、request.financial()、request.quandl()、request.security()、request.splits()。
· str 命名空间中用于操作string的函数:str.format()、str.length()、str.tonumber()、str.tostring()等。
· input命名空间中,用来定义输入值的函数(这些输入值,脚本用户可以在脚本的"设置/输入"选项卡中修改):input()、input.color()、input.int()、input.session()、input.symbol()等。
· color命名空间中用于处理颜色的函数:color.from_gradient()、color.new()、color.rgb()等。
有些函数不返回结果,但会产生副作用,也就是说,即使不返回结果,也会做一些事情:
· 定义Pine 脚本三种类型之一及其属性的声明语句的函数。每个脚本必须以以下三个函数之一的调用开始:indicator()、strategy()或library()。
· 绘图或着色函数:bgcolor()、plotbar()、plotcandle()、plotchar()、plotshape()、fill()等。
· strategy命名空间中,下订单策略的函数: strategy.cancel()、strategy.close()、strategy.entry()、strategy.exit()、strategy.order()等。
· strategy命名空间中,返回过去单笔交易信息的策略函数:strategy.closedtrades.entry_bar_index(),strategy.closedtrades.entry_price(),strategy.closedtrades.entry_time(),strategy.closedtrades.exit_bar_index(),strategy.closedtrades.max_drawdown(),strategy.closedtrades.max_runup(),strategy.closedtrades.profit()等。
· 生成警报事件的函数:alert() 和 alertcondition()。
另外一些函数会返回一个结果,但我们并不总是使用它,例如:hline()、plot()、array.pop()、label.new()等。
《Pine Script® v5 参考手册》中定义了所有内置函数。你可以点击网页中出现的任何一个函数名称,跳转到《参考手册》中该函数的词条。词条记录了函数的签名,即允许的参数列表和返回值的形式-类型(一个函数可以返回多个结果)。《参考手册》还列出每个参数的词条:
· 名称。
· 所需值的形式-类型(在调用函数时,我们使用参数来确定传递给函数的值)。
· 参数是否必需。
所有内置函数的签名中都定义了一个或多个参数。并非每个函数都需要所有参数。
让我们看看 ta.vwma() 函数,它返回变量值的成交量加权移动平均值。这是它在参考手册中的词条:
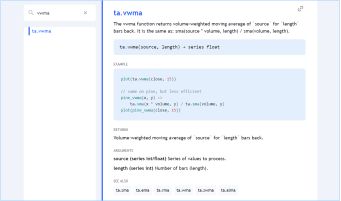
该条目为我们提供了使用该函数所需的信息:
· ·函数的作用。
· ·签名(或定义):
ta.vwma(source, length) → series float
· 包括的参数:source, length
· 返回结果的形式和类型: "series float"。
· 使用示例: plot(ta.vwma(close,15))。
· 另一示例显示了它的操作,但以详细形式显示,以便您更好地理解其计算。请注意,这只是为了解释,而不是作为可用代码,因为它更复杂,执行时间更长。使用详细形式只有缺点。
· "返回值 "部分确切解释了函数返回的值。
· "ARGUMENTS(参数)"部分列出了每个参数,并给出了调用函数时参数所需的形式类型等关键信息。
· "SEE ALSO(另见)"部分将为您提供相关的《参考手册》条目。·
下面是在一行代码中调用函数,声明一个myVwma变量,并将ta.vwma(close, 20)的结果赋值给该变量:
myVwma = ta.vwma(close, 20)
· 我们使用内置变量 close 作为source参数的参数。
· 我们使用 20 作为length参数的参数。
· 如果放在全局范围内(即语句从行的第一个位置开始),它将根据 Pine Script® 运行时在图表的每个K线上执行。
我们还可以在调用函数时使用参数名。在函数调用中使用的参数名为关键字参数:
myVwma = ta.vwma(source = close, length = 20)
使用关键字参数时,您可以改变参数的位置,但前提是所有参数都使用关键字参数。在调用带有许多参数的函数(如indicator())时,前面参数的可以不用关键字参数,直到要跳过某些参数。如果跳过一些参数,就必须使用关键字参数,这样Pine Script®编译器才能找出这些参数对应的参数,例如:
indicator("Example", "Ex", true, max_bars_back = 100)
不允许下面这种引发混乱的方式:
indicator(precision = 3, "Example") // Compilation error!
在调用内置程序时,必须确保参数的形式和类型符合要求。
要做到这点,需要了解 Pine Script® 的类型系统。每个内置函数的《参考手册》条目都包含一个 "ARGUMENTS"(参数)部分,其中列出了为每个函数参数提供的参数所需的形式类型。
用户自定义函数
· ·简介
· ·单行函数
· ·多行函数
· ·脚本中的作用域
· ·返回多个结果的函数
· ·限制
简介
用户自定义函数是由用户自己编写的函数,与 Pine Script® 中的内置函数不同。用户自定义函数可以用来定义必须重复进行的计算,或者将计算从脚本的主要计算部分中分离出来。当没有内置函数可以满足你的需求时,可以将用户自定义函数视为扩展 Pine Script® 功能的一种方式。
你可以用两种方式编写函数:
· 在一行中编写,当函数比较简单时;或者
· 多行编写
函数可以放在两个地方:
· 如果一个函数只在一个脚本中使用,你可以将它包含在使用它的脚本中。有关在脚本中放置函数的建议,请参阅我们的样式指南。
· 你可以创建一个 Pine Script® 库来包含你的函数,这样就可以在其他脚本中重复使用这些函数,而无需复制它们的代码。库函数有不同的要求。在库页面中会有解释。
无论使用一行还是多行代码编写,用户定义的函数都具有以下特点:
· 不能被嵌入。所有函数都在脚本的全局范围内定义。
· 不支持递归。不允许函数在自己的代码中调用自己。
· 函数返回值的类型是自动确定的,取决于每个特定函数调用中使用的参数类型。
· 函数的返回值是函数体中的最后一个值。
· 脚本中的每个函数调用实例都有自己独立的历史记录。
单行函数
简单的函数通常可以用一行来编写。这就是单行函数的正式定义:
<function_declaration>
<identifier>(<parameter_list>) => <return_value>
<parameter_list>
{<parameter_definition>{, <parameter_definition>}}
<parameter_definition>
[<identifier> = <default_value>]
<return_value>
<statement> | <expression> | <tuple>
例如:
f(x, y) => x + y
声明函数 f() 后,可以使用不同类型的参数来调用它:
a = f(open, close)
b = f(2, 2)
c = f(open, 2)
在上面的示例中,变量 a 的类型是series,因为参数都是series。变量 b 的类型是整数,因为参数都是字面量整数。变量 c 的类型是series,因为序列和字面整数相加的结果是序列。
多行函数
Pine Script® 还支持以下语法的多行函数:
<identifier>(<parameter_list>) =>
<local_block>
<identifier>(<list of parameters>) =>
<variable declaration>
...
<variable declaration or expression>
<parameter_list> //参数列表
{<parameter_definition>{, <parameter_definition>}}
<parameter_definition> //参数属性
[<identifier> = <default_value>]
多行函数的主体由多条语句组成。每条语句都放在单独的一行中,并且必须在前面加上一个缩进(4 个空格或 1 个制表符)。语句前的缩进表示它是函数主体的一部分,而不是脚本全局范围的一部分。在函数代码之后,第一条没有缩进的语句表示函数主体已结束。
函数正文的最后一条语句是一个表达式或一个已声明的变量。该表达式(或变量)的结果将是函数调用的结果::
geom_average(x, y) =>
a = x*x
b = y*y
math.sqrt(a + b)
函数 geom_average 有两个参数,并在正文中创建了两个变量:a 和 b。最后一条语句调用了函数 math.sqrt(平方根的提取)。调用 geom_average 将返回最后一个表达式的值:(math.sqrt(a + b))。
脚本中的作用域
在函数体或其他局部代码块之外声明的变量属于全局作用域。用户声明的函数和内置函数以及内置变量也属于全局作用域。
每个函数都有自己的局部作用域。函数中声明的所有变量以及函数的参数都属于该函数的作用域,这意味着无法从外部(如全局作用域或其他函数的局部作用域)引用它们。
另一方面,由于可以在函数的局部作用域中引用在全局作用域中声明的任何变量或函数(自引用递归调用除外),我们可以说局部作用域嵌入到了全局作用域中。
在 Pine Script® 中,不允许使用嵌套函数,即不能在一个函数中声明另一个函数。所有用户函数都在全局作用域中声明。局部作用域不能相互交叉。
返回多个结果的函数
在大多数情况下,函数只返回一个结果,但也有可能返回一个结果列表(类似于元组的结果):
fun(x, y) =>
a = x+y
b = x-y
[a, b]
调用此类函数需要特殊的语法:
[res0, res1] = fun(open, close)
plot(res0)
plot(res1)
限制
用户自定义函数可使用任何Pine Script®内置函数,但以下除外:barcolor(), fill(), hline(), indicator(), library(), plot(),
plotbar(), plotcandle(), plotchar(), plotshape() 和 strategy()。
对象
· ·简介
· ·创建对象
· ·更改字段值
· ·集合对象
· ·复制对象
· ·遮蔽
注:
本章节包含高级内容。如果你是Pine Script®程序的初学者,我们建议你先熟悉其他更容易上手的Pine Script®功能,然后再进行学习。
简介
Pine Script®对象是用户定义类型(UDT)的实例。它们等同于变量,包含称为字段的部分,每个字段可以容纳不同类型的独立值。
有经验的程序员可以将 UDT 视为无方法类。它们允许用户创建自定义类型,在一个逻辑实体下组织不同的值。
创建对象
在创建对象之前,必须先定义其类型。类型系统页面的 "用户定义类型"部分介绍了如何进行定义。
让我们定义一个 pivotPoint 类型来保存透视信息:
type pivotPoint
int x
float y
string xloc = xloc.bar_time
请注意:
· 我们使用 type 关键字来声明 UDT 的创建。
· 我们将新 UDT 命名为 pivotPoint。
· 在第一行之后,我们创建了一个局部块,其中包含每个字段的类型和名称。
· x 字段将保存枢轴点的 x 坐标。之所以声明为 "int",是因为它将保存时间戳或 "int "类型的K线索引。
· y 是一个 "float",因为它将保存枢轴点的价格。
· xloc 是一个字段,用于指定 x 的单位:xloc.bar_index 或 xloc.bar_time。我们使用 = 运算符将其默认值设置为 xloc.bar_time。当从该 UDT 创建对象时,其 xloc 字段将被设置为该值。
现在我们已经定义了pivotPoint UDT,可以继续创建对象。我们使用UDT的new()内置方法创建对象。要从pivotPoint UDT创建一个新的foundPoint对象,可以使用:
foundPoint = pivotPoint.new()
我们还可以使用以下方法为创建的对象指定字段值:
foundPoint = pivotPoint.new(time, high)
等效:
foundPoint = pivotPoint.new(x = time, y = high)
此时,foundPoint 对象的 x 字段将包含创建时内置的time值,y 字段将包含 high 值,xloc 字段将包含默认值 xloc.bar_time,因为创建对象时没有为其定义值。
使用以下方法,通过使用对象占位符来声明na对象名称来创建对象:
pivotPoint foundPoint = na
本例显示的是检测到最大枢轴点的标签。枢轴点值是在发生后检测到的 legsInputK线,因此我们必须在过去绘制标签,使其出现在枢轴点上:
//@version=5
indicator("Pivot labels", overlay = true)
int legsInput = input(10)
// 定义自定义类型 `pivotPoint`
type pivotPoint
int x
float y
string xloc = xloc.bar_time
// 删除高点枢轴点 high pivots.
pivotHighPrice = ta.pivothigh(legsInput, legsInput)
if not na(pivotHighPrice)
// 发现新的枢轴高点;回退到往前legsInputt条K 线上显示标签。
foundPoint=pivotPoint.new(time[legsInput],pivotHighPrice)
label.new(
foundPoint.x,
foundPoint.y,
str.tostring(foundPoint.y, format.mintick),
foundPoint.xloc,
textcolor = color.white)
请注意上面例子中的这一行:
foundPoint = pivotPoint.new(time[legsInput], pivotHighPrice)
也可以用下面的方式来写:
pivotPoint foundPoint = na
foundPoint := pivotPoint.new(time[legsInput], pivotHighPrice)
使用var或varip创建对象时,这些关键字作用于对象的所有字段:
//@version=5
indicator("")
type barInfo
int i = bar_index
int t = time
float c = close
// 首条K线上创建对象.
var firstBar = barInfo.new()
// 每条K线上创建对象.
currentBar = barInfo.new()
plot(firstBar.i)
plot(currentBar.i)
更改字段值
对象的字段值可以使用 := 重赋值操作符进行更改。
上一个示例中的这一行:
foundPoint = pivotPoint.new(time[legsInput], pivotHighPrice)
可以用下面的方式来写:
foundPoint = pivotPoint.new()
foundPoint.x := time[legsInput]
foundPoint.y := pivotHighPrice
对象集合
Pine Script® 集合(数组、矩阵和映射)可以包含对象,允许用户为其数据结构添加虚拟维度。要声明对象集合,只需在其类型模板中传递一个 UDT 名称即可。
声明一个空数组存放用户定义类型pivotPoint的对象:
pivotHighArray = array.new<pivotPoint>()
要显式地将变量类型声明为用户定义类型的数组、矩阵或映射,可使用集合的类型关键字,连着其类型模板。例如:
var array<pivotPoint> pivotHighArray = na
pivotHighArray := array.new<pivotPoint>()
让我们利用所学知识创建一个脚本来检测枢轴高点。脚本首先在数组中收集历史枢轴点信息。然后,在最后一个历史K线上循环浏览数组,为每个枢轴点创建一个标签,并用线将枢轴点点连接起来:
//@version=5
indicator("Pivot Points High", overlay = true)
int legsInput = input(10)
// 定义自定义类型`pivotPoint`,包含枢轴点时间和价格.
type pivotPoint
int openTime
float level
// 创建一个空的 `pivotPoint` 数组.
var pivotHighArray = array.new<pivotPoint>()
// 检测新的枢轴点(未找到枢轴点时返回 `na).
pivotHighPrice = ta.pivothigh(legsInput, legsInput)
// 为每个检测到的枢轴点在数组末尾添加一个新的 `pivotPoint` 对象.
if not na(pivotHighPrice)
// 找到新枢轴点;创建`pivotPoint`类型的新对象,设置`openTime和level字段.
newPivot = pivotPoint.new(time[legsInput], pivotHighPrice)
// 将新的枢轴点对象添加到数组中.
array.push(pivotHighArray, newPivot)
// 在最后一个历史K线上,绘制枢轴点标签和连接线.
if barstate.islastconfirmedhistory
var pivotPoint previousPoint = na
for eachPivot in pivotHighArray
// 在枢轴点上显示标签。
label.new(eachPivot.openTime, eachPivot.level, str.tostring(eachPivot.level, format.mintick), xloc.bar_time, textcolor = color.white)
// 在枢轴点之间创建一K线.
if not na(previousPoint)
// 只从循环的第二次迭代开始创建一条直线,连接两个枢轴点。
line.new(previousPoint.openTime, previousPoint.level, eachPivot.openTime, eachPivot.level, xloc = xloc.bar_time)
// 保存枢轴点,以便在下一次迭代中使用.
previousPoint := eachPivot
复制对象
在 Pine 中,对象是通过引用分配的。当一个现有对象被赋值给一个新变量时,两者都指向同一个对象。
在下面的示例中,创建一个pivot1对象,并将x字段设置为1000。然后,声明一个pivot2变量,包含对pivot1对象的引用,因此都指向同一个实例。更改pivot2.x也会更改pivot1.x,因为两者都指向同一个对象的x字段:
//@version=5
indicator("")
type pivotPoint
int x
float y
pivot1 = pivotPoint.new()
pivot1.x := 1000
pivot2 = pivot1
pivot2.x := 2000
// 两个绘图的值都是2000.
plot(pivot1.x)
plot(pivot2.x)
要创建一个独立于原始对象的对象拷贝,我们可以使用内置的 copy() 方法。
在本例中,我们声明 pivot2 变量指向 pivot1 对象的复制实例。现在,更改 pivot2.x 不会改变 pivot1.x,因为它指向的是一个独立对象的 x 字段:
//@version=5
indicator("")
type pivotPoint
int x
float y
pivot1 = pivotPoint.new()
pivot1.x := 1000
pivot2 = pivotPoint.copy(pivot1)
pivot2.x := 2000
// Plots 1000 and 2000.
plot(pivot1.x)
plot(pivot2.x)
值得注意的是,内置的 copy() 方法会生成一个对象的浅层拷贝。如果对象的字段属于特殊类型(array, matrix, map, line, linefill, label, box, or table),则对象浅层拷贝中的这些字段将指向与原始对象相同的实例。
下面的示例中,我们定义了一个信息标签(InfoLabel)类型,其中一个字段是label。脚本实例化了父对象的浅层拷贝,然后调用用户定义的set()方法更新每个对象的info和lbl段。由于两个对象的lbl字段都指向同一个标签实例,因此任何一个对象中该字段的更改都会影响另一个对象:
//@version=5
indicator("Shallow Copy")
type InfoLabel
string info
label lbl
method set(InfoLabel this, int x = na, int y = na, string info = na) =>
if not na(x)
this.lbl.set_x(x)
if not na(y)
this.lbl.set_y(y)
if not na(info)
this.info := info
this.lbl.set_text(this.info)
var parent = InfoLabel.new("", label.new(0, 0))
var shallow = parent.copy()
parent.set(bar_index, 0, "Parent")
shallow.set(bar_index, 1, "Shallow Copy")
要生成一个对象的深层拷贝,并使其所有特殊类型字段都指向独立实例,我们必须显式复制这些字段。
在本示例中,我们定义了一个 deepCopy() 方法,该方法可实例化一个新的 InfoLabel 对象,其 lbl 字段指向原对象的字段拷贝。对深层拷贝的 lbl 字段的更改不会影响父对象,因为它指向的是一个单独的实例:
//@version=5
indicator("Deep Copy")
type InfoLabel
string info
label lbl
method set(InfoLabel this, int x = na, int y = na, string info = na) =>
if not na(x)
this.lbl.set_x(x)
if not na(y)
this.lbl.set_y(y)
if not na(info)
this.info := info
this.lbl.set_text(this.info)
method deepCopy(InfoLabel this) =>
InfoLabel.new(this.info, this.lbl.copy())
var parent = InfoLabel.new("", label.new(0, 0))
var deep = parent.deepCopy()
parent.set(bar_index, 0, "Parent")
deep.set(bar_index, 1, "Deep Copy")
遮蔽
为了避免未来添加到 Pine Script® 中的命名空间与现有脚本中的 UDT 或对象名称发生冲突,UDT和对象的名称通常会对语言命名空间进行遮蔽处理。例如,UDT 或对象可以使用内置类型的名称,如line或table。
只有语言的五种原始类型不能用来命名 UDT 或对象:int、float、string、bool 和 color。
方法
· 简介
· 内置方法
· 用户定义方法
· 方法重载
· 高级示例
方法简介
Pine Script®方法是与内置类型或用户自定义类型的特定实例相关的专用函数。它们在大多数方面与普通函数基本相同,但语法更简短、更方便。用户可以直接在变量上使用点符号访问方法,就像访问Pine Script®对象的字段一样。
内置方法
Pine Script®包含 array, matrix, map, line, linefill, label, box和table类型的内置方法。这些方法为用户在脚本中调用这些类型的专用例程提供了更简洁的方法。
使用这些特殊类型时,下面的表达式:
mespace>.<functionName>([paramName =] <objectName>, …)
和
<objectName>.<functionName>(…)
是等价的。例如,与其使用:
array.get(id, index)
来获取指定索引处的数组 id 值,我们只需使用:
id.get(index)
来达到同样的效果。由于 get() 在此处是 id 的一个方法,因此用户无需引用函数的命名空间。
下面的代码是一个实用示例,演示如何使用内置方法代替函数。
以下脚本,每隔n条K线取样一次价格,用指定数量的价格计算布林通道。它调用array.push()和array.shift()在sourceArray中排列sourceInput值,再调用array.avg()和array.stdev()计算sampleMean和sampleDev。然后,脚本使用这些值计算highBand和lowBand,并将它们与样本平均值一起绘制在图表上:
//@version=5
indicator("Custom Sample BB", overlay = true)
float sourceInput = input.source(close, "Source")
int samplesInput = input.int(20, "Samples")
int n = input.int(10, "Bars")
float multiplier = input.float(2.0, "StdDev")
var array<float> sourceArray = array.new<float>(samplesInput)
var float sampleMean = na
var float sampleDev = na
// 判断是否经过了' n '条K线.每n条K线,取一次价格,更新数组。
if bar_index % n == 0
// 更新数组.队列
array.push(sourceArray, sourceInput)
array.shift(sourceArray)
// 更新平均值和标准差(2倍).
sampleMean := array.avg(sourceArray)
sampleDev := array.stdev(sourceArray) * multiplier
// 计算布林通道.
float highBand = sampleMean + sampleDev
float lowBand = sampleMean - sampleDev
plot(sampleMean, "Basis", color.orange)
plot(highBand, "Upper", color.lime)
plot(lowBand, "Lower", color.red)
重写这段代码,使用方法而不是内置函数。在新版本中,我们将脚本中的所有内置array.*函数替换为等效的方法:
//@version=5
indicator("Custom Sample BB", overlay = true)
float sourceInput = input.source(close, "Source")
int samplesInput = input.int(20, "Samples")
int n = input.int(10, "Bars")
float multiplier = input.float(2.0, "StdDev")
var array<float> sourceArray = array.new<float>(samplesInput)
var float sampleMean = na
var float sampleDev = na
// 判断是否经过了' n '条K线.每n条K线,取一次价格,更新数组。
if bar_index % n == 0
// Update the queue.
sourceArray.push(sourceInput)
sourceArray.shift()
//更新平均值和标准差(2倍)..
sampleMean := sourceArray.avg()
sampleDev := sourceArray.stdev() * multiplier
// Calculate band values.
float highBand = sampleMean + sampleDev
float lowBand = sampleMean - sampleDev
plot(sampleMean, "Basis", color.orange)
plot(highBand, "Upper", color.lime)
plot(lowBand, "Lower", color.red)
请注意:
· 我们使用 sourceArray.* 调用数组方法,而不是引用数组命名空间。
· 我们在调用方法时不将 sourceArray 作为参数,因为它们已经引用了对象。
用户自定义方法
Pine Script®允许用户为任何内置类型或用户自定义类型的对象定义自定义方法。定义方法与定义函数基本相同,但有两个主要区别:
· method 关键字必须包含在函数名称之前。
· 必须明确声明签名中第一个参数的类型,因为它代表方法将关联的对象类型。
[export] method <functionName>(<paramType> <paramName> [= <defaultValue>], …) =>
<functionBlock>
让我们在之前的布林带示例中应用用户自定义方法,封装全局范围内的操作,这将简化代码并提高可重用性。请看示例中的这一部分:
Identify if `n` bars have passed.
if bar_index % n == 0
// Update the queue.
sourceArray.push(sourceInput)
sourceArray.shift()
// 更新平均值和标准差(2倍)
sampleMean := sourceArray.avg()
sampleDev := sourceArray.stdev() * multiplier
// Calculate band values.
float highBand = sampleMean + sampleDev
float lowBand = sampleMean - sampleDev
首先,我们将定义一个简单的方法,只需一次调用即可通过数组对值进行排队。
当takeSample为true时,这个maintainQueue()方法会调用srcArray上的push()和shift()方法,并返回对象:
// @function 维护大小为srcArray的数组。(大小由调用数组决定)
// 它向数组追加一个value并移除零位的最老元素。
// @param srcArray (array<float>) 维持队列的数组。
// @param value(float)要添加到数组中的新值。
// 数组中最老的值也会被移除,因此其大小不变。
// @param takeSample (bool) 只有当该参数为 true 时,新的 `value` 才会被推入数组。
// @returns (array<float>) `srcArray` 对象。
method maintainQueue(array<float> srcArray, float value, bool takeSample = true) =>
if takeSample
srcArray.push(value)
srcArray.shift()
srcArray
· 就像用户定义的函数一样,我们使用 @function 编译器注解来记录方法描述。
现在,我们可以在示例中用 sourceArray.maintainQueue() 替换 sourceArray.push() 和 sourceArray.shift():
// Identify if `n` bars have passed.
if bar_index % n == 0
// Update the queue.
sourceArray.maintainQueue(sourceInput)
// Update the mean and standard deviaiton values.
sampleMean := sourceArray.avg()
sampleDev := sourceArray.stdev() * multiplier
// Calculate band values.
float highBand = sampleMean + sampleDev
float lowBand = sampleMean - sampleDev
从这里开始,我们将进一步简化代码,定义一个在其范围内处理所有布林带计算的方法。
calcBB()方法会调用srcArray上的avg()和stdev()方法,在calculate为true时更新平均值和标准偏差。该方法用这些值返回一个元组,分别包含基础值、上轨线和下轨线:
// @function 从数据数组中计算布林带值。
// @param srcArray (array<float>) 保存数组的数组。
// @param multiplier (float) 标准偏差乘数。
// @param calcuate (bool) 只有当此值为 true 时,方法才会计算新值。
// @returns 分别包含基数、上限和下限的元组。
method calcBB(array<float> srcArray, float mult, bool calculate = true) =>
var float mean = na
var float dev = na
if calculate
// 计算阵列的平均值和标准偏差。
mean := srcArray.avg()
dev := srcArray.stdev() * mult
[mean, mean + dev, mean - dev]
有了这种方法,我们就可以将布林带计算从全局范围中移除,从而提高代码的可读性:
bool newSample = bar_index % n == 0
// 更新数组,并根据每个新样本计算新的 BB 值。
[sampleMean, highBand, lowBand] = sourceArray.maintainQueue(sourceInput, newSample).calcBB(multiplier, newSample)
· 我们没有在全局范围内使用if块,而是定义了一个newSample变量,该变量每隔n个K线为真maintainQueue()和calcBB()方法将此值用于各自takeSample和calculate参数。
· 由于maintainQueue()方法会返回它所引用的对象,因此我们可以在同一行代码中调用calcBB(),因为这两个方法都适用于array<float>实例。
下面是应用了用户自定义方法后的完整脚本示例:
@version=5
indicator("Custom Sample BB", overlay = true)
float sourceInput = input.source(close, "Source")
int samplesInput = input.int(20, "Samples")
int n = input.int(10, "Bars")
float multiplier = input.float(2.0, "StdDev")
var array<float> sourceArray = array.new<float>(samplesInput)
// @function 维护一个大小为 `srcArray` 的数组。
// 它向数组追加一个 `value` 并移除位于零位的最旧元素。
// @param srcArray (array<float>) 维持数组的数组。
// @param value(float)要添加到数组中的新值。
// 数组中最老的值也会被移除,因此其大小不变。
// @param takeSample (bool) 当该参数为tru 时新的value被推入数组。
// @returns (array<float>) `srcArray` 对象。
method maintainQueue(array<float> srcArray, float value, bool takeSample = true) =>
if takeSample
srcArray.push(value)
srcArray.shift()
srcArray
// @function 从数据数组中计算布林带值。
// @param srcArray (array<float>) 保存数组的数组。
// @param multiplier (float) 标准偏差乘数。
// @param calcuate (bool) 只有当此值为 true 时,方法才会计算新值。
// @returns 分别包含基数、上限和下限的元组。
method calcBB(array<float> srcArray, float mult, bool calculate = true) =>
var float mean = na
var float dev = na
if calculate
// 计算阵列的平均值和标准偏差。
mean := srcArray.avg()
dev := srcArray.stdev() * mult
[mean, mean + dev, mean - dev]
// 识别是否已通过 `n` 条K线.
bool newSample = bar_index % n == 0
// 更新数组,并对每个新样本计算新的 BB 值。
[sampleMean, highBand, lowBand] = sourceArray.maintainQueue(sourceInput, newSample).calcBB(multiplier, newSample)
plot(sampleMean, "Basis", color.orange)
plot(highBand, "Upper", color.lime)
plot(lowBand, "Lower", color.red)
方法重载
用户自定义方法可覆盖和重载具有相同标识符的内置和用户自定义的已有方法。这种功能允许用户在相同方法名下关联不同参数签名来定义多个例程。
举个简单的例子,假设我们想定义一个方法来识别变量的类型。由于我们必须明确指出与用户定义方法相关的每种对象类型,因此我们要为希望被识别的每种类型定义重载。
下面,我们定义了一个 getType() 方法,用于返回变量类型的string表示,并为五种基本类型定义了重载:
@function Identifies an object's type.
// @param this Object to inspect.
// @returns (string) A string representation of the type.
method getType(int this) =>
na(this) ? "int(na)" : "int"
method getType(float this) =>
na(this) ? "float(na)" : "float"
method getType(bool this) =>
na(this) ? "bool(na)" : "bool"
method getType(color this) =>
na(this) ? "color(na)" : "color"
method getType(string this) =>
na(this) ? "string(na)" : "string"
现在,我们可以使用这些重载来检测某些变量。下面这个脚本使用 str.format() 对五个不同变量调用 getType() 方法得到的结果格式化为一个resultsstring,然后使用内置的set_text()方法将这个string显示在 lbl 标签中:

//@version=5
indicator("Type Inspection")
// @function 标识对象的类型.
// @param this 要检查的对象。
// @returns (string) 类型的string表示.
method getType(int this) =>
na(this) ? "int(na)" : "int"
method getType(float this) =>
na(this) ? "float(na)" : "float"
method getType(bool this) =>
na(this) ? "bool(na)" : "bool"
method getType(color this) =>
na(this) ? "color(na)" : "color"
method getType(string this) =>
na(this) ? "string(na)" : "string"
a = 1
b = 1.0
c = true
d = color.white
e = "1"
// 检查变量并格式化结果.
results = str.format(
"a: {0}\nb: {1}\nc: {2}\nd: {3}\ne: {4}",
a.getType(), b.getType(), c.getType(), d.getType(), e.getType()
)
var label lbl = label.new(0, 0)
lbl.set_x(bar_index)
lbl.set_text(results)
请注意
· 每个变量的基本类型决定了编译器将使用哪种 getType() 重载。
· 当变量为 na 时,该方法将在输出string中附加"(na)",以表明该变量为空。
让我们运用所学知识构建一个脚本,估算数组中元素的累积分布,即数组中小于或等于任意给定值的元素的比例。
我们可以选择多种方法来实现这一目标。在本例中,我们将首先定义一个方法来替换数组中的元素,这将有助于我们计算元素在数值范围内的出现次数。
下面写的是数组<float>实例的内置 fill() 方法的重载。
该重载将 srcArray 中位于 lowerBound 和 upperBound 之间范围内的元素替换为 innerValue,并将范围外的所有元素替换为 outerValue:
// @function 用inerValue替换srcArray中lowerBound和upperBound之间的元素
// 并用 `outerValue` 替换超出范围的元素。
// @param srcArray (array<float>) 要修改的数组。
// @param innerValue (float) 要替换范围内元素的值。
// @param outerValue (float) 用来替换范围外元素的值。
// @param lowerBound (float) 用 `innerValue` 替换的最小值。
// @param upperBound (float) 替换为 `innerValue` 的最高值。
// @returns (array<float>) `srcArray` 对象。 method fill(array<float> srcArray, float innerValue, float outerValue, float lowerBound, float upperBound) =>
for [i, element] in srcArray
if (element >= lowerBound or na(lowerBound)) and (elem ent <= upperBound or na(upperBound))
srcArray.set(i, innerValue)
else
srcArray.set(i, outerValue)
srcArray
使用这种方法,我们可以通过值的范围过滤数组,生成一个事件数组。例如,表达式:
srcArray.copy().fill(1.0, 0.0, min, val)
复制 srcArray 对象,将 min 和 val 之间的所有元素替换为1.0,然后将val以上的所有元素替换为0.0。从这里可以很容易地计算出累积分布函数在val处的输出,它就是得到的数组的平均值:
srcArray.copy().fill(1.0, 0.0, min, val).avg()
请注意
· 只有当用户在调用中提供 innerValue、outerValue、lowerBound 和 upperBound 参数时,编译器才会使用此 fill() 重载而不是内置重载。
· 如果 lowerBound 或 upperBound 为 na,在筛选填充范围时将忽略其值。
· 我们可以在同一行代码中连续调用 copy()、fill() 和 avg(),因为前两个方法都返回一个array<float>实例。
现在我们可以用它来定义一个计算经验分布值的方法。下面的eCDF()方法将从srcArray的累积分布函数中估算出若干个等距的递增阶数,并将结果推送到cdfArray中:
// @function 估算 `srcArray` 的经验 CDF。
// @param srcArray (array<float>) 要计算的数组。
// @param steps (int) 分组数。
// @returns (array<float>) CDF 估计比率数组。
method eCDF(array<float> srcArray, int steps) =>
float min = srcArray.min()
float rng = srcArray.range() / steps
array<float> cdfArray = array.new<float>()
// 在 `cdfArray` 中添加按值区域筛选的 `srcArray` 平均值。
float val = min
for i = 1 to steps
val += rng
cdfArray.push(srcArray.copy().fill(1.0, 0.0, min, val).avg())
cdfArray
最后,为了确保我们的 eCDF() 方法在包含大小值的数组中正常运行,我们将定义一个方法来规范我们的数组。
此featureScale()方法使用数组min()和range()方法生成一个重新缩放的srcArray拷贝。在调用eCDF()方法之前,我们将使用该方法对数组进行归一化处理:
// @function将`srcArray`中的元素缩放到区间[0,1]。
// @param srcArray (array<float>) 归一化的数组。
// @returns (array<float>) 归一化后的 `srcArray` 拷贝。
method featureScale(array<float> srcArray) =>
float min = srcArray.min()
float rng = srcArray.range()
array<float> scaledArray = array.new<float>()
// 将归一化后的 `元素`值推入`缩放数组`。
for element in srcArray
scaledArray.push((element - min) / rng)
scaledArray
请注意:
·这个方法不包括除以零条件的特殊处理。如果 rng 为 0,数组元素的值将为 na。
下面的完整示例使用我们之前的maintainQueue()方法排列了一个带有sourceInput值、大小为length的sourceArray,使用featureScale()方法对数组元素进行归范化,然后调用eCDF()方法获取分布上n个均匀间隔分布的估计值的数组。然后,脚本调用用户定义的makeLabel()函数,在图表右侧的标签中显示估计值和价格:
//@version=5
indicator("Empirical Distribution", overlay = true)
float sourceInput = input.source(close, "Source")
int length = input.int(20, "Length")
int n = input.int(20, "Steps")
// @function 维护一个特定大小的数组`srcArray` 。
// 它向数组追加一个 `value` 并移除位于零位的最旧元素。
// @param srcArray (array<float>) 被维持的数组。
// @param value (float)要添加到数组中的新值。
// 数组中最老的值也会被移除,因此其大小不变。
// @param takeSample (bool)该参数为true时,新 `value` 才会被推入数组。
// @returns (array<float>) `srcArray` 对象。
method maintainQueue(array<float> srcArray, float value, bool takeSample = true) =>
if takeSample
srcArray.push(value)
srcArray.shift()
srcArray
// @function 用`innerValue`替换`lowerBound`和`upperBound`之间的元素
// 并用 `outerValue` 替换超出范围的元素。
// @param srcArray (array<float>) 要修改的数组。
// @param innerValue (float) 要替换范围内元素的值。
// @param outerValue (float) 用来替换范围外元素的值。
// @param lowerBound (float) 用 `innerValue` 替换的最小值。--min
// @param upperBound (float) 替换为 `innerValue` 的最高值。--val分层变化
// @returns (array<float>) `srcArray` 对象。
method fill(array<float> srcArray, float innerValue, float outerValue, float lowerBound, float upperBound) =>
for [i, element] in srcArray
if (element >= lowerBound or na(lowerBound)) and (element <= upperBound or na(upperBound))
srcArray.set(i, innerValue)
else
srcArray.set(i, outerValue)
srcArray
// @function 估算 `srcArray` 的经验CDF。
// @param srcArray (array<float>) 要计算的数组。
// @param steps (int) 估算步骤数。
// @returns (array<float>) CDF 估计比率数组。
method eCDF(array<float> srcArray, int steps) =>
float min = srcArray.min()
float rng = srcArray.range() / steps
array<float> cdfArray = array.new<float>()
// 在 `cdfArray` 中添加按值区域筛选的 `srcArray` 平均值。
float val = min
for i = 1 to steps
val += rng
cdfArray.push(srcArray.copy().fill(1.0, 0.0, min, val).avg())
cdfArray
// @function 将 `srcArray` 中的元素比例调整为区间 [0, 1]。
// @param srcArray (array<float>) 归一化的数组。
// @returns (array<float>) 归一化后的 `srcArray` 拷贝。
method featureScale(array<float> srcArray) =>
float min = srcArray.min()
float rng = srcArray.range()
array<float> scaledArray = array.new<float>()
// 将规范化的`元素`值推入`缩放数组`.
for element in srcArray
scaledArray.push((element - min) / rng)
scaledArray
// @function 绘制包含 eCDF 估计值的标签,格式为{price}: {percent}%
// @param srcArray (array<float>) 源值数组。
// @param cdfArray (array<float>) CDF 估计值数组。
// @returns (void)
makeLabel(array<float> srcArray, array<float> cdfArray) =>
float max = srcArray.max()
float rng = srcArray.range() / cdfArray.size()
string results = ""
var label lbl = label.new(0, 0, "", style = label.style_l abel_left, text_font_family = font.family_monospace)
// 从 `max` 开始向 `results` 添加百分比 string.
cdfArray.reverse()
for [i, element] in cdfArray
results += str.format("{0}: {1}%\n", max - i * rng, element * 100)
// 更新 `lbl` 属性.
lbl.set_xy(bar_index + 1, srcArray.avg())
lbl.set_text(results)
var array<float> sourceArray = array.new<float>(length)
// 为最后length长度的K线添加背景色.
bgcolor(bar_index > last_bar_index - length ? color.new(color.orange, 80) : na)
// 对 `sourceArray` 进行排队、特征缩放,然后估算 `n` 步的分布。
array<float> distArray = sourceArray.maintainQueue(sourceInput).featureScale().eCDF(n)
// 绘制标签.
makeLabel(sourceArray, distArray)
数组
数组简介
Pine Script® 数组是一种一维集合,可以容纳多个值的引用。数组可以更好地处理那些需要明确声明一组类似变量的情况(例如,price00、price01、price02......)。
数组中的所有元素必须具有相同的类型,可以是内置类型或用户自定义类型,通常为"series"形式。脚本引用数组时使用的数组ID ,其与lines、labels和其他特殊类型的ID相似。Pine Script®不使用索引操作符来引用单个数组元素。然而, array.get() 和 array.set() 在内的函数可以读写数组元素的值。我们可以在允许使用"series"形式的表达式和函数中使用数组值。
脚本使用索引来引用数组中的元素,索引从 0 开始,直到数组中元素的数量减去 1。Pine Script® 中的数组可以有一个动态大小,该大小在各条之间变化,因为在脚本的每次迭代中都可以改变数组中元素的数量。脚本可以包含多个数组实例。数组的大小限制为 100,000 个元素。
注:
我们将使用数组的开头定为索引 0,数组的结尾为索引值最高的数组元素。为了简洁起见,我们还将扩展数组的含义,使其包括数组 ID。
声明数组
Pine Script® 使用以下语法声明数组:
[var/varip ][array<type>/<type[]> ]<identifier> = <expression>
其中 <type> 是数组的类型模板,它声明了数组将包含的值的类型,而 <expression> 返回指定类型的数组或 na。
在将变量声明为数组时,我们可以使用数组关键字,然后是类型模板。或者,我们也可以使用类型名称,后面跟 [] 修饰符(不要与 [] 历史引用操作符混淆)。
由于 Pine 总是使用特定类型的函数来创建数组,因此声明中的 array<type>/type[] 部分是多余的,除非是在声明分配给 na 的数组变量时。即使不需要,明确声明数组类型也有助于向读者清楚地表达意图。
这行代码声明了一个指向 na 的名为 prices 的数组变量。在这种情况下,我们必须指定类型,以声明变量可以引用包含 "float "值的数组:
array<float> prices = na
我们也可以把上面的例子写成这种形式:
float[] prices = na
在声明数组且<expression>不是na时,请使用以下函数之一:array.new<type>(size, initial_value)、array.from()或array.copy()。对于 array.new<type>(size, initial_value)函数,size 和 initial_value 参数的参数可以是"series",以便动态调整数组元素的大小和初始化。下面的示例创建了一个包含0个"float"元素的数组,这次,调用array.new<float>()函数返回的数组ID被赋值给prices:
prices = array.new<float>(0)
array.* 命名空间还包含创建数组的特定类型函数,包括array.new_int()、array.new_float()、array.new_bool()、array.new_color()、array.new_string()、array.new_line()、array.new_linefill()、array.new_label()、array.new_box() 和 array.new_table()。array.new<type>() 函数可以创建任何类型的数组,包括用户定义的类型。
array.new* 函数的 initial_value 参数允许用户将数组中的所有元素设置为指定值。如果没有为 initial_value 提供参数,数组将以 na 值填充。
这一行声明了一个名为 prices 的数组 ID,指向一个包含两个元素的数组,每个元素都分配给K线的收盘价:
prices = array.new<float>(2, close)
要创建一个数组并用不同的值初始化其元素,请使用 array.from()。该函数根据函数调用中的参数推断出数组的大小和元素类型。与 array.new* 函数一样,它接受 "series"参数。提供给函数的所有值必须是同一类型。
例如,所有这三行代码都将创建具有相同两个元素的相同 "bool "数组:
statesArray = array.from(close > open, high != close)
bool[] statesArray = array.from(close > open, high != close)
array<bool> statesArray = array.from(close > open, high != close)
使用 `var` 和 `varip` 关键字
用户可以使用var和varip关键字来指示脚本只在第一个K线的第一次迭代中声明一次数组变量。使用这些关键字声明的数组变量指向相同的数组实例,直到明确地重新赋值为止,从而使数组及其元素引用在不同K线之间保持不变。
使用这些关键字声明数组变量,并在每个K线上将新值推送到引用数组的末尾时,数组将在每个K线上增长一个,并在最后一个K线上执行脚本时大小为 bar_index + 1(bar_index 从 0 开始),如本代码所示:
/@version=5
indicator("Using `var`")
//@variable 一个数组,每增加一个K线,其大小就增加 1。
var a = array.new<float>(0)
array.push(a, close)
if barstate.islast
//@variable 包含 `a` 大小和当前 `bar_index` 值的string。
string labelText = "Array size: " + str.tostring(a.siz e()) + "\nbar_index: " + str.tostring(bar_index)
//显示`labelText`.
label.new(bar_index, 0, labelText, size = size.large)
如果不使用var关键字,代码会在每个K线上重新声明数组。这种情况下执行array.push()后,a.size()将返回值1。
注意:
使用 varip 声明的数组变量与使用 var 声明的数组变量在历史数据上的行为相同,但会在每个新的价格刻度上更新实时K线(即自脚本上次编译以来的K线)的值。分配给 varip 变量的数组只能包含 int、float、bool、color 或string类型,或在字段中专门包含这些类型或这些类型的集合(数组、矩阵或映射)的用户定义类型。
读写数组元素
脚本可以使用 array.set(id, index, value) 向现有的单个数组元素写入值,也可以使用 array.get(id, index) 读取值。使用这些函数时,函数调用中的索引必须始终小于或等于数组的大小(因为数组索引从零开始)。要获取数组的大小,请使用 array.size(id) 函数。
下面的示例使用set()方法在fillColors数组中填充了不同透明度级别的一种基色的实例。然后使用array.get(),根据最后一个回溯输入K线中价格最高的K线的位置,从数组中获取其中一种颜色:
//@version=5
indicator("Distance from high", "", true)
lookbackInput = input.int(100)
FILL_COLOR = color.green
// 声明数组并仅在第一K线设置其值.
var fillColors = array.new<color>(5)
if barstate.isfirst
// 用逐渐变浅的填充颜色初始化数组元素。
fillColors.set(0, color.new(FILL_COLOR, 70))
fillColors.set(1, color.new(FILL_COLOR, 75))
fillColors.set(2, color.new(FILL_COLOR, 80))
fillColors.set(3, color.new(FILL_COLOR, 85))
fillColors.set(4, color.new(FILL_COLOR, 90))
(math.floor()小于等于某数的整数)
// 找出最高点的偏移量。 改变其符号,因为函数返回的是负值.
lastHiBar = - ta.highestbars(high, lookbackInput)
// 将偏移量转换为数组索引,上限为 4 以避免运行时出错。
// `array.get()`使用的索引将等同于 `math.floor(fillNo)`。
fillNo = math.min(lastHiBar / (lookbackInput / 5), 4)
// 随着与最高点的距离增加,将背景设置为逐渐变浅的填充。
bgcolor(array.get(fillColors, fillNo)) //get()返回int
// 将键值绘制到数据窗口,以便调试。
plotchar(lastHiBar, "lastHiBar", "", location.top, size = size.tiny)
plotchar(fillNo, "fillNo", "", location.top, size = size.tiny)
另一种初始化数组元素的方法是创建一个空数组(没有元素的数组),然后使用 array.push() 将新元素追加到数组的末尾,每次调用都会使数组的大小增加一个。下面的代码与前面脚本中的初始化部分功能相同:
// 声明数组并仅在第一个K线设置其值。
var fillColors = array.new<color>(0)
if barstate.isfirst
// 用逐渐变浅的填充颜色初始化数组元素.
array.push(fillColors, color.new(FILL_COLOR, 70))
array.push(fillColors, color.new(FILL_COLOR, 75))
array.push(fillColors, color.new(FILL_COLOR, 80))
array.push(fillColors, color.new(FILL_COLOR, 85))
array.push(fillColors, color.new(FILL_COLOR, 90))
这段代码等同于上面的代码,但它使用 array.unshift() 在 fillColors 数组的开头插入新元素:
// Declare array and set its values on the first bar only.
var fillColors = array.new<color>(0)
if barstate.isfirst
// 用逐渐变浅的填充颜色初始化数组元素.
array.unshift(fillColors, color.new(FILL_COLOR, 90))
array.unshift(fillColors, color.new(FILL_COLOR, 85))
array.unshift(fillColors, color.new(FILL_COLOR, 80))
array.unshift(fillColors, color.new(FILL_COLOR, 75))
array.unshift(fillColors, color.new(FILL_COLOR, 70))
我们还可以使用 array.from(),只需调用一次函数即可创建相同的 fillColors 数组:
//@version=5
indicator("Using `var`")
FILL_COLOR = color.green
var color[] fillColors = array.from(
color.new(FILL_COLOR, 70),
color.new(FILL_COLOR, 75),
color.new(FILL_COLOR, 80),
color.new(FILL_COLOR, 85),
color.new(FILL_COLOR, 90)
)
// 在数组颜色的背景中循环.
bgcolor(array.get(fillColors, bar_index % (fillColors.size())))
array.fill(id,value,index_from,index_to)函数将所有数组元素或 index_from 至 index_to 范围内的元素指向指定的值。如果没有后两个可选参数,函数将填充整个数组,因此:
a = array.new<float>(10, close)
和
a = array.new<float>(10)
a.fill(close)
是等价的,但是:
a = array.new<float>(10)
a.fill(close, 1, 3)
只填充数组的第二和第三个元素(索引 1 和 2)。请注意 array.fill() 的最后一个参数 index_to 必须大于函数要填充的最后一个索引。其余元素将保持 na 值,因为 array.new() 函数调用不包含 initial_value 参数。
//a.fill(close) 等价于 a.fill(close, 0, 11)
循环遍历数组元素
当循环遍历数组的元素索引且数组的大小未知时,可以使用 array.size() 函数获取最大索引值。例如:
//@version=5
indicator("Protected `for` loop", overlay = true)
//@variable 1 分钟时间框架中的 "close"价格数组。
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
//@variable a中元素的string表示法.
string labelText = ""
for i = 0 to (array.size(a) == 0 ? na : array.size(a) - 1)
labelText += str.tostring(array.get(a, i)) + "\n"
label.new(bar_index, high, text = labelText)
请注意:
l 我们使用 request.security_lower_tf() 函数,该函数返回 1 分钟时间框架的收盘价数组。
l 如果在小于1分钟的图表时间框架上使用此代码,则会出错。
l for 循环在 to 表达式为 na 时不执行。请注意,to 值只在进入时评估一次。
在数组中循环的另一种方法是使用 for...in 循环。这种方法是标准 for 循环的一种变体,可以遍历数组中的值引用和索引。下面的示例说明了如何使用 for...in 循环编写上面的代码示例:
indicator("`for...in` loop", overlay = true)
//@variable 1 分钟时间框架中的 "收盘 "价格数组。
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
//@variable 表示 `a` 中元素的string.
string labelText = ""
for price in a
labelText += str.tostring(price) + "\n"
label.new(bar_index, high, text = labelText)
· for...in 循环可以返回包含每个索引和相应元素的元组。例如,for [i, price] in a 返回 a 中每个元素的 i 索引和价格值。
也可以使用 while 循环语句:
//@version=5
indicator("`while` loop", overlay = true)
array<float> a = request.security_lower_tf(syminfo.tickerid, "1", close)
string labelText = ""
int i = 0
while i < array.size(a)
labelText += str.tostring(array.get(a, i)) + "\n"
i += 1
label.new(bar_index, high, text = labelText)
作用域
用户可以在脚本的全局作用域以及函数、方法和条件结构的局部作用域中声明数组。与其他一些内置类型(即基本类型)不同,脚本可以在局部范围内修改全局分配的数组,从而允许用户实现脚本中任何函数都可以直接交互的全局变量。我们在此使用该功能来计算逐步降低或提高的价格水平:
//@version=5
indicator("Bands", "", true)
//@variable 绘制的价格水平之间的距离比.
factorInput = 1 + (input.float(-2., "Step %") / 100)
//@variable 单值数组,偏移10个K线,从50个K线中保存最低ohlc4值
level = array.new<float>(1, ta.lowest(ohlc4, 50)[10])
nextLevel(val) =>
newLevel = level.get(0) * val
//将新级别写入全局level数组,以便在下一次函数调用中将其作为基数.
level.set(0, newLevel)
newLevel
plot(nextLevel(1))
plot(nextLevel(factorInput))
plot(nextLevel(factorInput))
plot(nextLevel(factorInput))
历史引用
Pine Script®的历史引用操作符[ ]可以访问数组变量的历史,允许脚本与之前分配给变量的数组实例交互。
为了说明这一点,让我们创建一个简单的示例,展示如何通过两种等效的方式获取上一K线的收盘价。该脚本使用[ ]操作符获取上一交易日分配给a的数组实例,然后使用get()方法获取第一个元素(previousClose1)的值。对于previousClose2,我们直接在 close 变量上使用历史引用运算符来获取值。从图表中我们可以看到,previousClose1和 previousClose2都返回相同的值:

//@version=5
indicator("History referencing")
//@variable 在每个K线上声明的单值数组.
a = array.new<float>(1)
// 将 `a` 中唯一元素的值设置为 `close`.
array.set(a, 0, close)
//@variable 上一K线中分配给`a`的数组实例
previous = a[1]
previousClose1 = na(previous) ? na : previous.get(0)
previousClose2 = close[1]
plot(previousClose1, "previousClose1", color.gray, 6)
plot(previousClose2, "previousClose2", color.white, 2)
插入和删除数组元素
插入
以下三个函数可以在数组中插入新元素。
array.unshift() 在数组的开头(索引 0)插入一个新元素,并将任何现有元素的索引值增加一个。
array.insert() 在指定的索引处插入一个新元素,并将该索引处和其后的现有元素的索引值增加一个。

//@version=5
indicator("`array.insert()`")
a = array.new<float>(5, 0)
for i = 0 to 4
array.set(a, i, i + 1)
if barstate.islast
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a), size = size.large)
array.insert(a, 2, 999)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a), style = label.style_label_up, size = size.large)
array.push() 在数组末尾添加一个新元素。
删除
以下四个函数用于删除数组中的元素。前三个函数还会返回被移除元素的值。
array.remove() 删除指定索引处的元素,并返回该元素的值。
array.shift() 从数组中移除第一个元素并返回其值。
array.pop() 删除数组的最后一个元素并返回其值。
array.clear() 删除数组中的所有元素。请注意,清除数组不会删除其元素引用的任何对象。请参阅下面的示例,了解其工作原理:
//@version=5
indicator("`array.clear()` example", overlay = true)
// 创建标签数组,并在每个新的K线上将标签添加到数组中.
var a = array.new<label>()
label lbl = label.new(bar_index, high, "Text", color = color.red)
array.push(a, lbl)
var table t = table.new(position.top_right, 1, 1)
// 清除最后一个K线的数组。 这不会删除图表中的标签.
if barstate.islast
array.clear(a)
table.cell(t, 0, 0, "Array elements count: " + str.tostring(array.size(a)), bgcolor = color.yellow)
将数组用作堆栈
堆栈是LIFO(后进先出)结构。它们的行为有点像一堆竖放的书,每次只能从最上面一本一本地添加或移除。Pine Script®数组可用作堆栈,在这种情况下,我们使用array.push()和array.pop()函数在数组末尾添加和删除元素。
array.push(prices, close) 将在价格数组的末尾添加一个新元素,使数组的大小增加一个。
array.pop(prices) 将从价格数组中移除末尾元素,返回其值并将数组的大小减小一个。
查看此处如何使用这些函数来跟踪反弹中的连续低点:
@version=5
indicator("Lows from new highs", "", true)
var lows = array.new<float>(0)
flushLows = false
// 当 `_cond`为真时,从堆栈中移除最后一个元素.
array_pop(id, cond) => cond and array.size(id) > 0 ? array.pop(id) : float(na)
if ta.rising(high, 1)
// 不断攀升的高点;将堆栈推向新的低点。
lows.push(low)
// 强制此 "if"代码块的返回类型与下一个代码块的返回类型相同
bool(na)
else if lows.size() >= 4 or low < array.min(lows)
// 我们至少有 4 个低点或价格已突破最低低点;
// 对低点进行排序,并设置标志,表示我们将绘制并刷新水平线。
array.sort(lows, order.ascending)
flushLows := true
// 必要时,绘制并冲洗低点。
lowLevel = array_pop(lows, flushLows)
plot(lowLevel, "Low 1", low > lowLevel ? color.silver : color.purple, 2, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 2", low > lowLevel ? color.silver : color.purple, 3, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 3", low > lowLevel ? color.silver : color.purple, 4, plot.style_linebr)
lowLevel := array_pop(lows, flushLows)
plot(lowLevel, "Low 4", low > lowLevel ? color.silver : color.purple, 5, plot.style_linebr)
if flushLows
// 绘制完最后 4 个图层后,清除剩余图层.
lows.clear()
将数组用作队列
队列是 FIFO(先进先出)结构。它们的行为有点像汽车闯红灯。新的汽车排在队列的末尾,第一辆离开的汽车将是第一辆到达红灯的汽车。
在下面的代码示例中,我们让用户通过脚本的输入来决定希望在图表上有多少个标签。我们使用这个数量来决定随后创建的标签数组的大小,并将数组的元素初始化为 na。
当检测到一个新的枢轴点时,我们会为其创建一个标签,并将标签的ID保存在pLabel变量中。然后,我们使用array.push()将新标签的ID添加到数组的末尾,使数组的大小比图表上要保留的最大标签数多一个,从而将该标签的ID排入数组。
最后,我们使用 array.shift() 删除数组的第一个元素,并删除该数组元素值所引用的标签,从而取消对最旧标签的排队。现在我们已经从数组中删除了一个元素,数组中再次包含了 pivotCountInput 元素。请注意,在数据集的第一个K线中,我们将删除 na 标签 ID,直到创建了最大标签数为止,但这不会导致运行时出错。让我们看看我们的代码:
//@version=5
MAX_LABELS = 100
indicator("Show Last n High Pivots", "", true, max_labels_count = MAX_LABELS)
pivotCountInput = input.int(5, "How many pivots to show", minval = 0, maxval = MAX_LABELS)
pivotLegsInput = input.int(3, "Pivot legs", minval = 1, maxval = 5)
// 创建一个数组,其中包含用户选择的标签 ID 最大计数.
var labelIds = array.new<label>(pivotCountInput)
pHi = ta.pivothigh(pivotLegsInput, pivotLegsInput)
if not na(pHi)
// 找到新的枢轴点;在此绘制其标签(偏移pivotLegs条K线).
pLabel = label.new(bar_index[pivotLegsInput], pHi, str.tostring(pHi, format.mintick), textcolor = color.white)
// 将新标签的 ID 添加到数组末尾,使其成为数组.
array.push(labelIds, pLabel)
//数组中删除最旧的标签ID(shift),并删除相应标签(delete)
label.delete(array.shift(labelIds))
数组计算
Series变量可以被看作是一组水平的时间值,而Pine Script®的一维数组则可以被看作是驻留在每个K线上的垂直结构。由于数组的元素集不是时间序列,因此不能使用Pine Script®的常用数学函数。必须使用专用函数才能对数组的所有值进行运算。可用的函数有:array.abs(), array.avg(),array.covariance(), array.min(), array.max(), array.median(),array.mode(),array.percentile_linear_interpolation(),array.percentile_nearest_rank(),array.percentrank(),array.range(),array.standardize(),array.stdev(), array.sum(), array.variance()。
请注意,与 Pine Script®中常用的数学函数相反,数组函数在计算某些值时不会返回na值。但也有一些例外情况:
· 当所有数组元素都有na值或数组不包含任何元素时,将返回na。然而,array.standardize()将返回一个空数组。
· array.mode()在找不到模式时会返回 na。
操纵数组
连接
两个数组可以通过 array.concat() 进行合并或连接。连接数组时,第二个数组会追加到第一个数组的末尾,因此第一个数组被修改,而第二个数组保持不变。该函数返回第一个数组的数组 ID:

/@version=5
indicator("`array.concat()`")
a = array.new<float>(0)
b = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(b, 2)
array.push(b, 3)
if barstate.islast
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a) + "\nb: " + str.tostring(b), size = size.large)
c = array.concat(a, b)
array.push(c, 4)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a) + "\nb: " + str.tostring(b) + "\nc: " + str.tostring(c), style = label.style_label_up, size = size.large)
复制
使用 array.copy() 可以复制数组。在这里,我们将数组 a 复制到一个名为 _b 的新数组中:

//@version=5
indicator("`array.copy()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
if barstate.islast
_b = array.copy(a)
array.push(_b, 2)
label.new(bar_index, 0, "a: " + str.tostring(a) + "\n_ b: " + str.tostring(_b), size = size.large)
请注意,在上面的示例中,如果使用 _b = a,就不会复制数组,而只会复制数组的 ID。从那时起,两个变量都指向同一个数组,因此使用其中任何一个变量都会影响同一个数组。
连接
使用 array.join() 将数组中的所有元素连接成一个string,并用指定的分隔符分隔这些元素:
//@version=5
indicator("")
v1 = array.new<string>(10, "test")
v2 = array.new<string>(10, "test")
array.push(v2, "test1")
v3 = array.new_float(5, 5)
v4 = array.new_int(5, 5)
l1 = label.new(bar_index, close, array.join(v1))
l2 = label.new(bar_index, close, array.join(v2, ","))
l3 = label.new(bar_index, close, array.join(v3, ","))
l4 = label.new(bar_index, close, array.join(v4, ","))
排序
包含 "int "或 "float "元素的数组可以使用 array.sort() 按升序或降序排序。order 参数是可选的,默认为 order.ascending。与所有 array.*() 函数参数一样,它的形式为 "series",因此可以在运行时确定,此处就是这样做的。请注意,在示例中,哪个数组被排序也是在运行时确定的:
//@version=5
indicator("`array.sort()`")
a = array.new<float>(0)
b = array.new<float>(0)
array.push(a, 2)
array.push(a, 0)
array.push(a, 1)
array.push(b, 4)
array.push(b, 3)
array.push(b, 5)
if barstate.islast
barUp = close > open
array.sort(barUp ? a : b, barUp?order.ascending:order.descending)
label.new(bar_index, 0,
"a " + (barUp ? "is sorted ▲: " : "is not sorted: ") + str.tostring(a) + "\n\n" +
"b " + (barUp ? "is not sorted: " : "is sorted ▼: ") + str.tostring(b), size = size.large)
另一个有用的数组排序方法是array.sort_indices()函数,该函数接收原始数组的引用,并返回一个包含原始数组索引的数组。请注意,该函数不会修改原始数组。order参数是可选的,默认为order.ascending。
反转
使用 array.reverse() 可以反转数组:
//@version=5
indicator("`array.reverse()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
if barstate.islast
array.reverse(a)
label.new(bar_index, 0, "a: " + str.tostring(a))
切分
使用 array.slice() 对数组进行切分,可以创建父数组子集的浅层拷贝。你可以使用 index_from 和 index_to 参数确定要切分的子集的大小。index_to 参数必须大于要切分的子集的末尾。
切分创建的浅层拷贝就像是父数组内容的窗口。用于切分的索引定义了窗口在父数组中的位置和大小。在下面的示例中,如果从数组的前三个元素(索引 0 至 2)创建切分,那么无论父数组发生什么变化,只要它至少包含三个元素,浅层拷贝将始终包含父数组的前三个元素。
此外,一旦创建了浅层拷贝,对拷贝的操作将与对父数组的操作如出一辙。在浅层拷贝的末尾添加一个元素,就像下面示例中做的那样,会将窗口扩大一个元素,同时将该元素插入索引为 3 的父数组中。在本例中,要切分数组 a 的索引0至索引2的子集,我们必须使用_sliceOfA = array.slice(a,0,3):
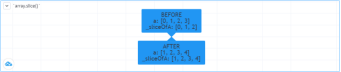
//@version=5
indicator("`array.slice()`")
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
array.push(a, 3)
if barstate.islast
// 从数组 `a` 中截取索引0至索引2的元素创建一个影子数组.
_sliceOfA = array.slice(a, 0, 3)
label.new(bar_index, 0, "BEFORE\na: " + str.tostring(a) + "\nsliceOfA: " + str.tostring(_sliceOfA))
// 删除父数组 `a` 的第一个元素.
array.remove(a, 0)
// 在浅层拷贝的末尾添加一个新元素,从而也影响原始数组 `a`.
array.push(_sliceOfA, 4)
label.new(bar_index, 0, "AFTER\na: " + str.tostring(a) + "\nsliceOfA: " + str.tostring(_sliceOfA), style = label.style_label_up)
搜索数组
我们可以使用数组.includes()函数测试一个值是否是数组的一部分,如果找到该元素,则返回true。我们可以使用array.indexof()函数查找数组中首次出现的值。第一个出现的值是索引最小的值。我们还可以使用 array.lastindexof() 函数查找最后出现的值:
//@version=5
indicator("Searching in arrays")
valueInput = input.int(1)
a = array.new<float>(0)
array.push(a, 0)
array.push(a, 1)
array.push(a, 2)
array.push(a, 1)
if barstate.islast
valueFound = array.includes(a, valueInput)
firstIndexFound = array.indexof(a, valueInput)
lastIndexFound = array.lastindexof(a, valueInput)
label.new(bar_index, 0, "a: " + str.tostring(a) +
"\nFirst " + str.tostring(valueInput) + (valueFound ? " value was found at index: " + str.tostring(firstIndexFound) : " value was not found.") +
"\nLast " + str.tostring(valueInput) + (valueFound ? " value was found at index: " + str.tostring(lastIndexFound) : " value was not found."))
我们也可以在数组上执行二进制搜索,但要注意的是,在数组上执行二进制搜索意味着首先需要对数组进行升序排序。如果找到了值,array.binary_search()函数将返回该值的索引;如果没有找到,则返回-1。如果我们希望即使没有找到我们选择的值,也始终返回数组中已有的索引,那么我们可以使用其他可用的二进制搜索函数。array.binary_search_leftmost()函数如果找到了值,则返回一个索引,如果没有找到值,则返回左边的第一个索引。array.binary_search_rightmost()函数几乎完全相同,如果找到了值,则返回一个索引,如果没有,则返回右边的第一个索引。
错误处理
保存脚本时,Pine 脚本中调用语法缺陷的array.*()会导致在Pine Script® Editor的控制台(位于窗口底部)出现编译器错误信息。如果对函数调用的确切语法有疑问,请参阅《Pine Script® v5 参考手册》。
使用数组的脚本也会出现运行时错误,会在图表中指标名称旁显示一个!。我们将在本节讨论这些运行时错误。
索引 xx 越界。数组大小为 yy
这可能是你最常遇到的错误。当你引用一个不存在的数组索引时,就会发生这种情况。xx 值是你试图使用的错误索引的值,"yy"是数组的大小。回想一下,数组索引的起点是0,而不是1,终点是数组的大小减1。因此,大小为 3 的数组的最后一个有效索引是 2。
要避免这个错误,必须在代码逻辑中做出规定,防止使用数组索引边界之外的索引。这段代码会产生错误,因为在循环中使用的最后一个索引超出了数组的有效索引范围:
//@version=5
indicator("Out of bounds index")
a = array.new<float>(3)
for i = 1 to 3
array.set(a, i, i)
plot(array.pop(a))
正确的说法是:
for i = 0 to 2
要循环处理未知大小数组中的所有数组元素,请使用:
//@version=5
indicator("Protected `for` loop")
sizeInput = input.int(0, "Array size", minval = 0, maxval = 100000)
a = array.new<float>(sizeInput)
for i = 0 to (array.size(a) == 0 ? na : array.size(a) - 1)
array.set(a, i, i)
plot(array.pop(a))
使用"设置/输入"选项卡字段动态调整数组大小时,请使用input.int()的minval和maxval参数保护该值的边界:
//@version=5
indicator("Protected array size")
sizeInput = input.int(10, "Array size", minval = 1, maxval = 100000)
a = array.new<float>(sizeInput)
for i = 0 to sizeInput - 1
array.set(a, i, i)
plot(array.size(a))
更多信息,请参阅本章节的循环部分。
当数组ID为"na"时,无法调用数组方法
当数组ID初始化为na时,由于不存在数组,因此不允许对其进行操作。此时存在的只是一个包含na值的数组变量,而不是一个指向现有数组的有效数组ID。但在使用a = array.new_int(0)时创建的数组中没有任何元素,但仍有一个有效的ID。这段代码将引发我们正在讨论的错误:
//@version=5
indicator("Out of bounds index")
int[] a = na
array.push(a, 111)
label.new(bar_index, 0, "a: " + str.tostring(a))
为避免出现这种情况,请使用以下命令创建一个大小为0的数组:
int[] a = array.new_int(0) //or:
a = array.new_int(0)
阵列太大。最大值为 100000
如果代码试图声明一个大小超过 100,000 的数组,则会出现此错误。如果在向数组动态追加元素时,新元素会使数组的大小超过最大值,也会出现此错误。
无法创建负大小的数组
我们还没有发现负值数组的用途,但如果您发现了,我们可能会允许使用负值数组:)
如果数组为空,则无法使用 shift()。
调用array.shift()删除空数组的第一个元素,会出现此错误。
如果数组为空,则不能使用 pop()。
调用array.pop()删除空数组的最后一个元素,将发生此错误。
索引from应小于索引to
在 array.slice() 等函数中使用两个索引时,第一个索引必须始终小于第二个索引。
切分超出了父数组的范围
每当父数组的大小被修改,使得切分创建的浅层拷贝指向父数组的边界之外时,就会出现这条信息。这段代码会重现这种情况,因为在从索引3到4(五元素父数组的最后两个元素)创建切分后,我们删除了父数组的第一个元素,使其大小为4,最后一个索引为 3。从那时起,仍然指向父数组索引3至4处"窗口"的浅层拷贝就指向了父数组的边界之外:
/@version=5
indicator("Slice out of bounds")
a = array.new<float>(5, 0)
b = array.slice(a, 3, 5)
array.remove(a, 0)
c = array.indexof(b, 2)
plot(c)
矩阵
矩阵简介
Pine Script® 矩阵是以矩形格式存储数值引用的集合。矩阵本质上等同于二维数组对象,具有用于检查、修改和特殊计算的函数和方法。与数组一样,所有矩阵元素必须是同一类型,可以是内置类型,也可以是用户定义类型。
矩阵使用两个索引来引用元素:一个索引表示行,另一个表示列。每个索引从0开始,直到矩阵的行/列数减去 1。Pine中的矩阵可以有动态的行数和列数,这些行数和列数在不同的K线中会有所不同。矩阵中元素的总数是行数和列数的乘积(例如,一个5x5矩阵共有25个元素)。与数组一样,矩阵中的元素总数不能超过100,000。
声明矩阵
Pine Script® 使用以下语法声明矩阵:
[var/varip ][matrix<type> ]<identifier> = <expression>
其中<type>是矩阵的类型模板,它声明了矩阵将包含的值的类型,而<expression>则返回该类型的矩阵实例或na。
在以na类型声明矩阵变量时,用户必须指定标识符将引用特定类型的矩阵,方法是在矩阵关键字后加上类型模板。
这一行声明了一个新的 myMatrix 变量,其值为na。它明确地将变量声明为 matrix<float>,告诉编译器该变量只能接受包含浮点值的矩阵对象:
matrix<float> myMatrix = na
当矩阵变量没有赋值给na时,matrix关键字及其类型模板是可选的,因为编译器将使用变量引用对象的类型信息。
在这里,我们声明了一个myMatrix变量,它引用了一个新的matrix<float>实例,该实例有两行两列,initial_value为0:
myMatrix = matrix.new<float>(2, 2, 0.0)
使用 `var` 和 `varip` 关键字
与其他变量一样,用户可以使用var或varip关键字来指示脚本只声明一次矩阵变量,而不是在每个K线上都声明一次。使用该关键字声明的矩阵变量将在图表的整个时间跨度内指向同一个实例,除非脚本明确为其分配了另一个矩阵,从而允许矩阵及其元素引用在脚本迭代之间持续存在。
此脚本使用var关键字声明了一个m变量,并将其分配给一个包含两行int元素的矩阵。每隔20个K线,脚本会在m矩阵第一行的第一个元素上加1。调用plot()会在图表上显示这个元素。从图表中我们可以看到,m.get(0, 0)的值在两个K线之间持续存在,从未返回到初始值 0:
//@version=5
indicator("var matrix demo")
//@variable 仅在Bar_index ==0时声明1x2矩阵,即第一条K线时.
var m = matrix.new<int>(1, 2, 0)
//@variable 每隔 20 个K线为 true.
bool update = bar_index % 20 == 0
if update
int currentValue = m.get(0, 0)//获取第一行第一列的当前值
// 将第一行第一列的元素值设置为 "currentValue + 1.
m.set(0, 0, currentValue + 1)
// 绘制第一行第一列的数值.
plot(m.get(0, 0), linewidth = 3)
使用varip与使用var声明的矩阵变量在历史数据上的行为相同,但它们会在每个新的价格刻度上更新实时K线(即自脚本上次编译以来的K线)的值。分配给varip变量的矩阵只能包含int、float、bool、color或string类型,或在字段中专门包含这些类型或这些类型集合(数组、矩阵或映射)的用户定义类型。
读写矩阵元素
`matrix.get()`和`matrix.set()`
要从矩阵中获取指定行和列索引的值,请使用 matrix.get()。该函数会定位指定的矩阵元素并返回其值。同样,要覆盖特定元素的值,可使用matrix.set()为指定行和列的元素赋一个新值。
下面的示例定义了一个两行两列的矩阵m,第一列所有元素的初始值均为0。使用m.get()和m.set()方法在不同K线的每个元素值上加1。脚本每11个K线更新一次第一行第一列的值,每7个K线更新一次第一行第二列的值,每5个K线更新一次第二行第一列的值,每3个K线更新一次第二行第二列的值。脚本会将每个元素的值绘制在图表上:
/@version=5
indicator("Reading and writing elements demo")
//@variable 声明一个 2x2 的方形浮点型矩阵
var m = matrix.new<float>(2, 2, 0.0)
switch // 每11个K线,在第0行第0列的数值上加 1
bar_index % 11 == 0 => m.set(0, 0, m.get(0, 0) + 1.0)
bar_index % 7 == 0 => m.set(0, 1, m.get(0, 1) + 1.0) //每7K线0行1列+ 1
bar_index % 5 == 0 => m.set(1, 0, m.get(1, 0) + 1.0) //每5K线1行0列+ 1 .
bar_index % 3 == 0 => m.set(1, 1, m.get(1, 1) + 1.0) //每3K线1行1列加 1.
plot(m.get(0, 0), "Row 0, Column 0 Value", color.red, 2)
plot(m.get(0, 1), "Row 0, Column 1 Value", color.orange, 2)
plot(m.get(1, 0), "Row 1, Column 0 Value", color.green, 2)
plot(m.get(1, 1), "Row 1, Column 1 Value", color.blue, 2)
matrix.fill()
要使用特定值覆盖所有矩阵元素,使用 matrix.fill()。该函数将整个矩阵中或from_row/column和to_row/column索引范围内的所有项指向调用中指定的值。例如,此代码段声明了一个4x4平方矩阵,然后用一个随机值填充其元素:
myMatrix = matrix.new<float>(4, 4)
myMatrix.fill(math.random())
请注意,在使用 matrix.fill() 时,如果矩阵包含特殊类型(行、行填充、标签、方框或表格)或 UDT,所有被替换的元素都将指向函数调用中传递的同一对象。
脚本声明了一个含四行四列的label矩阵,并在第一条K线上填充一个新label对象。每个K线上,将第0行第0列引用的标签的x属性设为bar_index,将第3行第3列引用标签的text属性设为图表上的标签数。虽然矩阵可引用16个(4x4)标签,但每个元素都指向同一个实例,因此图表上只有一个标签,每个K线都会更新其x和text属性:

//@version=5
indicator("Object matrix fill demo")
//@variable A 4x4 label matrix.
var matrix<label> m = matrix.new<label>(4, 4)
// 在第一个K线上为 `m` 添加一个新的标签对象.
if bar_index == 0
m.fill(label.new(0, 0, textcolor = color.white, size = size.huge))
//@variable 图表上标签对象的数量。
int numLabels = label.all.size()
// 将第一行和第一列标签的 `x` 设置为 `bar_index`。
m.get(0, 0).set_x(bar_index)
// 将最后一行和最后一列的标签 "文本 "设置为标签数.
m.get(3, 3).set_text(str.format("Total labels on the chart: {0}", numLabels))
行和列
检索
矩阵可通过 matrix.row() 和 matrix.col() 函数检索特定行或列的所有值。这些函数返回对应维度的数组对象,数组大小取决于矩阵的另一维度,即 matrix.row() 返回数组的大小等于列数,matrix.col() 返回数组的大小等于行数。
下面的脚本在第一K线上填充一个3x2 矩阵m的值1-6。调用m.row()和m.col()访问矩阵的第一行和第一列的数组,并连同数组大小以标签形式显示在图表上:
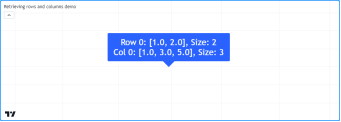
//@version=5
indicator("Retrieving rows and columns demo")
//@variable 一个 3x2 矩形矩阵.
var matrix<float> m = matrix.new<float>(3, 2)
if bar_index == 0
m.set(0, 0, 1.0) // Set row 0, column 0 value to 1.
m.set(0, 1, 2.0) // Set row 0, column 1 value to 2.
m.set(1, 0, 3.0) // Set row 1, column 0 value to 3.
m.set(1, 1, 4.0) // Set row 1, column 1 value to 4.
m.set(2, 0, 5.0) // Set row 1, column 0 value to 5.
m.set(2, 1, 6.0) // Set row 1, column 1 value to 6.
//@variable 矩阵的第一行.
array<float> row0 = m.row(0)
//@variable 矩阵的第一列.
array<float> column0 = m.col(0)
//@variable 在标签中显示矩阵的第一行和第一列及其大小.
var label debugLabel = label.new(0, 0, color = color.blue, textcolor = color.white, size = size.huge)
debugLabel.set_x(bar_index)
debugLabel.set_text(str.format("Row 0: {0}, Size: {1}\nCol 0: {2}, Size: {3}", row0, m.columns(), column0, m.rows()))
请注意:
l 为了获得标签中显示的数组的大小,我们使用了 rows() 和 columns() 方法,而不是 array.size(),以证明 row0 数组的大小等于列数,而 column0 数组的大小等于行数。
matrix.row() 和 matrix.col() 将行/列中的引用复制到一个新数组中。修改这些函数返回的数组不会直接影响矩阵的元素或形状。
我们修改脚本,在显示标签之前,通过array.set()方法将第0行的第一个元素设为10。脚本还绘制了第0行第0列的值。我们看到,标签显示row0数组的第一个元素是10。然而,绘图显示相应矩阵元素的值仍为 1:

//@version=5
indicator("Retrieving rows and columns demo")
//@variable A 3x2 rectangular matrix.
var matrix<float> m = matrix.new<float>(3, 2)
if bar_index == 0
m.set(0, 0, 1.0) // Set row 0, column 0 value to 1.
m.set(0, 1, 2.0) // Set row 0, column 1 value to 2.
m.set(1, 0, 3.0) // Set row 1, column 0 value to 3.
m.set(1, 1, 4.0) // Set row 1, column 1 value to 4.
m.set(2, 0, 5.0) // Set row 1, column 0 value to 5.
m.set(2, 1, 6.0) // Set row 1, column 1 value to 6.
//@variable The first row of the matrix.
array<float> row0 = m.row(0)
//@variable The first column of the matrix.
array<float> column0 = m.col(0)
// 将第一个 `row` 元素设置为 10.
row0.set(0, 10)
//@variable 在标签中显示矩阵的第一行和第一列及其大小.
var label debugLabel = label.new(0, m.get(0, 0), color = color.blue, textcolor = color.white, size = size.huge)
debugLabel.set_x(bar_index)
debugLabel.set_text(str.format("Row 0: {0}, Size: {1}\nCol 0: {2}, Size: {3}", row0, m.columns(), column0, m.rows()))
// 绘制 `m` 的第一个元素.
plot(m.get(0, 0), linewidth = 3)
虽然通过matrix.row()或matrix.col()返回的数组变化不会直接影响父矩阵,但需要注意的是,包含UDT或特殊类型(line, linefill, label, box和table)的矩阵所产生的数组,其行为就像行/列的浅层拷贝,即从这些函数返回的数组中的元素,与相应的矩阵元素指向相同的对象。
该脚本包含一个自定义的myUDT类型,其中包含一个初始值为0的value字段。它声明了一个1x1的矩阵m,用于在第一个K线上保存一个myUDT实例,然后调用m.row(0) 将矩阵的第一行复制为一个数组。在每个K线上,脚本都会向数组的第一个元素的value字段的值加 1。在这种情况下,由于两个元素都引用了同一个对象,因此矩阵元素的value字段在每个K线上都会增加:
//@version=5
indicator("Row with reference types demo")
//@type 自定义类型,用于保存浮点数值.
type myUDT
float value = 0.0
//@variable myUDT "类型的 1x1 矩阵.
var matrix<myUDT> m = matrix.new<myUDT>(1, 1, myUDT.new())
//@variable 矩阵m的第一行的浅层拷贝.---数组Row
array<myUDT> row = m.row(0)
//@variable 数组row的第一个元素.
myUDT firstElement = row.get(0)
firstElement.value += 1.0 //firstElement值加1。影响矩阵元素
plot(m.get(0, 0).value, linewidth = 3)//绘制m第一行第一列值
插入
脚本可以通过matrix.add_row()和matrix.add_col()为矩阵添加新行和新列。这些函数在指定的行/列索引处将数组中的值引用插入矩阵。如果矩阵为空(没有行或列),调用中的数组可以是任意大小。如果在指定的索引处存在行/列,矩阵会将现有行/列索引值加1。
下面的脚本声明了一个空的m矩阵,并使用m.add_row()和m.add_col()方法插入行和列。脚本首先在row 0行插入一个包含三个元素的数组,将 m 变为 1x3 矩阵,然后在row 1 行插入另一个数组,将 m 变为 2x3。之后,脚本在row 0行插入另一个数组,将 m 的形状变为 3x3,并移动之前位于索引0及更高位置的所有行的索引。在最后一列索引处插入另一个数组,将 m 的形状改为 3x4。最后,在最后一行索引处添加一个包含四个值的数组。
最后得到的矩阵有四行四列,按升序包含 1-16 个值。每次插入行/列后,脚本都会使用用户定义的 debugLabel() 函数显示 m 的行数,以直观地显示整个过程:

//@version=5
indicator("Rows and columns demo")
//@function 在带注释的标签中显示矩阵的行。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的x参数: `bar_index`.
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue, color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//创建一个空矩阵。
var m = matrix.new<float>()
if bar_index == last_bar_index - 1
debugLabel(m, bar_index - 30, note = "Empty matrix")
// 在第 0 行插入一个数组。`m` 现在有 1 行 3 列.
m.add_row(0, array.from(5, 6, 7))
debugLabel(m, bar_index - 20, note = "New row at\nindex 0")
// 在第 1 行插入一个数组。`m` 现在有 2 行 3 列.
m.add_row(1, array.from(9, 10, 11))
debugLabel(m, bar_index - 10, note = "New row at\nindex 1")
// 在第 0 行插入另一个数组。`m` 现在有 3 行 3 列。
// 原来第0行的值现在将位于第1行,第1行的值将位于第2行
m.add_row(0, array.from(1, 2, 3))
debugLabel(m, bar_index, note = "New row at\nindex 0")
// 在第 3 列插入一个数组。 现在,`m` 将有 3 行 4 列.
m.add_col(3, array.from(4, 8, 12))
debugLabel(m, bar_index + 10, note = "New column at\nindex 3")
// 在第 3 行插入一个数组。`m` 现在将有 4 行 4 列.
m.add_row(3, array.from(13, 14, 15, 16))
debugLabel(m, bar_index + 20, note = "New row at\nindex 3")
正如从 line, linefill, label, box, table, or UDT实例矩阵中获取的行或列数组表现为浅拷贝一样,包含这些类型的矩阵中的元素与插入其中的数组引用相同的对象。在这种情况下,修改任何一个对象中的元素值都会影响另一个对象。
删除
要从矩阵中移除特定行或列,请使用 matrix.remove_row()和matrix.remove_col()。这些函数会移除指定的行/列,并将其后所有行/列的索引值减 1。
在本例中,我们将这两行代码添加到上一节的 "行和列演示 "脚本中:
// 删除示例
// 删除矩阵的第一行和最后一列。 现在 `m` 将有 3 行 3 列。
m.remove_row(0)
m.remove_col(3)
debugLabel(m, bar_index + 30, color.red, note = "Removed row 0\nand column 3")
这段代码使用m.remove_row()和m.remove_col()方法移除 m 矩阵的第一行和最后一列,并在bar_index + 30处的标签中显示这些行。我们可以看到,执行此代码块后,m的形状为3x3,所有现有行的索引值都减少了1:
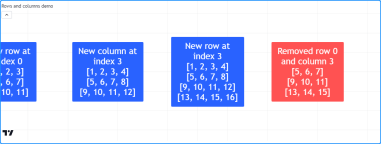
交换
使用matrix.swap_rows()和matrix.swap_columns()可以在不改变矩阵尺寸的情况下交换矩阵的行和列。这些函数交换元素在row1/column1和row2/column2处的位置。
让我们在前面的示例中添加以下几行,交换m的第一行和最后一行,并在bar_index + 40处的标签中显示变化:
// 交换示例
// 交换第一行和最后一行。 m "的尺寸保持不变.
m.swap_rows(0, 2)
debugLabel(m, bar_index + 40, color.purple, note = "Swapped rows 0\nand 2")
在新标签中,我们看到矩阵的行数与之前相同,而第一行和最后一行的位置发生了交换:
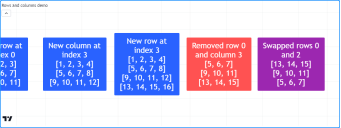
替换
在某些情况下,可能需要完全替换矩阵中的某一行或某一列。为此,需要在所需行/列处插入新数组,并移除该索引处的旧元素。
在下面的代码中,我们定义了一个 replaceRow() 方法,该方法使用 add_row() 方法在row索引处插入新值,并使用 remove_row() 方法移除移动到row + 1 索引处的旧行。此脚本使用 replaceRow() 方法在 3x3 矩阵的行中填入数字 1-9。它使用自定义 debugLabel() 方法在替换行之前和之后在图表上绘制标签:

//@version=5
indicator("Replacing rows demo")
//@function 在带注释的标签中显示矩阵的行。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的x参数`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@function 用新的values数组替换this矩阵的 row数组.
//@param 要替换的行索引。
//@param values 要插入的值数组.
method replaceRow(matrix<float> this, int row, array<float> values) =>
this.add_row(row, values) // 在`row`处插入`values数组的拷贝
this.remove_row(row + 1) // 删除 `row` 中的旧元素。
//@variable A 3x3 matrix.
var matrix<float> m = matrix.new<float>(3, 3, 0.0)
if bar_index == last_bar_index - 1
m.debugLabel(note = "Original")
// 替换 `m` 的每一行.
m.replaceRow(0, array.from(1.0, 2.0, 3.0))
m.replaceRow(1, array.from(4.0, 5.0, 6.0))
m.replaceRow(2, array.from(7.0, 8.0, 9.0))
m.debugLabel(bar_index + 10, note = "Replaced rows")
循环浏览矩阵
for
当脚本只需要遍历矩阵中的行/列索引时,最常用的方法是使用 for 循环。例如,该行创建了一个循环,row值从0开始,逐行递增,直到比 m 矩阵中的行数小1(即最后一行索引)为止:
for row = 0 to m.rows() - 1
要遍历 m 矩阵中的所有索引值,我们可以创建一个嵌套循环,遍历每一行上的每一列索引:
for row = 0 to m.rows() - 1
for column = 0 to m.columns() - 1
让我们使用这种嵌套结构创建一个可视化矩阵元素的方法。在下面的脚本中,我们定义了一个 toTable() 方法,用于显示表格对象中的矩阵元素。它会遍历每一行的每个行索引和每一行的每个列索引。在循环中,它会将每个元素转换为string,并显示在相应的表格单元格中。
在图表第一条K线上,脚本创建了一个空的 m 矩阵,填充了行,并调用 m.toTable() 显示其元素:

//@version=5
indicator("for loop demo", "Matrix to table")
//@function 在表格中显示 `this` 矩阵的元素。
//@param this 要显示的矩阵。
//@param position 表格在图表中的位置。
//@param bgColor 表格的背景颜色。
//@param textColor 每个单元格中文字的颜色。
//@param note 在表格最下面一行显示的注释string。
//@returns 一个新的`table`对象,其单元格与`this`矩阵的每个元素相对应。
method toTable(
matrix<float> this, string position = position.middle_center,
color bgColor = color.blue, color textColor = color.white,
string note = na
) =>
//@variable 此矩阵的行数。
int rows = this.rows()
//@variable 此矩阵的列数。
int columns = this.columns()
//@variable 显示此矩阵元素的表格,带有一个可选的 "note "单元格。
table result = table.new(position, columns, rows + 1, bgColor)
// 遍历`此`矩阵的每个行索引.
for row = 0 to rows - 1
// 遍历`this`矩阵的每列索引上的每`row`.
for col = 0 to columns - 1
//@variable 此矩阵中位于 `row` 和 `col` 索引处的元素。
float element = this.get(row, col)
// 用 `element` 值初始化相应的 `result` 单元格。
result.cell(col, row, str.tostring(element), text_color = textColor, text_size = size.huge)
// 如果提供了 "注释",则在底部一行初始化一个合并单元格。
if not na(note)
result.cell(0, rows, note, text_color = textColor, text_size = size.huge)
result.merge_cells(0, rows, columns - 1, rows)
result // 返回 `result` table.
//@variable A 3x4 matrix of values.
var m = matrix.new<float>()
if bar_index == 0
// Add rows to `m`.
m.add_row(0, array.from(1, 2, 3))
m.add_row(1, array.from(5, 6, 7))
m.add_row(2, array.from(9, 10, 11))
// Add a column to `m`.
m.add_col(3, array.from(4, 8, 12))
// 在表格中显示 `m` 的元素.
m.toTable()
for...in
当脚本需要遍历和检索矩阵的行时,使用 for...in 结构往往比标准 for 循环更受欢迎。这种结构可以直接引用矩阵中的行数组,因此在这种情况下使用更方便。例如,该行创建了一个循环,返回 m 矩阵中每一行的行数组:
for row in m
以下指标计算具有输入长度的 OHLC 数据的移动平均值,并将数值显示在图表上。自定义 rowWiseAvg() 方法使用 for...in 结构循环查看矩阵的各行,生成包含每行 array.avg() 的数组。
在图表第一条K线上,脚本会创建一个新的m矩阵,该矩阵有4行length列,在随后的每个K线上,脚本都会通过m.add_col()和m.remove_col()方法将1列新的OHLC数据以队列方式更新该矩阵。它使用m.rowWiseAvg()计算行平均值数组,然后将元素值绘制在图表上:
//@version=5
indicator("for...in loop demo", "Average OHLC", overlay = true)
//@variable 平均值的项数。.
int length = input.int(20, "Length", minval = 1)
//@function 计算矩阵每一行的平均值.
method rowWiseAvg(matrix<float> this) =>
//@variable 一个数组,存放每行平均值相.
array<float> result = array.new<float>()
// 遍历此矩阵的每一行.
for row in this
// 将每个 "row"的平均值推入数组"result"中.
result.push(row.avg())
result // 返回结果数组.
//@variable 4xlength 的数值矩阵. 默认20列
var matrix<float> m = matrix.new<float>(4, length)
// 在矩阵中添加包含 OHLC 值的新列.
m.add_col(m.columns(), array.from(open, high, low, close))
// 删除第一列.
m.remove_col(0)
//@variable 数组--包含"length "个K线的OHLC的平均值.
array<float> averages = m.rowWiseAvg()
plot(averages.get(0), "Average Open", color.blue, 2)
plot(averages.get(1), "Average High", color.green, 2)
plot(averages.get(2), "Average Low", color.red, 2)
plot(averages.get(3), "Average Close", color.orange, 2)
请注意:
l for...in 循环也可以引用每一行的索引值。例如,m 中的 for [i, row] 在每次循环迭代时都会创建一个元组,其中包含 i 行索引和 m 矩阵中相应的行数组。
复制矩阵
浅层复制
Pine脚本可以通过matrix.copy()复制矩阵。此函数会返回矩阵的浅层拷贝,它不会影响原矩阵的形状或其引用。
例如,这个脚本为myMatrix变量分配了一个新矩阵,并增加了两列。脚本使用myMatrix.copy()方法从myMatrix创建了一个新的myCopy矩阵,然后添加了一行。它通过用户定义的debugLabel()函数在标签中显示两个矩阵的行:

//@version=5
indicator("Shallow copy demo")
//@function 在带注释的标签中显示矩阵的行。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(matrix<float> this, int barIndex = bar_i ndex, color bgColor = color.blue, color textColor = c olor.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 2x2 `float` matrix.
matrix<float> myMatrix = matrix.new<float>()
myMatrix.add_col(0, array.from(1.0, 3.0))
myMatrix.add_col(1, array.from(2.0, 4.0))
//@variable myMatrix "的浅层拷贝.
matrix<float> myCopy = myMatrix.copy()
// 在 `myCopy` 的最后一个索引中添加一行.
myCopy.add_row(myCopy.rows(), array.from(5.0, 6.0))
if bar_index == last_bar_index - 1
// 用不同的标签显示两个矩阵的行数.
myMatrix.debugLabel(note = "Original")
myCopy.debugLabel(bar_index + 10, color.green, note = "Shallow Copy")
值得注意的是,矩阵浅层拷贝中的元素指向与原始矩阵相同的值。当矩阵包含特殊类型(line, linefill, label, box和 table)或用户自定义类型时,浅层拷贝中的元素会引用与原始矩阵相同的对象。
此脚本声明一个以newLabel为初始值的myMatrix变量,通过myMatrix.copy()将myMatrix复制到myCopy变量,并给标签数画线。如下图,图表上只有一个标签,因为myCopy中的元素与myMatrix中的元素引用的是同一个对象。因此,myCopy中元素值的变化会影响两个矩阵中的值:

//@version=5
indicator("Shallow copy demo")
//@variable 原始矩阵元素的初始值.
var label newLabel = label.new(
bar_index, 1, "Original", color = color.blue, textcolor = color.white, size = size.huge
)
//@variable 声明一个 1x1 矩阵,其中包含一个新的 "label "实例.
var matrix<label> myMatrix = matrix.new<label>(1, 1, newLabel)
//@variable 浅层复制矩阵`myMatrix`.
var matrix<label> myCopy = myMatrix.copy()
//@variable 矩阵 `myCopy`中的第一个元素标签,索引0,0
label testLabel = myCopy.get(0, 0)
//更改testLabel中`text`, `style`和`x`的值,同时影响newLabel的值
testLabel.set_text("Copy")
testLabel.set_style(label.style_label_up)
testLabel.set_x(bar_index)
// Plot the total number of labels.
plot(label.all.size(), linewidth = 3)
深层拷贝
通过显式复制矩阵引用的每个对象,可以生成矩阵的深层拷贝(即元素指向原始值副本的矩阵)。
在这里,我们为之前的脚本添加了一个 deepCopy() 用户自定义方法。该方法创建了一个新矩阵,并使用嵌套 for 循环将所有元素赋值给原始值的拷贝。当脚本调用该方法而不是内置的 copy() 方法时,我们会看到图表上现在有两个标签,而且对 myCopy 标签的任何更改都不会影响 myMatrix 的标签:
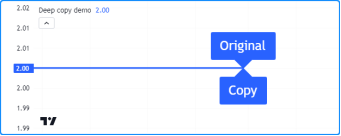
//@version=5
indicator("Deep copy demo")
//@function 返回标签矩阵的深层拷贝.
method deepCopy(matrix<label> this) =>
//@variable A deep copy of `this` matrix.
matrix<label> that = this.copy()
for row = 0 to that.rows() - 1
for column = 0 to that.columns() - 1
// 将that矩阵中每个row和column的元素分配给检索到的标签副本.
that.set(row, column, that.get(row, column).copy())
that
//@variable Initial value of the original matrix.
var label newLabel = label.new(bar_index, 2, "Original",
color = color.blue, textcolor = color.white, size = size.huge
)
//@variable A 1x1矩阵包含一个新的 `label`实例.
var matrix<label> myMatrix = matrix.new<label>(1, 1, newLabel)
//@variable A deep copy of `myMatrix`.
var matrix<label> myCopy = myMatrix.deepCopy()
//@variable `myCopy` 矩阵中的第一个标签.
label testLabel = myCopy.get(0, 0)
// 更改testLabel的`text``style` 和`x`值。不会影响`newLabel`的值
testLabel.set_text("Copy")
testLabel.set_style(label.style_label_up)
testLabel.set_x(bar_index)
// 更改 `newLabel`的`x`值 .
newLabel.set_x(bar_index)
// 绘制标签总数.
plot(label.all.size(), linewidth = 3)
子矩阵
在Pine中,子矩阵是现有矩阵的浅层拷贝,只包括from_row/column和to_row/column参数指定的行和列。本质上,它是矩阵的切片拷贝。
例如,下面的脚本通过 m.submatrix() 方法从 m 矩阵创建了一个 mSub 矩阵,然后调用用户定义的 debugLabel() 函数,以标签形式显示两个矩阵的行:

//@version=5
indicator("Submatrix demo")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 3x3 matrix of values.
var m = matrix.new<float>()
if bar_index == last_bar_index - 1
// Add columns to `m`.
m.add_col(0, array.from(9, 6, 3))
m.add_col(1, array.from(8, 5, 2))
m.add_col(2, array.from(7, 4, 1))
// Display the rows of `m`.
m.debugLabel(note = "Original Matrix")
//@variable A 2x2 的子矩阵,包含前两行和前两列.
matrix<float> mSub = m.submatrix(from_row = 0, to_row = 2, from_column = 0, to_column = 2)
// 显示 "mSub "的行数`
debugLabel(mSub, bar_index + 10, bgColor = color.green, note = "Submatrix")
范围和历史
矩阵变量会在每条K线上留下历史轨迹,允许脚本使用历史引用操作符 [] 与之前分配给变量的矩阵实例进行交互。此外,脚本还可以在函数、方法和条件结构的作用域内修改分配给全局变量的矩阵。
该脚本计算length条K线范围,K线主体和灯芯距离的比值的平均值,并将当前数据与length条K线之前的数值一起显示在表格中。用户定义addData()函数将当前和历史比值列添加到globalMatrix中,calcAvg()函数使用[]运算符引用 previous矩阵分配给 globalMatrix,以计算平均值矩阵: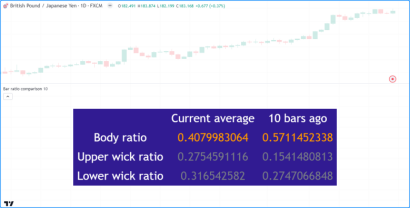
//@version=5
indicator("Scope and history demo", "Bar ratio comparison")
int length = input.int(10, "Length", 1)
//@variable A global matrix.
matrix<float> globalMatrix = matrix.new<float>()
//@function 计算烛体范围与蜡烛范围的比率.
bodyRatio() =>
math.abs(close - open) / (high - low)
//@function 计算灯芯上部范围与蜡烛范围的比率.
upperWickRatio() =>
(high - math.max(open, close)) / (high - low)
//@function 计算灯芯下部范围与蜡烛范围的比率.
lowerWickRatio() =>
(math.min(open, close) - low) / (high - low)
//@function 将数据添加到 `globalMatrix`.
addData() =>
// 在 `column` 0 位置添加一列新数据
globalMatrix.add_col(0, array.from(bodyRatio(), upperWickRatio(), lowerWickRatio()))
//@variable 存入`length`条K线前的`globalMatrix`的第1列
array<float> pastValues = globalMatrix.col(0)[length]
// 添加pastValues`到`globalMatrix`第2列,
if na(pastValues)
globalMatrix.add_col(1, array.new<float>(3))
else //如果pastValues为na`,添加`na`数组到第2列
globalMatrix.add_col(1, pastValues)
//@function 返回历史K线上分配给globalMatrix的length个值的平均值
calcAvg() =>
//@variable `globalMatrix`矩阵历史值求和.
matrix<float> sums = matrix.new<float>(globalMatrix.rows(), globalMatrix.columns(), 0.0)
for i = 0 to length - 1
//@variable 当前K线之前的`globalMatrix`矩阵第`i`条.
matrix<float> previous = globalMatrix[i]
// if `previous` is `na`.跳出循环
if na(previous)
sums.fill(na)
break
// 将 `sums` 和 `previous` 的和赋值给 `sums`..
sums := matrix.sum(sums, previous)
// 将 "sums"矩阵除以 "length"。.
result = sums.mult(1.0 / length)
// Add data to the `globalMatrix`.
addData()
//@variable globalMatrix "矩阵的历史平均值.
globalAvg = calcAvg()
//@variable A `table`显示`globalMatrix`信息
var table infoTable = table.new(
position.middle_center, globalMatrix.columns() + 1, globalMatrix.rows() + 1, bgcolor = color.navy
)
// 定义数值单元.
for [i, row] in globalAvg
for [j, value] in row
color textColor = value > 0.333 ? color.orange : color.gray
infoTable.cell(j + 1, i + 1, str.tostring(value), text_color = textColor, text_size = size.huge)
// 定义标题单元格.
infoTable.cell(0, 1, "Body ratio", text_color = color.white, text_size = size.huge)
infoTable.cell(0, 2, "Upper wick ratio", text_color = color.white, text_size = size.huge)
infoTable.cell(0, 3, "Lower wick ratio", text_color = color.white, text_size = size.huge)
infoTable.cell(1, 0, "Current average", text_color = color.white, text_size = size.huge)
infoTable.cell(2, 0, str.format("{0} bars ago", length), text_color = color.white, text_size = size.huge)
请注意
l addData() 和 calcAvg() 函数没有参数,因为它们直接与外层作用域中声明的 globalMatrix 和 length 变量交互。
l calcAvg() 使用 matrix.sum() 将前面的矩阵相加,并使用 matrix.mult() 将所有元素乘以 1 / length,从而计算出平均值。我们将在下文的矩阵计算部分讨论这些函数和其他专门函数。
检查矩阵
检查矩阵的形状和元素模式至关重要,有助于展示矩阵的重要信息及其与各种计算和变换的兼容性。Pine Script®包含几个用于矩阵检查的内置功能: matrix.is_square()、matrix.is_identity()、 matrix.is_diagonal()、 matrix.is_antidiagonal()、 matrix.is_symmetric()、matrix.is_antisymmetric()、matrix.is_triangular()、matrix.is_stochastic()、matrix.is_binary()和matrix.is_zero()。
为了演示这些功能,本示例包含一个自定义的 inspect() 方法,该方法使用条件块和 matrix.is_*() 函数来返回矩阵的相关信息。它将 m 矩阵的string表示和 m.inspect() 返回的描述以标签形式显示在图表上:

//@version=5
indicator("Matrix inspection demo")
//@function 使用`matrix.is_*()`函数检查矩阵,返回描述其部分特征的`string`.
method inspect(matrix<int> this)=>
//@variable A string describing `this` matrix.
string result = "This matrix:\n"
if this.is_square()
result += "- Has an equal number of rows and columns.\n"
if this.is_binary()
result += "- Contains only 1s and 0s.\n"
if this.is_zero()
result += "- Is filled with 0s.\n"
if this.is_triangular()
result += "- Contains only 0s above and/or below its main diagonal.\n"
if this.is_diagonal()
result += "- Only has nonzero values in its main diagonal.\n"
if this.is_antidiagonal()
result += "- Only has nonzero values in its main antidiagonal.\n"
if this.is_symmetric()
result += "- Equals its transpose.\n"
if this.is_antisymmetric()
result += "- Equals the negative of its transpose.\n"
if this.is_identity()
result += "- Is the identity matrix.\n"
result
//@variable A 4x4 identity matrix.
matrix<int> m = matrix.new<int>()
// Add rows to the matrix.
m.add_row(0, array.from(1, 0, 0, 0))
m.add_row(1, array.from(0, 1, 0, 0))
m.add_row(2, array.from(0, 0, 1, 0))
m.add_row(3, array.from(0, 0, 0, 1))
if bar_index == last_bar_index - 1
// 用蓝色标签显示 `m` 矩阵.
label.new(
bar_index, 0, str.tostring(m), color = color.blue, style = label.style_label_right,
textcolor = color.white, size = size.huge
)
// 用紫色标签显示 `m.inspect()` 的结果。
label.new(
bar_index, 0, m.inspect(), color = color.purple, style = label.style_label_left,
textcolor = color.white, size = size.huge
)
操纵矩阵
重塑
矩阵的形状决定了它与各种矩阵运算的兼容性。在某些情况下,有必要在不影响元素数量或元素引用值的情况下改变矩阵的维数,也就是所谓的重塑。要在 Pine 中重塑矩阵,请使用 matrix.reshape() 函数。
本例演示了对矩阵进行多次重塑操作的结果。初始 m 矩阵的形状为 1x8(一行八列)。通过连续调用 m.reshape() 方法,脚本将 m 的形状分别改为 2x4、4x2 和 8x1,并使用自定义 debugLabel() 方法在图表的标签中显示每个重塑的矩阵:
//@version=5
indicator("Reshaping example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable 包含数值 1-8 的矩阵.
matrix<int> m = matrix.new<int>()
if bar_index == last_bar_index - 1
// 添加初始值向量.
m.add_row(0, array.from(1, 2, 3, 4, 5, 6, 7, 8))
m.debugLabel(note = "Initial 1x8 matrix")
// 重塑。 `m` 现在有 2 行 4 列.
m.reshape(2, 4)
m.debugLabel(bar_index + 10, note = "Reshaped to 2x4")
// 重塑。 `m` 现在有 4 行 2 列.
m.reshape(4, 2)
m.debugLabel(bar_index + 20, note = "Reshaped to 4x2")
// 重塑。 m` 现在有 8 行 1 列.
m.reshape(8, 1)
m.debugLabel(bar_index + 30, note = "Reshaped to 8x1")
l 每次调用 m.reshape() 时,m 中元素的顺序不会改变。
l 重塑矩阵时,行和列参数的乘积必须等于 matrix.elements_count()值,因为 matrix.reshape() 不能改变矩阵中的元素个数。
反转
使用 matrix.reverse(),可以颠倒矩阵中所有元素的顺序。此函数将 m-by-n 矩阵 id 第 i 行和第 j 列的引用移至 m-1-i 行和 n-1-j 列。
例如,该脚本创建了一个3x3矩阵,其中按升序包含1-9 的值,然后用reverse()方法反转矩阵的内容。通过m.debugLabel()在图表的标签中显示矩阵的原始版本和修改版本:

//@version=5
indicator("Reversing demo")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 3x3 matrix.
matrix<float> m = matrix.new<float>()
// Add rows to `m`.
m.add_row(0, array.from(1, 2, 3))
m.add_row(1, array.from(4, 5, 6))
m.add_row(2, array.from(7, 8, 9))
if bar_index == last_bar_index - 1
// 显示 `m`的内容.
m.debugLabel(note = "Original")
// 反转 `m`, 然后显示其内容.
m.reverse()
m.debugLabel(bar_index + 10, color.red, note = "Reversed")
转置
矩阵转置是一种基本操作,它将矩阵中的所有行和列围绕其主对角线(行索引等于列索引的所有值的对角线向量)翻转。这一过程会产生一个行列尺寸相反的新矩阵,即转置矩阵。脚本可以使用 matrix.transpose() 计算矩阵的转置。
对于任何 m 行 n 列的矩阵,matrix.transpose() 返回的矩阵将有 n 行和 m 列。矩阵中第 i 行和第 j 列的所有元素都对应于其转置矩阵中第 j 行和第 i 列的元素。
本示例声明了一个 2x4 m 矩阵,使用 m.transpose() 方法计算了它的转置,并使用我们自定义的 debugLabel() 方法在图表上显示了这两个矩阵。如下所示,转置矩阵的形状为 4x2,转置矩阵的行与原始矩阵的列相匹配:
//@version=5
indicator("Transpose example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 2x4 matrix.
matrix<int> m = matrix.new<int>()
// 添加列至 `m`.
m.add_col(0, array.from(1, 5))
m.add_col(1, array.from(2, 6))
m.add_col(2, array.from(3, 7))
m.add_col(3, array.from(4, 8))
//@variable m` 的转置。 形状为 4x2.
matrix<int> mt = m.transpose()
if bar_index == last_bar_index - 1
m.debugLabel(note = "Original")
mt.debugLabel(bar_index + 10, note = "Transpose")
排序
脚本可以通过matrix.sort()对矩阵内容进行排序。与数组对元素排序的array.sort()不同,该函数根据某指定列的值对矩阵中的所有行进行排序(默认为order.ascending)。
此脚声明了一个3x3的矩阵m,根据第1列按升序对m1拷贝的行排序,再根据第2列按降序对m2拷贝的行排序。使用debugLabel()在标签中显示原始矩阵和排序拷贝:

//@version=5
indicator("Sorting rows example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本。
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 3x3 matrix.
matrix<int> m = matrix.new<int>()
if bar_index == last_bar_index - 1
// Add rows to `m`.
m.add_row(0, array.from(3, 2, 4))
m.add_row(1, array.from(1, 9, 6))
m.add_row(2, array.from(7, 8, 9))
m.debugLabel(note = "Original")
// 复制 `m` 并根据第一列按升序对行排序(默认值).
matrix<int> m1 = m.copy()
m1.sort()
m1.debugLabel(bar_index + 10, color.green, note = "Sorted using col 0\n(Ascending)")
// 复制 `m` 并根据第二列按降序对行排序.
matrix<int> m2 = m.copy()
m2.sort(1, order.descending)
m2.debugLabel(bar_index + 20, color.red, note = "Sorted using col 1\n(Descending)")
matrix.sort()并不能对矩阵的列进行排序。不过,我们可以用matrix.transpose()对矩阵列进行排序。
本脚本包含一个sortColumns()方法,它使用sort() 方法,使用与原始矩阵行对应的列对矩阵的转置进行排序。脚本使用此方法根据m矩阵第1行的内容对其进行排序: 
//@version=5
indicator("Sorting columns example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color =bgColor, style=label.style_label_center,
textcolor = textColor, size = size.huge
)
//@function Sorts 根据指定的 "行 "中的值计算 "此 "矩阵的列。
method sortColumns(matrix<int> this, int row = 0, bool ascending = true) =>
//@variable 转置 `this` matrix.
matrix<int> thisT = this.transpose()
//@variable 当 `ascending` 为 `true` 时, `order.ascending`,否则 `order.descending`
order = ascending ? order.ascending : order.descending
// 使用 `row` 列对 `thisT` 的行排序。
thisT.sort(row, order)
//@variable 此矩阵的拷贝,列已排序.
result = thisT.transpose()
//@variable A 3x3 matrix.
matrix<int> m = matrix.new<int>()
if bar_index == last_bar_index - 1
// Add rows to `m`.
m.add_row(0, array.from(3, 2, 4))
m.add_row(1, array.from(1, 9, 6))
m.add_row(2, array.from(7, 8, 9))
m.debugLabel(note = "Original")
// 根据第一行对 `m` 列排序并显示结果.
m.sortColumns(0).debugLabel(bar_index + 10, note = "Sorted using row 0\n(Ascending)")
连接
脚本可以使用 matrix.concat() 将两个矩阵连接起来。该函数将 id2 矩阵的行添加到具有相同列数的 id1 矩阵的末尾。
若要创建一个矩阵,其中的元素以列的形式在末尾添加另一个矩阵,请将两个矩阵进行转置,在转置后的矩阵上使用 matrix.concat(),然后将结果再进行转置。
例如,该脚本将 m2 矩阵的行追加到 m1 矩阵,并使用矩阵的转置拷贝追加它们的列。脚本使用自定义 debugLabel() 方法在标签中显示 m1 和 m2 矩阵以及行列连接后的结果:
//@version=5
indicator("Concatenation demo")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color =bgColor, style=label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable 充满 1 的 2x3 矩阵.
matrix<int> m1 = matrix.new<int>(2, 3, 1)
//@variable 充满 2 的 2x3 矩阵.
matrix<int> m2 = matrix.new<int>(2, 3, 2)
//@variable 转置`m1`.
t1 = m1.transpose()
//@variable 转置 `m2`.
t2 = m2.transpose()
if bar_index == last_bar_index - 1
// Display the original matrices.
m1.debugLabel(note = "Matrix 1")
m2.debugLabel(bar_index + 10, note = "Matrix 2")
// 将 `m2` 的行添加到 `m1` 的末尾,并显示 `m1`.
m1.concat(m2)
m1.debugLabel(bar_index + 20, color.blue, note = "Appended rows")
// 将 `t2` 的行添加到 `t1` 的末尾,然后显示`t1`的转置结果.
t1.concat(t2)
t1.transpose().debugLabel(bar_index + 30, color.purple, note="Appended columns")
矩阵计算
元素计算
Pine 脚本可以通过 matrix.avg()、matrix.min()、matrix.max() 和 matrix.mode() 计算矩阵中所有元素的平均值、最小值、最大值和众数。这些函数的操作与array.*的操作相同,允许用户使用相同的语法对矩阵、矩阵的子矩阵、矩阵的行和列进行元素计算。例如,在值为 1-9 的 3x3 矩阵和具有相同 9 个元素的数组上调用内置 *.avg() 函数,都会返回 5 的值。
下面的脚本使用 *.avg()、*.max() 和 *.min() 方法计算一个时间段内 OHLC 数据的发展中平均值和极值。只要 queueColumn 为 true,脚本就会在 ohlcData 矩阵的末尾添加一列新的开盘、最高、最低和收盘值。如果为假,脚本会使用 get() 和 set() 矩阵方法调整最后一列中的元素,以显示当前时段的 HLC 值。脚本使用ohlcData操作矩阵、submatrix()、row()和col()操作数组来计算length范围内的发展中 OHLC4 和 HL2 平均值、最高值和最低值,以及当前周期的发展中的 OHLC4 价格:
//@version=5
indicator("Element-wise calculations example", "Developing values", overlay = true)
//@variable 平均数中的数据点数量.
int length = input.int(3, "Length", 1)
//@variable 每个重置阶段的时间框架.
string timeframe = input.timeframe("D", "Reset Timeframe")
//@variable 一个 4xlength的 OHLC 值矩阵.
var matrix<float> ohlcData = matrix.new<float>(4, length)
//@variable 在 `timeframe` 的新K线开始时为 `true.
bool queueColumn = timeframe.change(timeframe)
if queueColumn
// `ohlcData`的末列添加新值.
ohlcData.add_col(length, array.from(open,high,low, close))
// 从 `ohlcData` 中删除最旧的列.
ohlcData.remove_col(0)
else
// 调整第2行(row 1)的最后一个元素(column)为新的最高价.
if high > ohlcData.get(1, length - 1)
ohlcData.set(1, length - 1, high)
// 根据新的最低价调整第3行(row 2)的最后一个元素.
if low < ohlcData.get(2, length - 1)
ohlcData.set(2, length - 1, low)
// 根据新的收盘价调整第4行的最后一个元素.
ohlcData.set(3, length - 1, close)
//@variable ohlcData "中所有元素的 "matrix.avg() "值.即OHLC4
avgOHLC4 = ohlcData.avg()
//@variable 第2行(row 1)和第3行所有"high"值和"low"的平均值
avgHL2 = ohlcData.submatrix(from_row = 1, to_row = 3).avg()
//@variable ohlcData所有值matrix.max()。等价于ohlcData.row(1).max()
maxHigh = ohlcData.max()
//@variable 所有`ohlcData`中的`low`作array.min()。等价于`ohlcData.min()
minLow = ohlcData.row(2).min()
//@variable ohlcData "中最后一列作 "array.avg()",即当前的 OHLC4。
ohlc4Value = ohlcData.col(length - 1).avg()
plot(avgOHLC4, "Average OHLC4", color.purple, 2)
plot(avgHL2, "Average HL2", color.navy, 2)
plot(maxHigh, "Max High", color.green)
plot(minLow, "Min Low", color.red)
plot(ohlc4Value, "Current OHLC4", color.blue)
请注意:
· 在本例中,我们交替使用了 array.*() 和 matrix.*()方法,以展示它们在语法和行为上的相似性。
· 可以用matrix.avg()乘以matrix.elements_count()来计算相当于 array.sum() 的矩阵。
特殊计算
Pine Script® 具有多个内置函数,用于执行基本的矩阵运算和线性代数运算,包括matrix.sum(), matrix.diff(), matrix.mult(), matrix.pow(), matrix.det(), matrix.inv(), matrix.pinv(), matrix.rank(), matrix.trace(), matrix.eigenvalues(), matrix.eigenvectors()和 matrix.kron()。这些函数都是高级功能,有助于进行各种矩阵计算和变换。
下面,通过一些基本示例来解释几个基本函数。
matrix.sum()和matrix.diff()
使用 matrix.sum() 和 matrix.diff()函数,脚本可以对两个形状相同的矩阵或一个矩阵和一个标量值进行加减运算。这些函数使用 id2 矩阵或标量的值与 id1 中的元素相加或相减。
本脚本演示了 Pine 中矩阵加减法的一个简单示例。它创建一个 3x3 矩阵,计算其转置,然后计算两个矩阵的 matrix.sum() 和 matrix.diff()。该示例会在图表上以标签形式显示原始矩阵、矩阵的转置以及计算结果的和与差矩阵:

//@version=5
indicator("Matrix sum and diff example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 3x3 matrix.
m = matrix.new<float>()
// Add rows to `m`.
m.add_row(0, array.from(0.5, 1.0, 1.5))
m.add_row(1, array.from(2.0, 2.5, 3.0))
m.add_row(2, array.from(3.5, 4.0, 4.5))
if bar_index == last_bar_index - 1
// Display `m`.
m.debugLabel(note = "A")
// 获取并显示 `m` 的转置.
matrix<float> t = m.transpose()
t.debugLabel(bar_index + 10, note = "Aᵀ")
// 计算两个矩阵之和。 得出的矩阵是对称的.
matrix.sum(m, t).debugLabel(bar_index + 20, color.green, note = "A + Aᵀ")
// 计算两个矩阵的差值。 所得矩阵为非对称矩阵。
matrix.diff(m, t).debugLabel(bar_index + 30, color.red, note = "A - Aᵀ")
请注意:
l 在本例中,我们将原始矩阵标为 "A",将转置矩阵标为 "AT"。
l 将 "A "和 "AT "相加产生一个对称矩阵,相减产生一个非对称矩阵。
matrix.mult()
脚本可以通过 matrix.mult() 函数实现两个矩阵的乘法运算。该函数还可用于矩阵与数组或标量值的乘法运算。
在两个矩阵相乘的情况下,与加法和减法不同,矩阵乘法不要求两个矩阵具有相同的形状。但是,第一个矩阵的列数必须等于第二个矩阵的行数。matrix.mult() 返回的矩阵将包含与 id1 相同的行数和 id2 相同的列数。例如,一个 2x3 矩阵乘以一个 3x4 矩阵,将产生一个两行四列的矩阵,如下图所示。结果矩阵中的每个值都是 id1 中相应行和 id2 中相应列的点积:
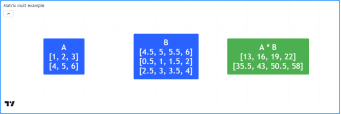
//@version=5
indicator("Matrix mult example")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index,
color bgColor =color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText, color = bgColor,
style = label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable A 2x3 matrix.
a = matrix.new<float>()
//@variable A 3x4 matrix.
b = matrix.new<float>()
// Add rows to `a`.
a.add_row(0, array.from(1, 2, 3))
a.add_row(1, array.from(4, 5, 6))
// 添加行到 `b`.
b.add_row(0, array.from(0.5, 1.0, 1.5, 2.0))
b.add_row(1, array.from(2.5, 3.0, 3.5, 4.0))
b.add_row(0, array.from(4.5, 5.0, 5.5, 6.0))
if bar_index == last_bar_index - 1
//@variable 返回 `a` * `b`的结果.
matrix<float> ab = a.mult(b)
// 显示 `a`, `b`, and `ab`矩阵.
debugLabel(a, note = "A")
debugLabel(b, bar_index + 10, note = "B")
debugLabel(ab, bar_index + 20, color.green, note="A * B")
请注意:
l 与标量乘法不同,矩阵乘法是非交换式的,也就是说,matrix.mult(a, b) 与 matrix.mult(b, a) 的结果不一定相同。在我们的示例中,后者会引发运行时错误,因为 b 的列数不等于 a 的行数。
当矩阵与数组相乘时,此函数的处理方式与id1乘以单列矩阵相同,但会返回一个元素数与id1行数相同的数组。当matrix.mult()传递一个标量作为id2值时,函数会返回一个新矩阵,其元素是id1中的元素乘以id2值。
`matrix.det()`
行列式是一个与正方形矩阵相关的标量值,它描述了矩阵的一些特征,即矩阵的可逆性。如果矩阵有逆,其行列式就非零。否则,矩阵就是奇异的(不可反转的)。脚本可以通过matrix.det()计算矩阵的行列式。
程序员可以利用行列式检测矩阵之间的相似性,识别全秩矩阵和秩缺陷矩阵,以及求解线性方程组,等等。
例如,该脚本利用行列式,使用克拉默法则求解了一个未知数相匹配的线性方程组。用户定义的 solve() 函数返回一个数组,其中包含系统中每个未知值的解,数组的第 n 个元素是系数矩阵的行列式,第 n 列由常数列除以原始系数的行列式代替。
在本脚本中,我们定义了包含这三个方程的系数和常量的矩阵 m:
3 * x0 + 4 * x1 - 1 * x2 = 8
5 * x0 - 2 * x1 + 1 * x2 = 4
2 * x0 - 2 * x1 + 1 * x2 = 1
这个系统的解是 (x0 = 1, x1 = 2, x2 = 3)。通过m.solve()从m中计算出这些值,将它们绘制在图表上:

//@version=5
indicator("Determinants example", "Cramer's Rule")
//@function 使用克拉默法则求解未知数个数相匹配的线性方程组。
//@param this 一个增强矩阵,包含每个未知数的系数和方程的结果。
// 的结果。 例如,包含 2、-1 和 3 的一行表示方程
// `2 * x0 + (-1) * x1 = 3`,其中 `x0`和 `x1`是系统中的未知值。
//@returns 一个数组,包含系统中每个变量的解。
solve(matrix<float> this) =>
//@variable 方程组的系数矩阵.
matrix<float> coefficients = this.submatrix(from_column = 0, to_column = this.columns() - 1)
//@variable 每个等式的结果常数数组n.
array<float> constants = this.col(this.columns() - 1)
//@variable 包含系统中每个未知数解的数组.
array<float> result = array.new<float>()
//@variable 系数矩阵的行列式值。
float baseDet = coefficients.det()
matrix<float> modified = na
for col = 0 to coefficients.columns() - 1
modified := coefficients.copy()
modified.add_col(col, constants)
modified.remove_col(col + 1)
// 将modified的行列式除以baseDet,计算该列未知数的解.
result.push(modified.det() / baseDet)
result
//@variable 一个 3x4 矩阵,包含三方程组的系数和结果.
m = matrix.new<float>()
// 为下列方程添加行:
// 等式 1: 3 * x0 + 4 * x1 - 1 * x2 = 8
// 等式 2: 5 * x0 - 2 * x1 + 1 * x2 = 4
// 等式 3: 2 * x0 - 2 * x1 + 1 * x2 = 1
m.add_row(0, array.from(3.0, 4.0, -1.0, 8.0))
m.add_row(1, array.from(5.0, -2.0, 1.0, 4.0))
m.add_row(2, array.from(2.0, -2.0, 1.0, 1.0))
//@variable m` 所代表方程组中未知数的解数组.
solutions = solve(m)
plot(solutions.get(0), "x0", color.red, 3) // Plots 1.
plot(solutions.get(1), "x1", color.green, 3) // Plots 2.
plot(solutions.get(2), "x2", color.blue, 3) // Plots 3.
请注意:
· 解方程组特别适用于回归分析,如线性回归和多项式回归。
· 克拉默法则对小的方程组很有效。然而,对于较大的方程组,它的计算效率很低。在这种情况下,其他方法(如高斯消元法)通常是首选。
matrix.inv() 和 matrix.pinv()
对于任何非奇异方矩阵,都有一个逆矩阵,与原矩阵相乘后会得到同一矩阵。逆矩阵在各种矩阵变换和方程组求解中都很有用。脚本可以通过 matrix.inv() 函数计算矩阵的逆矩阵。
对于奇异(不可逆转)矩阵,无论矩阵是否为正方形或行列式是否为零,都可以通过 matrix.pinv() 函数计算广义逆(伪逆)。请记住,与真正的逆不同,除非原矩阵是可逆的,否则伪逆与原矩阵的乘积并不一定等于同一矩阵。
下面的示例根据用户输入形成一个 2x2 m 矩阵,然后使用 m.inv() 和 m.pinv() 方法计算 m 的逆或伪逆:
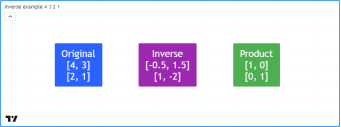
//@version=5
indicator("Inverse example")
// 2x2 矩阵的元素输入.
float r0c0 = input.float(4.0, "Row 0, Col 0")
float r0c1 = input.float(3.0, "Row 0, Col 1")
float r1c0 = input.float(2.0, "Row 1, Col 0")
float r1c1 = input.float(1.0, "Row 1, Col 1")
//@function 在带注释的标签中显示矩阵的行数。
//@param this 要显示的矩阵。
//@param barIndex 要显示标签的`bar_index`。
//@param bgColor 标签的背景颜色。
//@param textColor 标签文字的颜色。
//@param note 在行上方显示的文本.
method debugLabel(
matrix<float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
labelText = note + "\n" + str.tostring(this)
if barstate.ishistory
label.new(
barIndex, 0, labelText,color=bgColor,style=label.style_label_center,
textcolor = textColor, size = size.huge
)
//@variable 一个 2x2 输入值矩阵.
m = matrix.new<float>()
// 为 `m` 添加输入值.
m.add_row(0, array.from(r0c0, r0c1))
m.add_row(1, array.from(r1c0, r1c1))
//@variable m是正方形且行列式不为零,则为true,表示可逆性.
bool isInvertible = m.is_square() and m.det()
//@variable m` 的倒数或假倒数.
mInverse = isInvertible ? m.inv() : m.pinv()
//@variable m与mInverse"的乘积。isInvertible为true时,返回同一矩阵.
matrix<float> product = m.mult(mInverse)
if bar_index == last_bar_index - 1
// 显示 `m`、`mInverse` 及其 `product.
m.debugLabel(note = "Original")
mInverse.debugLabel(bar_index + 10, color.purple, note = isInvertible ? "Inverse" : "Pseudoinverse")
product.debugLabel(bar_index + 20, color.green, note = "Product")
请注意:
· This 脚本只会在 isInvertible 为真时调用 m.inv(),即 m 是平方且行列式不为零时。否则,它会使用 m.pinv() 计算广义逆。
matrix.rank()
矩阵的秩表示它所包含的线性独立向量(行或列)的数量。从本质上讲,矩阵秩衡量的是无法用其他向量的线性组合来表示的向量数量,换句话说,是包含唯一信息的向量数量。脚本可以通过 matrix.rank() 计算矩阵的秩。
本脚本确定两个3x3矩阵(m1和m2)中线性独立向量的数量,并在单独的窗格中绘制这些值。如我们在图表中看到的,m1.rank()值为3,因为每个向量都是唯一的。而m2.rank()值为1,因为它只有一个唯一的向量:
//@version=5
indicator("Matrix rank example")
//@variable 3x3 全秩矩阵.
m1 = matrix.new<float>()
//@variable 一个 3x3 缺秩矩阵.
m2 = matrix.new<float>()
// 将线性独立向量添加到 `m1`.
m1.add_row(0, array.from(3, 2, 3))
m1.add_row(1, array.from(4, 6, 6))
m1.add_row(2, array.from(7, 4, 9))
// 将线性相关向量添加到 `m2`.
m2.add_row(0, array.from(1, 2, 3))
m2.add_row(1, array.from(2, 4, 6))
m2.add_row(2, array.from(3, 6, 9))
// 绘制`matrix.rank()` 的值
plot(m1.rank(), color = color.green, linewidth = 3)
plot(m2.rank(), color = color.red, linewidth = 3)
请注意:
· 一个矩阵的最高秩值是它的行数和列数的最小值。具有最大可能秩的矩阵称为全秩矩阵,任何没有全秩的矩阵称为秩不足矩阵。
· 全秩正方形矩阵的行列式为非零,且此类矩阵具有反演。相反,秩不足矩阵的行列式总是 0。
· 对于每个元素都只包含相同值的矩阵(例如,一个填满 0 的矩阵),秩总是 0,因为没有一个向量包含唯一的信息。对于任何其他具有独特值的矩阵,最小秩可能是 1。
错误处理
除了在脚本编译过程中因语法不当而出现的常见编译器错误外,使用矩阵的脚本还可能在执行过程中出现特定的运行时错误。当脚本出现运行时错误时,会在脚本标题旁边显示一个红色感叹号。用户可以点击该图标查看错误信息。
本节将讨论中使用矩阵时可能遇到的运行时错误。
行/列索引 (xx) 越界,行/列大小为 (yy)
当尝试使用包括matrix.get()、matrix.set()、matrix.fill()和matrix.submatrix()在内的函数以及与矩阵行和列相关的某些函数访问矩阵维数以外的索引时,会出现运行时错误。
例如,这段代码中有两行会产生运行时错误。m.set()方法引用了一个不存在的行索引(2)。m.submatrix()方法引用了直到to_column - 1的所有列索引。to_column 值为 4 会导致运行时错误,因为最后引用的列索引 (3) 不存在于 m 中:
//@version=5
indicator("Out of bounds demo")
//@variable 最大行索引为 1,最大列索引为 2 的 2x3 矩阵.
matrix<float> m = matrix.new<float>(2, 3, 0.0)
// 此行中的 `row` 索引超出范围。 最大值为 1. row 1
m.set(row = 2, column = 0, value = 1.0)
// 此行中的 `to_column`索引无效。最大值为 2 column 2
m.submatrix(from_column = 1, to_column = 4)
if bar_index == last_bar_index - 1
label.new(bar_index, 0, str.tostring(m), color = color.navy, textcolor = color.white, size = size.huge)
用户可以通过确保函数调用不引用大于或等于行/列数的索引,避免在脚本中出现此错误。
数组大小与矩阵的行/列数不匹配。
使用 matrix.add_row() 和 matrix.add_col() 函数向非空矩阵中插入行和列时,插入数组的大小必须与矩阵尺寸一致。插入行的大小必须与列的数量一致,插入列的大小必须与行的数量一致。否则,脚本将引发运行时错误。例如:
//@version=5
indicator("Invalid array size demo")
// 声明空矩阵.
m = matrix.new<float>()
m.add_col(0, array.from(1, 2)) //添加一列将`m`的形状改为2x1
m.add_col(1, array.from(1, 2, 3))//运行时错误,m是2行不是3行
plot(m.col(0).get(1))
请注意:
· 当m为空时,可以插入任意大小的行或列数组,如第一个m.add_col()行所示。
当矩阵 ID 为 "na "时,无法调用矩阵方法
当一个矩阵变量被赋值为 na 时,意味着该变量没有引用一个现有对象。因此,不能使用内置的 matrix.*() 函数和方法。例如:
//@version=5
indicator("na matrix methods demo")
//@variable 分配给`na`的`矩阵`变量.
matrix<float> m = na
mCopy = m.copy() // 会引发运行时错误。 不能复制不存在的矩阵。
if bar_index == last_bar_index - 1
label.new(bar_index, 0, str.tostring(mCopy), color = color.navy, textcolor = color.white, size = size.huge)
要解决此错误,请在使用 matrix.*() 函数前将 m 赋值给一个有效的矩阵实例。
矩阵太大。矩阵的最大大小为 100,000 个元素。
矩阵中元素的总数matrix.elements_count()不能超过100,000个,无论其形状如何。例如,这个脚本会引发错误,因为它在m矩阵中插入了1000行101个元素:
//@version=5
indicator("Matrix too large demo")
var matrix<float> m = matrix.new<float>()
if bar_index == 0
for i = 1 to 1000
// 由于脚本每次迭代都会添加 101 个元素,因此会引发错误。
//1000行*每行101个元素=101000个总元素。这个数字太大。
m.add_row(m.rows(), array.new<float>(101, i))
plot(m.get(0, 0))
行/列索引必须为 0 <= from_row/column < to_row/column。
在使用带有 from_row/column 和 to_row/column 索引的 matrix.*() 函数时,from_* 值必须小于相应的 to_*,最小值可能为 0。否则,脚本将引发运行时错误。
例如,此脚本显示了从 4x4 m 矩阵中声明子矩阵的尝试,其from_row值为2,to_row值为2,这将导致错误:
//@version=5
indicator("Invalid from_row, to_row demo")
//@variable 一个填入随机值的 4x4 矩阵。
matrix<float> m = matrix.new<float>(4, 4, math.random())
matrix<float> mSub = m.submatrix(from_row = 2, to_row = 2)
// 引发错误。 from_row` 不等于 `to_row`.
plot(mSub.get(0, 0))
矩阵id1和id2的行数和列数必须相等才能相加
使用 matrix.sum() 和 matrix.diff() 函数时,id1 和 id2 矩阵的行数和列数必须相同。如下面的代码所示,如果试图对两个尺寸不匹配的矩阵进行加减运算,则会出错:
//@version=5
indicator("Invalid sum dimensions demo")
//@variable A 2x3 matrix.
matrix<float> m1 = matrix.new<float>(2, 3, 1)
//@variable A 3x4 matrix.
matrix<float> m2 = matrix.new<float>(3, 4, 2)
mSum = matrix.sum(m1, m2) // 引发错误。`m1` 和 `m2` 的尺寸不匹配。
plot(mSum.get(0, 0))
id1 "矩阵的列数必须等于 "id2 "矩阵的行数(或数组的元素数)。
使用matrix.mult()将id1矩阵与id2矩阵或数组相乘时,id2的matrix.rows()或array.size()必须等于 id1的matrix.columns()。若两者不一致,将引发此错误。
例如,此脚本试图将两个 2x3 矩阵相乘。虽然这些矩阵的相加是可能的,但相乘是不可能的:
indicator("Invalid mult dimensions demo")
//@variable A 2x3 matrix.
matrix<float> m1 = matrix.new<float>(2, 3, 1)
//@variable A 2x3 matrix.
matrix<float> m2 = matrix.new<float>(2, 3, 2)
mSum = matrix.mult(m1, m2) //引发错误。m1的列数和m2的行数不相等。
plot(mSum.get(0, 0))
操作不适用于非正方形矩阵。
某些矩阵运算,包括 matrix.inv()、matrix.det()、matrix.eigenvalues() 和 matrix.eigenvectors(),只适用于正方形矩阵,即行数和列数相同的矩阵。如果尝试在非正方形矩阵上执行这些函数,脚本将提示错误,说明操作不可用或无法计算矩阵 id 的结果。例如:
indicator("Non-square demo")
//@variable A 3x5 matrix.
matrix<float> m = matrix.new<float>(3, 5, 1)
plot(m.det()) // 会引发运行时错误。 无法计算 3x5 矩阵的行列式。
映射·
简介
Pine Script®映射是以键值对形式存储元素的集合。它允许脚本收集与唯一标识符(键)相关联的多个值引用。
与数组和矩阵不同,映射被视为无序集合。脚本通过从键值对中引用键值来快速访问映射的值,而不是遍历内部索引。
映射的键可以是任何基本类型,其值可以是任何内置类型或用户定义类型。映射不能直接使用其他集合(映射、数组或矩阵)作为值,但可以在其字段中保存包含这些数据结构的 UDT 实例。更多信息请参见本节。
与其他集合一样,映射最多可包含 100,000 个元素。由于映射中的每个键值对都由两个元素(唯一键及其相关值)组成,因此映射最多可容纳 50,000 个键值对。
声明映射
Pine Script® 使用以下语法来声明映射:
[var/varip ][map<keyType, valueType> ]<identifier> = <expression>
其中,<keyType, valueType>是map的类型模板,声明了它的键和值的类型,而<expression>返回map实例或na。
在声明分配给 na 的 map 变量时,用户必须在 map 关键字后面加上类型模板,以告诉编译器该变量可以接受 keyType 键类型和 valueType 值类型的映射。
例如,这行代码声明了一个新的 myMap 变量,它可以接受包含成对string键和浮点值的映射实例:
map<string, float> myMap = na
当 <expression> 不是 na 时,编译器不需要显式类型声明,因为它会从分配的映射对象中推断出类型信息。
此语句声明了一个 myMap 变量,该变量分配给一个键为string、值为浮点的空 map。以后分配给该变量的映射必须具有相同的键和值类型:
myMap = map.new<string, float>()
使用 `var` 和 `varip` 关键字
用户可以使用var或varip关键字来指示脚本仅在第一个K线上声明映射变量。使用这些关键字的变量每次脚本迭代中都指向相同的图表实例,直到明确地重新分配为止。
例如,该脚本在第一个图表条上声明了一个colorMap变量,并将其分配给一个保存string键和color值对的映射。脚本在图表上显示一个振荡器,并使用在第一条K线上输入colorMap的值为所有K线着色:
//@version=5
indicator("var map demo")
//@variable 将颜色值与字符串键关联起来的映射.
var colorMap = map.new<string, color>()
// 将 `< string, color>` 对放入第一条K线的 `colorMap` 中.
if bar_index == 0
colorMap.put("Bull", color.green)
colorMap.put("Bear", color.red)
colorMap.put("Neutral", color.gray)
//@variable 14条K线的收盘价相对强弱指数RSI
float oscillator = ta.rsi(close, 14)
//@variable `oscillator`的颜色
color oscColor = switch
oscillator > 50 => colorMap.get("Bull")
oscillator < 50 => colorMap.get("Bear")
=> colorMap.get("Neutral")
// 使用 "colorMap "中的 "oscColor "绘制 "振荡器"。.
plot(oscillator, "Histogram", oscColor, 2, plot.style_histogram, histbase = 50)
plot(oscillator, "Line", oscColor, 3)
使用 varip 声明的映射变量与使用 var 声明的映射变量在历史数据上的行为相同,但它们会在每个新的价格刻度上更新实时K线(即脚本上次编译后的K线)的键值对。分配给 varip 变量的映射只能保存 int、float、bool、color 或string类型的值,或在其字段中专门包含这些类型或这些类型的集合(数组、矩阵或映射)的用户定义类型的值。
读取和写入
map.put() 函数是映射用户经常使用的函数,因为它是将新键值对放入映射的主要方法。它将调用中的 key 参数与 value 参数关联起来,并将键值对添加到映射id 中。
如果 map.put() 调用中的键参数已经存在于映射的键值中,那么传入函数的新键值对将取代现有键值对。
从给定键相关联的映射id中获取值,使用map.get()。如果id映射包含键,该函数将返回值。否则,返回na。
下面的示例利用map.put()和map.get()计算了收盘价最后一次上涨和下跌超过给定长度时的bar_index值之差。当价格上涨时,脚本会将一个("Rising",bar_index)对放入映射;当价格下跌时,脚本将一个("Falling",bar_index)对放入映射。然后,它将包含"Rising"和"Rising"值之间Difference的数据对放入数据图,并将其值绘制在图表上:
//@version=5
indicator("Putting and getting demo")
//@variable ta.rising()`和`ta.falling()`计算的长度.
int length = input.int(2, "Length")
//@variable 将字符串键值与int 值相关联的映射.
var data = map.new<string, int>()
// `close`上升时在`data`映射中放入新的("Rising", `bar_index`)对.
if ta.rising(close, length)
data.put("Rising", bar_index)
//`close`下降时在`data`映射中放入新的("Falling", `bar_index`)对
if ta.falling(close, length)
data.put("Falling", bar_index)
// 将当前 "上升 "和 "下降 "值之间的 "差值 "放入 "数据 "映射中.
data.put("Difference", data.get("Rising")-data.get("Falling"))
//@variable 上一次 "上升 "与 "下降 "之间的差值 `bar_index`.
int index = data.get("Difference")
//@variable 当 `index` 为正值时,返回 `color.green` ;当 `index` 为负值时,返回 `color.red` ;否则返回 `color.gray.
color indexColor = index > 0 ? color.green : index < 0 ? color.red : color.gray
plot(index, color = indexColor, style = plot.style_columns)
请注意:
· 此脚本会在连续调用 data.put() 时替换与 "Rising"、"Falling"和 "Difference "键相关的值,因为这些键都是唯一的,在数据映射中只能出现一次。
· 替换映射中的数据对不会改变键的内部插入顺序。我们将在下一节进一步讨论这个问题。
与处理其他集合类似,在将特殊类型(line, linefill, label, box, 或 table)和用户定义类型的值放入映射时,必须注意插入的键值对的值是指向同一对象,而不是复制它。修改键值对引用的值也会影响原始对象。
例如,此脚本包含一个自定义 ChartData 类型,其中有 o、h、l 和 c 字段。在第一个图表条上,脚本声明了一个 myMap 变量,并添加了一对("A", myData),其中 myData 是一个 ChartData 实例,初始字段值为 na。脚本将数据对("B", myData)添加到myMap中,并通过用户定义的update() 方法在每个K线上更新数据对中的对象。
对 "B "键值对象的每次更改都会影响 "A "键引用的对象,如 "A "对象字段的蜡烛图所示:
//@version=5
indicator("Putting and getting objects demo")
//@type 用于保存 OHLC 数据的自定义类型.
type ChartData
float o
float h
float l
float c
//@function 更新 `ChartData` 对象的字段.
method update(ChartData this) =>
this.o := open
this.h := high
this.l := low
this.c := close
//@variable第一条K线上声明一个新ChartData实例
var myData = ChartData.new()
//@variable string键与ChartData实例关联的映射
var myMap = map.new<string, ChartData>()
// 仅在第一个K线中将带有"A"键的新对放入myMap中
if bar_index == 0
myMap.put("A", myData)
// 在每个K线中将一对带有"B"键的数字放入myMap中
myMap.put("B", myData)
//@variable 与myMap中A键相关联的ChartData值
ChartData oldest = myMap.get("A")
//@variable `myMap`中"B"键相关联的`ChartData`值
ChartData newest = myMap.get("B")
//更新newest。会影响oldest和myData-都引用了ChartData对象。
newest.update()
// 将 `oldest` 的字段绘制成蜡烛图。
plotcandle(oldest.o, oldest.h, oldest.l, oldest.c)
l 如果在每次调用 myMap.put() 时都传递 myData 的拷贝,其行为将有所不同。更多信息,请参阅《用户手册》中有关对象的部分。
检查键和值
检索映射的所有键和值,用map.keys()和map.values()。这些函数将map id中的所有键/值引用复制到一个新的数组对象中。修改两个函数返回的数组不会影响id映射。
虽然map是无序集合,但Pine Script®会在内部维护map键值对的插入顺序。因此,map.keys()和map.values()函数返回的数组总是按照id map的插入顺序排列。
下面的脚本演示了这一点,它每隔 50 个K线在标签中显示来自 m映射的键和值数组。正如我们在图表中看到的,m.keys() 和 m.values() 返回的每个数组中元素的顺序与 m 中键值对的插入顺序一致:

//@version=5
indicator("Keys and values demo")
if bar_index % 50 == 0
//@variable 一个映射,包含成对的`string`键和`float`值。
m = map.new<string, float>()
// 成对地放入`m`。 映射将保持这种插入顺序. 随机整数100内
m.put("First", math.round(math.random(0, 100)))
m.put("Second", m.get("First") + 1)
m.put("Third", m.get("Second") + 1)
//@variable 包含按插入顺序排列的 `m` 键的数组.
array<string> keys = m.keys()
//@variable 一个数组,包含按插入顺序排列的 `m` 值.
array<float> values = m.values()
//@variable 标签显示`m`的`size`以及`keys`和`values`数组.
label debugLabel = label.new(
bar_index, 0,
str.format("Pairs: {0}\nKeys: {1}\nValues: {2}", m.size(), keys, values),
color = color.navy, style = label.style_label_center,
textcolor = color.white, size = size.huge
)
l "First"键的值是 0 到 100 之间的随机整数。Second键的值比 "First"键的值大一个,"Third"键的值比 "Second"键的值大一个。
需要注意的是,在替换键值对时,映射的内部插入顺序不会改变。在这种情况下,新元素在 keys() 和 values() 数组中的位置将与旧元素相同。唯一的例外是脚本事先完全删除了键。
下面,我们添加了一行代码,将带有 "Second "键的新值放入 m映射中,覆盖了与该键相关的前一个值。虽然脚本将这个新的键值对放到了包含"Third"键的键值对之后,但键值对的键和值在Keys数组和Values数组中仍然排在第二位,因为在更改之前,键已经存在于 m 中:

indicator("Keys and values demo")
if bar_index % 50 == 0
//@variable 一个映射,包含成对的 `string` 键和`float` 值。
m = map.new<string, float>()
// 把成对的数据放入 `m`。 映射将保持这种插入顺序。
m.put("First", math.round(math.random(0, 100)))
m.put("Second", m.get("First") + 1)
m.put("Third", m.get("Second") + 1)
// 覆盖 `m` 中的 "第二 "对。 这不会影响插入顺序。
// 键和值仍将出现在 `keys` 和 `values` 数组中的第二位。
m.put("Second", -2)
//@variable 包含按插入顺序排列的 `m` 键的数组。
array<string> keys = m.keys()
//@variable 一个数组,包含按插入顺序排列的 `m` 值。
array<float> values = m.values()
//@variable 显示`m``size`以及`keys`和`values`数组的标签
label debugLabel = label.new(
bar_index, 0,
str.format("Pairs:{0}\nKeys: {1}\nValues: {2}", m.size(), keys, values),
color = color.navy, style = label.style_label_center,
textcolor = color.white, size = size.huge
)
map.values()数组中的元素指向与映射id相同的值。因此,当映射的值是引用类型(包括line, linefill, label, box, table和UDTs)时,修改map.values()数组引用的实例会影响映射id引用的实例,因为两个集合指向相同对象。
map.contains()
要检查特定键是否存在于映射id中,请使用map.contains()。该函数是在 map.keys() 返回的数组上调用 array.includes() 的一种方便的替代方法。
例如,该脚本检查 m映射中是否存在各种键,然后将结果显示在标签中:

//@version=5
indicator("Inspecting keys demo")
//@variable 包含 `string` 键和 `string` 值的映射。
m = map.new<string, string>()
// 将键值对放入映射.
m.put("A", "B")
m.put("C", "D")
m.put("E", "F")
//@variable 要在 `m` 中检查的键的数组.
array<string> testKeys = array.from("A", "B","C","D", "E","F")
//@variable 数组,包含在 `m` 的键中找到的 `testKeys` 中的所有元素.
array<string> mappedKeys = array.new<string>()
for key in testKeys
// 如果 `m` 包含`key`,则将该`key`添加到`mappedKeys`中.
if m.contains(key)
mappedKeys.push(key)
//@variable 字符串,表示 `testKeys` 数组和在 `m` 的键中找到的元素.
string testText = str.format("Tested keys: {0}\nKeys found: {1}", testKeys, mappedKeys)
if bar_index == last_bar_index - 1
//@variable 显示标签中的 `testText` 内容,该标签位于最后一个.
label debugLabel = label.new(
bar_index, 0, testText, style = label.style_label_center,
textcolor = color.white, size = size.huge
)
要从映射id中移除特定的键值对,请使用map.remove()。该函数会从映射中移除键及其相关值,同时保留其他键值对的插入顺序。如果映射包含该键,则返回删除的值。否则,返回na。
要一次性删除映射id中的所有键值对,请使用map.clear()。
下面的脚本创建了一个新的 m map,将键值对放入该 map,在一个循环中使用 m.remove() 删除 removeKeys 数组中列出的每个有效键,然后调用 m.clear() 删除所有剩余的键值对。每次更改后,它都会使用自定义 debugLabel() 方法显示 m 的大小、键值和值:

//@version=5
indicator("Removing key-value pairs demo")
//@function 返回一个标签,用于显示映射中的键和值.
method debugLabel(
map<string, int> this, int barIndex = bar_index,
color bgColor = color.blue, string note = ""
) =>
//@variable 表示此映射中的大小、键和值的字符串.
string repr = str.format(
"{0}\nSize: {1}\nKeys: {2}\nValues: {3}",
note, this.size(), str.tostring(this.keys()), str.tostring(this.values())
)
label.new(
barIndex, 0, repr, color = bgColor, style = label.style_label_center,
textcolor = color.white, size = size.huge
)
if bar_index == last_bar_index - 1
//@variable 一个映射,包含 `string` 键和 `int` 值.
m = map.new<string, int>()
// Put key-value pairs into `m`.
for [i, key] in array.from("A", "B", "C", "D", "E")
m.put(key, i)
m.debugLabel(bar_index, color.green, "Added pairs")
//@variable 要从 `m 中删除的键的数组
array<string> removeKeys = array.from("B", "B", "D", "F", "a")
// 从 `m` 中删除 `removeKeys` 中的每个 `key`。
for key in removeKeys
m.remove(key)
m.debugLabel(bar_index + 10, color.red, "Removed pairs")
// 删除 `m` 中的所有剩余键.
m.clear()
m.debugLabel(bar_index + 20, color.purple, "清除映射")
· 不是removeKeys 数组中的所有string都存在于 m 的键中。试图删除不存在的键(本例中的 "F"、"a "和第二个 "B")对映射的内容没有影响。
脚本可以通过 map.put_all() 将两个映射组合起来。该函数将 id2映射中的所有键值对按插入顺序放入 id1映射中。与 map.put() 一样,如果 id2 中的任何键也出现在 id1 中,该函数会替换包含这些键的键值对,而不影响它们的初始插入顺序。
此示例包含一个用户定义的 hexMap() 函数,用于将十进制 int 键映射为十六进制形式的string表示。脚本使用该函数创建了两个映射,即 mapA 和 mapB,然后使用 mapA.put_all(mapB) 将 mapB 中的所有键值对放入 mapA。
脚本使用自定义 debugLabel() 函数显示标签,显示 mapA 和 mapB 的键和值,然后显示另一个标签,显示将 mapB 的所有键值对放入 mapA 后的内容:
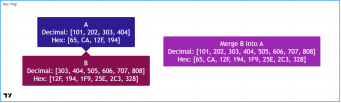
//@version=5
indicator("Combining maps demo", "Hex map")
//@variable 十六进制字符串数组。
var array<string> hexDigits = str.split("0123456789ABCDEF", "")
//@function 为指定的 `value` 返回十六进制字符串。
hex(int value) =>
//@variable 表示 `value` 十六进制形式的字符串。
string result = ""
//@variable 数字计算的临时值。
int tempValue = value
while tempValue > 0
//@variable 下一个整数 digit.
int digit = tempValue % 16
// 将 `digit` 的十六进制形式添加到 `result` 中。.
result := hexDigits.get(digit) + result
// 用 `tempValue` 除以基数.
tempValue := int(tempValue / 16)
result
//@function 返回一个映射,包含键numbers和值hex字符串.
hexMap(array<int> numbers) =>
//@variable 将 `int` 键与 `string` 值关联起来的映射。
result = map.new<int, string>()
for number in numbers
//将包含"numbers"及其"hex()"表示的数据对放入"result"
result.put(number, hex(number))
result
//@function 返回一个标签,用于显示十六进制映射的键和值.
debugLabel(
map<int, string> this, int barIndex = bar_index, color bgColor = color.blue,
string style = label.style_label_center, string note =""
) =>
string repr = str.format(
"{0}\nDecimal: {1}\nHex: {2}",
note, str.tostring(this.keys()), str.tostring(this.values())
)
label.new(
barIndex, 0, repr, color = bgColor, style =style,
textcolor = color.white, size = size.huge
)
if bar_index == last_bar_index - 1
//@variable 包含十进制"int"键和十六进制"string "值的映射.
map<int, string> mapA = hexMap(array.from(101, 202, 303, 404))
debugLabel(mapA, bar_index, color.navy, label.style_label_down, "A")
//@variable 包含键值对的映射,添加到 `mapA`.
map<int, string> mapB = hexMap(array.from(303, 404, 505, 606, 707, 808))
debugLabel(mapB, bar_index, color.maroon, label.style_label_up, "B")
// 将`mapB`中的所有对放入`mapA`中.
mapA.put_all(mapB)
debugLabel(mapA, bar_index + 10, color.purple, note = "Merge B into A")
循环访问映射
脚本可以通过多种方式迭代访问映射中的键和值。例如,脚本可以循环访问映射的 keys() 数组,并获取()每个键的值:
for key in thisMap.keys()
value = thisMap.get(key)
不过,我们建议直接在映射上使用 for...in 循环,因为它会按照插入顺序遍历映射的键值对,每次遍历都会返回一个包含下一对键和值的元组。
例如,这行代码从第一个键值对开始,循环遍历 thisMap 中的每个键值对:
for [key, value] in thisMap
让我们使用这种结构编写一个脚本,在表格中显示映射的键值对。下面示例中,我们定义一个自定义的 toTable()方法创建一个表格,然后使用for...in循环遍历映射的键值对,并填充表格的单元格。脚本使用该方法可视化映射,包含length范围K线的价格和成交量数据的平均值:
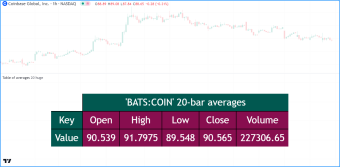
//@version=5
indicator("Looping through a map demo", "Table of averages")
//@variable 移动平均线的长度.
int length = input.int(20, "Length")
//@variable 表格文字的大小.
string txtSize = input.string(
size.huge, "Text size",
options = [size.auto, size.tiny, size.small, size.normal, size.large, size.huge]
)
//@function 显示表格中 `this`映射的数据对。
//@param this 带有 `string` 键和 `float` 值的映射。
//@param position 表格在图表中的位置。
//@param header 要显示在表格顶行的字符串。
//@param textSize 表格中文本的大小。
//@returns 一个新的table对象,其中的单元格显示this中的每个对。
method toTable(
map<string, float> this, string position = position.middle_center, string header = na,
string textSize = size.huge
) =>
// Color variables
borderColor = #000000
headerColor = color.rgb(1, 88, 80)
pairColor = color.maroon
textColor = color.white
//@variable 显示`this`映射的键值对的表格.
table result = table.new(
position, this.size() + 1, 3, border_width = 2, border_color = borderColor
)
// 初始化顶部和侧面页眉单元格.
result.cell(1, 0, header, bgcolor = headerColor, text_color = textColor, text_size = textSize)
result.merge_cells(1, 0, this.size(), 0)
result.cell(0, 1, "Key", bgcolor = headerColor, text_color = textColor, text_size = textSize)
result.cell(0, 2, "Value", bgcolor = headerColor, text_color = textColor, text_size = textSize)
//@variable 表格的列索引。 每次循环迭代时更新.
int col = 1
// 按插入顺序循环查看此映射中的每个 `key` 和`value`。
for [key, value] in this
// 在 "result"表的第 1 行初始化一个 "key "单元格。
result.cell(
col, 1, str.tostring(key), bgcolor = color.maroon,
text_color = color.white, text_size =textSize
)
// 在第 2 行的结果表中初始化一个 `value` 单元格。
result.cell(
col, 2, str.tostring(value), bgcolor = color.maroon,
text_color = color.white, text_size =textSize
)
// 移动到下一列索引.
col += 1
result // 返回 `result` 表格.
//@variable一个包含`string`键和`float`值的映射,用于保存`length`-bar平均值.
averages = map.new<string, float>()
// 将键值对放入 "averages"映射.
averages.put("Open", ta.sma(open, length))
averages.put("High", ta.sma(high, length))
averages.put("Low", ta.sma(low, length))
averages.put("Close", ta.sma(close, length))
averages.put("Volume", ta.sma(volume, length))
//@variable 表格顶部要显示的文字.
string headerText = str.format("{0} {1}-bar averages", "'" + syminfo.tickerid + "'", length)
// 在带有 `headerText` 的 `table` 中显示 `averages`映射.
averages.toTable(header = headerText, textSize = txtSize)
浅层拷贝
脚本可以使用 map.copy() 函数制作映射 id 的浅层拷贝。对浅层拷贝的修改不会影响原始 id映射或其内部插入顺序。
例如,该脚本构建了一个 m映射,其键 "A"、"B"、"C "和 "D "被分配给 0 至 10 之间的四个随机值。然后,脚本创建一个 mCopy映射,作为 m 的浅层拷贝,并更新与其键相关的值。脚本使用我们自定义的 debugLabel() 方法在图表上显示 m 和 mCopy 中的键值对:

//@version=5
indicator("Shallow copy demo")
//@function 在标签中显示 `this`映射的键值对.
method debugLabel(
map<string, float> this, int barIndex = bar_index, color bgColor = color.blue,
color textColor = color.white, string note = ""
) =>
//@variable 标签中要显示的文字.
labelText = note + "\n{"
for [key, value] in this
labelText += str.format("{0}: {1}, ", key, value)
labelText := str.replace(labelText, ", ", "}", this.size() - 1)
if barstate.ishistory
label result = label.new(
barIndex, 0, labelText, color = bgColor, style = label.style_label_center,
textcolor = textColor, size = size.huge
)
if bar_index == last_bar_index - 1
//@variable string键和随机 "float "值的映射.
m = map.new<string, float>()
// 为 `m` 中的键数组分配随机值.
for key in array.from("A", "B", "C", "D")
m.put(key, math.random(0, 10))
//@variable 浅层拷贝 `m`.
mCopy = m.copy()
// 为 `mCopy` 中的每个 `key` 分配插入顺序值 `i`。
for [i, key] in mCopy.keys()
mCopy.put(key, i)
// Display the labels.
m.debugLabel(bar_index, note = "Original")
mCopy.debugLabel(bar_index + 10, color.purple, note = "Copied and changed")
在复制具有基本类型值的映射时,浅层拷贝就足够了,但必须记住,具有引用类型(行、行填充、标签、框、表或 UDT)值的映射的浅层拷贝指向的对象与原始映射指向的对象相同。修改浅层拷贝引用的对象会影响原始映射引用的实例,反之亦然。
为确保对复制的映射所引用的对象所做的更改不会影响其他位置引用的实例,可以通过创建一个新映射来进行深度复制,新映射的键值对包含原始映射中每个值的拷贝。
本示例创建了一个包含string键和标签值的原始映射,并将键值对放入其中。脚本通过内置的 copy() 方法将映射复制到浅层变量,然后使用自定义的 deepCopy() 方法将映射复制到深层变量。
从图表中我们可以看到,对从浅层拷贝中获取的标签所做的更改也会影响原始映射所引用的实例,但对从深层拷贝中获取的标签所做的更改则不会:

//@version=5
indicator("Deep copy demo")
//@function 返回 `this`映射的深层拷贝.
method deepCopy(map<string, label> this) =>
//@variable 此映射的深层拷贝.
result = map.new<string, label>()
// 将键值对和每个`值`的拷贝添加到`结果`中.
for [key, value] in this
result.put(key, value.copy())
result //Return the `result`.
//@variable 包含字符串键和标签值的映射.
var original = map.new<string, label>()
if bar_index == last_bar_index - 1
// 将新的键值对放入 `original`映射。
map.put(
original, "Test",
label.new(bar_index, 0,"Original",textcolor = color.white,size = size.huge)
)
//@variable original映射的浅层拷贝。
map<string, label> shallow = original.copy()
//@variable original映射的深层拷贝.
map<string, label> deep = original.deepCopy()
//@variable shallow拷贝中的 "Test"标签.
label shallowLabel = shallow.get("Test")
//@variable deep "拷贝中的 "test"标签.
label deepLabel = deep.get("Test")
// 修改 `original`映射中 "Test "标签的 `y` 属性。
// 这也会影响`shallowLabel`属性。.
original.get("Test").set_y(label.all.size())
// 修改 `shallowLabel`. 同时修改 `original`映射中的 "Test"(测试)标签。
shallowLabel.set_text("Shallow copy")
shallowLabel.set_color(color.red)
shallowLabel.set_style(label.style_label_up)
// 修改 `deepLabel`. 不修改任何其他标签实例.
deepLabel.set_text("Deep copy")
deepLabel.set_color(color.navy)
deepLabel.set_style(label.style_label_left)
deepLabel.set_x(bar_index + 5)
请注意:
· deepCopy()方法在原始映射中循环,复制每个值,并将包含拷贝的键值对放入一个新的映射实例中。
范围和历史
与 Pine 中的其他集合一样,映射变量会在每个K线上留下历史痕迹,允许脚本使用历史引用操作符 [] 访问分配给变量的过去映射实例。脚本还可以将映射分配给全局变量,并通过函数、方法和条件结构的作用域与之交互。
例如,本脚本使用全局映射及其历史记录来计算一组EMA。它声明了一个包含int键和float值的globalData映射,映射中的每个键值对应于每个 EMA 计算的长度。用户定义的update()函数通过将分配给globalData的上一个映射中的值与当前源值混合,计算每个键长的 EMA。
脚本会绘制全局映射的values()数组中的最大值和最小值,以及globalData.get(50) 的值(即50条K线的 EMA):
//@version=5
indicator("Scope and history demo", overlay = true)
//@variable EMA 计算的源值。
float source = input.source(close, "Source")
//@variable 包含全局键值对的映射.
globalData = map.new<int, float>()
//@function 计算一组 EMA 并更新 `globalData` 中的键值对.
update() =>
//@variable 分配给 `globalData` 的上一个映射实例.
map<int, float> previous = globalData[1]
//previous为na则将键值为10-200的键值对放入globalData中.
if na(previous)
for i = 10 to 200
globalData.put(i, source)
else
// 遍历 "previous "映射中的每个 "key"和 "value"。.
for [key, value] in previous
//@variable key-长度 EMA 的平滑参数.
float alpha = 2.0 / (key + 1.0)
//@variable The `key`-length EMA value.
float ema = (1.0 - alpha) * value + alpha * source
// `key`-length `ema` 放入`globalData` map.
globalData.put(key, ema)
// 更新 `globalData` map.
update()
//@variable 按照插入顺序从 `globalData` 中获取的值的数组.
array<float> values = globalData.values()
// 绘制 max EMA, min EMA, 及 50-bar EMA values.
plot(values.max(), "Max EMA", color.green, 2)
plot(values.min(), "Min EMA", color.red, 2)
plot(globalData.get(50), "50-bar EMA", color.orange, 3)
映射不能直接使用其他映射、数组或矩阵作为值,但可以保存用户定义类型的值,这种类型的字段中包含集合。
假设我们想创建一个"2D "映射,使用string键访问嵌套映射,嵌套映射包含string键和float数值对。由于映射不能使用其他集合作为值,因此我们首先创建一个封装类型,设置一个字段来保存map<string, float>实例,如下所示:
//@type 具有字符串键和浮点数值的映射的封装类型.
type Wrapper
map<string, float> data
定义了 Wrapper 类型后,我们就可以创建string键和 Wrapper 值的映射,其中映射中每个值的数据字段都指向 map<string, float> 实例:
mapOfMaps = map.new<string, Wrapper>()
下面的脚本使用了这一概念,构建了一个包含从多个股票代码请求OHLCV数据的映射。用户定义的requestData()函数从一个股票代码请求价格和交易量数据,创建一个<string, float>映射,将数据放入其中,然后返回一个包含新映射的 Wrapper 实例。
脚本会将每次调用requestData()的结果放入mapOfMaps中,然后使用用户定义的toString()方法创建嵌套映射的string表示,并以标签形式显示在图表上:
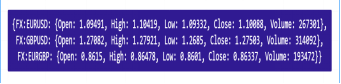
//@version=5
indicator("Nested map demo")
//@variable 所需数据的时间框架.
string tf = input.timeframe("D", "Timeframe")
// Symbol inputs.
string symbol1 = input.symbol("EURUSD", "Symbol 1")
string symbol2 = input.symbol("GBPUSD", "Symbol 2")
string symbol3 = input.symbol("EURGBP", "Symbol 3")
//@type 映射的封装类型,键为字符串,值为浮点数。
type Wrapper
map<string, float> data
//@function返回包装的映射,包含`tickerID`在`timeframe`的OHLCV
requestData(string tickerID, string timeframe) =>
// 从指定的股票代码和时间框架中获取 OHLCV 值的元组.
[o, h, l, c, v] = request.security(
tickerID, timeframe,
[open, high, low, close, volume]
)
//@variable 包含所请求的 OHLCV 数据的映射.
result = map.new<string, float>()
// 将键值对放入 `result`.
result.put("Open", o)
result.put("High", h)
result.put("Low", l)
result.put("Close", c)
result.put("Volume", v)
//返回包装后的 `result`.
Wrapper.new(result)
//@function返回一个字符串,表示由`string`键和`Wrapper`值组成的`this`映射.
method toString(map<string, Wrapper> this) =>
//@variable 字符串表示 `this` map.
string result = "{"
// 遍历 `this` 中的每个 `key1` 和相关 `wrapper`.
for [key1, wrapper] in this
// 添加 `key1` 到 `result`.
result += key1
//@variable wrapper.data`映射的字符串表示。
string innerStr = ": {"
// 遍历封装映射中的每个 `key2` 和相关 `value`.
for [key2, value] in wrapper.data
// 将键值对的表示添加到 `innerStr` 中.
innerStr += str.format("{0}: {1}, ",key2,str.tostring(value))
// 用"}"替换 `innerStr` 的末尾并添加到 `result` 中.
result+=str.replace(innerStr,",","},\n",wrapper.data.size()-1)
// 用"}"替换 "result "末尾的空行.
result := str.replace(result, ",\n", "}",this.size() - 1)
result
//@variable 包含来自多个股票代码的 OHLCV 数据的封装映射图.
var mapOfMaps = map.new<string, Wrapper>()
//@variable 标签上显示 `mapOfMaps`.
var debugLabel = label.new(
bar_index, 0, color = color.navy, textcolor = color.white, size = size.huge,
style = label.style_label_center, text_font_family = font.family_monospace
)
// 将包裹好的映射放入 `mapOfMaps`.
mapOfMaps.put(symbol1, requestData(symbol1, tf))
mapOfMaps.put(symbol2, requestData(symbol2, tf))
mapOfMaps.put(symbol3, requestData(symbol3, tf))
// 更新标签.
debugLabel.set_text(mapOfMaps.toString())
debugLabel.set_x(bar_index)
概念
简介
TradingView警报全天候在我们的服务器上运行,用户无需登录即可执行。警报通过图表用户界面(UI)创建。您可在帮助中心的"Help Center’s About TradingView alerts"页面找到所有必要信息,了解警报如何工作以及如何从图表用户界面创建警报。
TradingView 上的某些警报类型(通用警报、绘图警报和订单成交事件脚本警报)是通过图表上加载的商品或脚本创建的,不需要特定的编码。任何用户都可以从图表用户界面创建这些类型的警报。
其他类型的警报(通过调用alert()函数触发的脚本警报以及alertcondition()警报)则需要在脚本中加入特定的 Pine Script® 代码以创建警报事件,然后脚本用户才能使用图表用户界面创建警报。此外,虽然脚本用户可以通过图表用户界面创建触发订单成交事件的脚本警报,但程序员可以在脚本中为经纪商模拟器成交的每种订单指定明确的订单成交警报信息。
本页将介绍Pine Script®程序员在编写脚本时创建警报事件的不同方法,脚本用户可以通过这些警报事件在图表用户界面上创建警报。我们将介绍:
l 如何使用alert()函数在指标或策略中调用alert()函数,然后将其包含在从图表用户界面创建的脚本警报中。
l 如何添加自定义警报信息,以包含在策略订单成交事件触发的脚本警报中。
l 如何仅在指标中使用 alertcondition()函数生成 alertcondition() 事件,这些事件可用于从图表用户界面创建 alertcondition() 警报。
请记住:
l 任何与警报相关的Pine Script®代码都不能在图表用户界面中创建运行中的警报;它只能创建警报事件,然后脚本用户可以使用这些事件在图表用户界面中创建运行中的警报。
l 警报只能在实时K线中触发。因此,处理任何类型警报的Pine Script®代码的运行范围仅限于实时K线。
l 在图表用户界面中创建警报时,TradingView会保存脚本及其输入的镜像,以及图表的主要商品和时间框架,以便在其服务器上运行警报。因此,对脚本输入或图表的后续更改不会影响运行之前用它们创建的警报。如果想在运行中的警报行为中反映对上下文的任何更改,则需要删除警报,并在新的上下文中创建新警报。
背景
如今,Pine程序员可以使用不同的方法在脚本中创建警报事件,这是Pine Script®在发展过程中不断改进的结果。alertcondition()函数仅适用于指标,是Pine Script®程序员创建警报事件的第一个功能。随后,当经纪商模拟器产生订单成交事件时,就会触发策略订单成交警报。订单成交事件不需要特别的代码,脚本用户就可以创建警报,但通过订单生成Strategy.*()函数的警报信息参数,程序员可以自定义订单成交事件触发的警报信息,为任意数量的订单成交事件定义不同的警报信息。
alert()函数是Pine Script®的最新功能。它或多或少地取代了alertcondition()函数,在策略中使用时,可为订单成交事件警报提供有用的补充。
哪种类型的警报最好?
对于Pine Script®程序员来说,使用alert()函数通常更简单、更灵活。与alertcondition()相反,它允许动态警报信息,在指标和策略中均可使用,而且程序员可自行决定alert()事件的频率。
虽然alert()调用可在 Pine 中的任何可编程逻辑上生成,包括在策略中向经纪商模拟器发送订单时生成,但不能在订单执行(或成交)时触发alert()调用,因为订单发送到经纪商模拟器后,模拟器会控制其执行,不会直接向脚本报告成交事件。
当脚本用户希望根据策略的订单成交事件生成警报时,必须在"Create Alert"对话框中创建策略的脚本警报时包含这些事件。用户不需要在脚本中编写特殊代码就能做到这一点。不过,程序员可以通过使用订单生成Strategy.*()函数调用中的 alert_message 参数,自定义订单成交事件发送的信息。调用alert()函数和在订单生成Strategy.*()函数调用中使用自定义 alert_message 参数相结合,应能让程序员在执行脚本时针对大多数情况生成警报事件。
Pine Script®中保留了alertcondition()函数,以实现向后兼容,但它也可用于生成不同的警报,供在 "Create Alert"对话框的 "Condition"字段中作为单独项目进行选择。
脚本警报
脚本用户使用“创建警报”("Create Alert")对话框创建脚本警报时,能够触发警报的事件会有所不同,具体取决于警报是由指标还是策略创建的。
从指标创建的脚本警报将在以下情况下触发:
l 指标包含 alert()调用。
l 代码逻辑允许执行特定的alert()调用。
l alert()调用中指定的频率允许触发警报。
从策略中创建的脚本警报可在调用alert()函数、订单成交事件或两者同时发生时触发。在策略上创建警报的脚本用户可自行决定在脚本警报中包含哪类事件。虽然用户可以根据订单成交事件创建脚本警报,而无需在策略中加入特殊代码,但策略必须包含alert()调用,用户才能在脚本警报中加入alert()函数调用。
alert() "函数事件
alert()函数的签名如下:
alert(message, freq)
表示警报触发时发送的信息文本的"series string"。由于该参数允许使用"series"形式,因此可以在运行时生成,并根据不同的K线而有所不同,从而使其具有动态性。
“input string"指定警报的触发频率。有效参数为:
l alert.freq_once_per_bar:只有每个实时K线的第一次调用才会触发警报(默认值)。
l alert.freq_once_per_bar_close:只有当实时K线关闭且在脚本迭代期间执行alert()调用时,才会触发警报。
l alert.freq_all:实时K线期间所有调用都会触发警报。
alert()函数可在指标和策略中使用。要使alert()调用触发根据alert()函数调用配置的脚本警报,脚本的逻辑必须允许alert()调用执行,并且由freq 参数决定的频率必须允许警报触发。
请注意,默认情况下,策略在K线收盘时重新计算,因此如果在策略中使用了频率为alert.freq_all或alert.freq_once_per_bar的alert()函数,那么它在K线收盘时被调用的次数不会超过一次。为了在构建K线过程中调用 alert()函数,需要启用calc_on_every_tick选项。
使用每次"alert()"调用
让我们来看一个检测 RSI 中心线交叉的示例:
//@version=5
indicator("All `alert()` calls")
r = ta.rsi(close, 20)
//检测交叉点.
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
//触发交叉点警报.
if xUp
alert("Go long (RSI is " + str.tostring(r, "#.00)"))
else if xDn
alert("Go short (RSI is " + str.tostring(r, "#.00)"))
plotchar(xUp, "Go Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(xDn, "Go Short", "▼", location.top, color.red, size = size.tiny)
hline(50)
plot(r)
如果根据该脚本创建了脚本警报:
l 当 RSI 向上穿越中线时,脚本警报将触发 "Go long...... "信息。当 RSI 穿过中线向下时,脚本警报将以 "Go short...... "信息触发。
l 由于没有为 alert()调用中的 freq 参数指定参数,因此将使用 alert.freq_once_per_bar 的默认值,因此警报只会在实时K线期间首次执行alert()调用时触发。
l 随警报发送的信息由两部分组成:一个常量字符串和 str.tostring()调用的结果,其中包括脚本执行 alert()调用时的 RSI 值。交叉盘上涨的警报信息如下 "做多(RSI 为 53.41)"。
l 因为只要调用的频率允许,脚本警报总是在调用alert()的任何情况下触发,所以这个脚本不允许脚本用户将脚本警报仅限于多头。
请注意:
l 与总是放在第0列(脚本的全局作用域)的 alertcondition()调用相反,alert()调用被放在if分支的局部作用域中,因此只有当触发条件满足时才会执行。如果将alert()调用放在脚本全局作用域,它就会在所有K线上执行,这很可能不是我们想要的行为。
l An alertcondition() 不能接受与我们用于警报信息的字符串相同的字符串,因为它使用了 str.tostring()调用。alertcondition() 信息必须是常量字符串。
最后,由于alert()消息可以在运行时动态生成,因此我们可以使用以下代码生成警报事件:
if xUp or xDn
firstPart = (xUp ? "Go long" : "Go short") + " (RSI is "
alert(firstPart + str.tostring(r, "#.00)"))
使用选择性的"alert()"调用
当用户在alert()函数调用上创建脚本警报时,只要满足频率限制,脚本对alert()函数的任何调用都会触发警报。如果要让脚本的用户选择脚本中的哪个alert()函数调用会触发脚本警报,就需要在脚本的输入中为用户提供指明其偏好的方法,并在脚本中编写相应的逻辑代码。这样,脚本用户就能从一个脚本中创建多个脚本警报,每个警报都会根据在图表用户界面中创建警报之前在脚本输入中所做的选择而有不同的表现。
在下一个示例中,假设我们想提供仅对多头、空头或两者触发警报的选项。您可以这样编写脚本:
//@version=5
indicator("Selective `alert()` calls")
detectLongsInput = input.bool(true, "Detect Longs")
detectShortsInput = input.bool(true, "Detect Shorts")
repaintInput = input.bool(false, "Allow Repainting")
r = ta.rsi(close, 20)
// Detect crosses.
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
// 只有当输入中允许交易方向时,才会生成条目。
enterLong = detectLongsInput and xUp and (repaintInput or barstate.isconfirmed)
enterShort = detectShortsInput and xDn and (repaintInput or barstate.isconfirmed)
// 仅在满足复合条件时触发警报.
if enterLong
alert("Go long (RSI is " + str.tostring(r, "#.00)"))
else if enterShort
alert("Go short (RSI is " + str.tostring(r, "#.00)"))
plotchar(enterLong, "Go Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(enterShort, "Go Short", "▼", location.top, color.red, size = size.tiny)
hline(50)
plot(r)
请注意:
l 创建一个复合条件,只有当用户的选择允许向该方向输入时该条件才会满足。只有在"输入(Inputs)"中启用多头输入时,中心线交叉处的多头输入才会触发警报。
l 为用户提供了重绘的选项。当用户不允许重新绘制计算结果时,我们会等到K线确认后触发复合条件。这样,警报和标记只会在实时K线结束时出现。
l 如果用户想通过本脚本创建两个不同的脚本警报,即一个只在多头时触发,另一个只在空头时触发,那么他需要:
n 在输入中只选择"Detect Longs(检测多头)",然后在脚本上创建第一个脚本警报。
n 在输入中只选择"Detect Shorts(检测空头)",并在脚本上创建另一个脚本警报。
在策略中(使用Alert())
也可以在策略中使用alert()函数调用,但前提是策略默认只在实时K线收盘时执行。除非在strategy()声明语句中使用 calc_on_every_tick = true,否则所有 alert()调用都将使用 alert.freq_once_per_bar_close 频率,与 freq 使用的参数无关。
策略上的脚本警报将使用订单成交事件,在经纪商模拟器成交订单时触发警报,而alert()则可用于在策略中生成其他警报事件。
当 RSI 连续三根K线出现不利于交易的移动时,该策略会创建alert()函数调用:
//@version=5
strategy("Strategy with selective `alert()` calls")
r = ta.rsi(close, 20)
// 检测交叉点.
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
// 在交叉点上下单。
if xUp
strategy.entry("Long", strategy.long)
else if xDn
strategy.entry("Short", strategy.short)
// 当 RSI 与交易方向背离时触发警报。
divInLongTrade = strategy.position_size > 0 and ta.falling(r, 3)
divInShortTrade = strategy.position_size < 0 and ta.rising( r, 3)
if divInLongTrade
alert("WARNING: Falling RSI", alert.freq_once_per_bar_close)
if divInShortTrade
alert("WARNING: Rising RSI", alert.freq_once_per_bar_close)
plotchar(xUp, "Go Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(xDn, "Go Short", "▼", location.top, color.red, size = size.tiny)
plotchar(divInLongTrade, "WARNING: Falling RSI", "•", location.top, color.red, size = size.tiny)
plotchar(divInShortTrade, "WARNING: Rising RSI", "•", location.bottom, color.lime, size = size.tiny)
hline(50)
plot(r)
如果用户根据该策略创建一个脚本警报,并在警报中包含订单成交事件和alert()函数调用,那么只要订单被执行,或者脚本在实时K线收盘迭代时执行了其中一个alert()调用,即当barstate.isrealtime和barstate.isconfirmed均为true时,警报就会触发。alert()函数事件只会在实时K线关闭时触发警报,因为alert.freq_once_per_bar_close是alert()调用中freq参数使用的参数。
订单填充事件
从指标创建脚本警报时,只能在调用alert()函数时触发。不过,当从策略创建脚本警报时,用户可以指定订单成交事件也触发脚本警报。订单成交事件是指经纪商模拟器生成的、导致执行模拟订单的任何事件。它相当于经纪人/交易所执行交易订单。下单后不一定会执行。在策略中,只能通过分析strategy.openentrades或strategy.position_size等内置变量的变化来间接和事后检测订单的执行情况。 因此,根据订单成交事件配置的脚本警报功能非常有用,它可以在脚本逻辑检测到订单执行之前,在订单执行的精确时刻触发警报。
Pine Script® 程序员可以自定义在执行特定订单时发送的警报信息。虽然这并不是触发订单成交事件的先决条件,但自定义警报信息非常有用,因为它们允许在警报中包含自定义语法,以便将实际订单发送到第三方执行引擎等。为特定订单成交事件指定自定义警报信息的方法是在可生成订单的函数中使用alert_message参数:trategy.close()、strategy.entry()、strategy.exit()和strategy.order()。
alert_message参数使用的参数是"series string",因此可以使用脚本可用的任何变量动态构建,只要将其转换为字符串格式即可。
让我们来看看在两个strategy.entry()调用中都使用了alert_message参数的策略:
//@version=5
strategy("Strategy using `alert_message`")
r = ta.rsi(close, 20)
// Detect crosses.
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
// 针对每个交叉点使用自定义警报信息下单.
if xUp
strategy.entry("Long", strategy.long, stop = high, alert_message = "Stop-buy executed (stop was " + str.tostring(high) + ")")
else if xDn
strategy.entry("Short", strategy.short, stop = low, alert_message = "Stop-sell executed (stop was " + str.tostring(low) + ")")
plotchar(xUp, "Go Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(xDn, "Go Short", "▼", location.top, color.red, size = size.tiny)
hline(50)
plot(r)
请注意:
l 我们在调用 strategy.entry() 时使用了stop参数,从而创建了停止买入和停止卖出订单。这意味着只有当价格高于下单所在K线的最高价时,买入订单才会执行,而只有当价格低于下单所在K线的最低价时,卖出订单才会执行。
l 我们用 plotchar() 绘制的向上/向下箭头是在下单时绘制的。在订单实际执行之前,可能会经过任意数量的K线,在某些情况下,由于价格不满足所需的条件,订单永远不会执行。
l 因为我们对所有买入订单都使用相同的 id 参数,所以在前一个订单的条件满足之前下达的任何新买入订单都将取代该订单。卖出订单也是如此。
l 包含在alert_message参数中的变量在订单执行时进行评估,因此在警报触发时也是如此。
在策略的订单生成strategy.*()函数调用中使用alert_message参数时,脚本用户在创建订单成交事件的脚本警报时,必须在“创建警报”对话框的"消息"字段中包含{{strategy.order.alert_message}}占位符。这样,订单生成Strategy.*()函数调用中使用的警报信息参数就会被用于每个订单成交事件触发的警报信息中。如果只在"消息"字段中使用{{strategy.order.alert_message}}占位符,且策略中只有部分订单生成Strategy.*()函数调用中存在alert_message参数,则在任何未使用alert_message参数的订单生成 Strategy.*()函数调用触发的警报消息中,空字符串将取代占位符。
虽然用户可以在“创建警报”对话框的"消息"字段中使用其他占位符来创建订单成交事件警报,但不能在 alert_message 的参数中使用这些占位符。
alertcondition()事件
使用alertcondition()函数,程序员可以在其指标中创建单个警报条件事件。一个指标可以包含多个 alertcondition()调用。脚本中对alertcondition()的每次调用都会创建一个相应的警报,可在“创建警报”对话框的“条件”下拉菜单中进行选择。
虽然在策略脚本中调用alertcondition()不会导致编译错误,但无法从中创建警报。
alertcondition()函数的签名如下:
alertcondition(condition, title, message)
condition条件:
一个"series bool "值(真或假),用于确定何时触发警报。这是一个必填参数。当值为true时,警报将触发。当值为假时,警报不会触发。与alert()函数调用相反,alertcondition()调用必须从一行语句的第0列开始(顶格),因此不能放在条件块中。
title标题:
"const string "可选参数,用于设置警报条件的名称,该名称将显示在图表用户界面的"Create Alert"对话框的"Condition"字段中。如果没有提供参数,将使用" Alert"。
message消息:
一个"const string "可选参数,用于指定触发警报时要显示的文本信息。文本将显示在 "Create Alert"对话框的 "message"字段中,脚本用户可在创建警报时对其进行修改。由于该参数必须是"const string",因此必须在编译时就知道,而且不能逐条K线更改。不过,它可以包含占位符,这些占位符在运行时被动态值取代,而动态值可能会逐条更改。请参见手册的占位符部分。
alertcondition()不包含freq参数。alertcondition()警报的频率由用户在“创建警报”对话框中决定。
使用一个条件
以下是创建 alertcondition() 事件的代码示例:
//@version=5
indicator("`alertcondition()` on single condition")
r = ta.rsi(close, 20)
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
plot(r, "RSI")
hline(50)
plotchar(xUp, "Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(xDn, "Short", "▼", location.top, color.red, size = size.tiny)
alertcondition(xUp, "Long Alert", "Go long")
alertcondition(xDn, "Short Alert", "Go short ")
由于我们的脚本中有两个 alertcondition()调用,因此在“创建警报”对话框的“条件”字段中会出现两个不同的警报:"Long Alert"和"Short Alert"。
如果我们想在交叉点发生时包含 RSI 值,就不能像在 alert()调用或策略中的 alert_message 参数中那样,简单地使用 str.tostring(r) 将其值添加到消息字符串中。不过,我们可以使用占位符将其包含在内。这显示了两种选择:
alertcondition(xUp, "Long Alert", "Go long. RSI is {{plot_0}}")
alertcondition(xDn, "Short Alert", 'Go short. RSI is {{plot("RSI")}}')
请注意:
l 第一行使用 {{plot_0}} 占位符,其中的plot编号与脚本中plot的顺序相对应。
l 第二行使用了 {{plot("[plot_title]")}}} 类型的占位符,其中必须包含脚本中用于绘制 RSI 的 plot()调用的标题。双引号用于将 plot 的标题包在 {{plot("RSI")}} 占位符内。这就要求我们使用单引号来封装消息字符串。
l 使用其中一种方法,我们可以包含我们的指标绘制的任何数值,但由于字符串不能绘制,因此不能使用字符串变量。
使用复合条件
如果我们想为脚本用户提供使用多个 alertcondition()调用从指标创建单个警报的可能性,我们就需要在脚本的输入中提供选项,让用户在创建警报前指明他们希望触发警报的条件。
本脚本演示了一种方法:
//@version=5
indicator("`alertcondition()` on multiple conditions")
detectLongsInput = input.bool(true, "Detect Longs")
detectShortsInput = input.bool(true, "Detect Shorts")
r = ta.rsi(close, 20)
// Detect crosses.
xUp = ta.crossover( r, 50)
xDn = ta.crossunder(r, 50)
//只有在输入允许交易方向时才生成条目.
enterLong = detectLongsInput and xUp
enterShort = detectShortsInput and xDn
plot(r)
plotchar(enterLong, "Go Long", "▲", location.bottom, color.lime, size = size.tiny)
plotchar(enterShort, "Go Short", "▼", location.top, color.red, size = size.tiny)
hline(50)
// 满足其中一个条件时触发警报.
alertcondition(enterLong or enterShort, "Compound alert", "Entry")
请注意,alertcondition()调用可在两个条件之一触发。只有当用户在创建警报前在脚本的输入中启用该条件时,每个条件才能触发警报。
占位符
占位符可在alertcondition()调用的message参数中使用,当警报触发时被动态值取代,是在alertcondition()消息中包含动态值(可逐K线变化的值)的唯一方法。
注意,用户可通过图表UI的"Create Alert"对话框创建alertcondition()警报,也可在对话杠的"Message"字段中使用这些占位符创建报警。
{{exchange}}
警报中使用的交易商品(NASDAQ、NYSE、MOEX 等)。请注意,对于延迟商品,交易所将以"_DL "或"_DLY "结尾。例如,"NYMEX_DL"。
{{interval}}
返回创建警报的图表的时间框架。请注意,Range图表(区间K线图)基于1m数据计算,因此在Range图表上创建的任何警报,占位符都将返回 "1"。
{{open}}、{{high}}、{{low}}、{{close}}、{{volume}}。
触发警报的K线的相应值。
{{plot_0}}, {{plot_1}}, [...], {{plot_19}}
相应plot编号的值。Plot在脚本中按出现顺序从0到19依次编号,因此只能使用前20个plot中的一个。例如,内置的"Volume"指标有两个输出系列:成交量和成交量 MA,因此可以使用以下代码:
alertcondition(volume > sma(volume,20), "Volume alert", "Volume ({{plot_0}}) > average ({{plot_1}})")
{{plot("[plot_title]")}}
当需要使用 plot()调用中的title参数来引用绘图时,可以使用该占位符。请注意,必须在占位符内使用双引号(")来封装title参数。这就要求使用单引号(')来封装消息字符串:
//@version=5
indicator("")
r = ta.rsi(close, 14)
xUp = ta.crossover(r, 50)
plot(r, "RSI", display = display.none)
alertcondition(xUp, "xUp alert", message='RSI is bullish at: {{plot("RSI")}}')
{{ticker}}
警报中使用的商品代码(AAPL、BTCUSD 等)。
{{time}}
返回K线开始时的时间。时间为UTC,格式为 yyyy-MM-ddTHH:mm:ssZ,例如:2019-08-27T09:56:00Z。
{{timenow}}
警报触发时的当前时间,格式与 {{time}} 相同。精度精确到秒,与图表的时间框架无关。
使用警报避免重绘
交易者希望通过警报避免重绘的最常见情况是,他们必须防止警报在实时K线期间的某一时刻触发,而该警报在收盘时本不会触发。满足这些条件时就会发生这种情况:
· 触发警报的条件中使用的计算在实时K线中可能会发生变化。例如,任何使用最高价、最低价或收盘价的计算都会出现这种情况,其中包括几乎所有内置指标。使用比图表更高的时间框架调用 request.security() 的结果也会出现这种情况,因为更高的时间框架的当前K线尚未关闭。
· 警报可以在实时K线收盘前触发,因此可以用“Once Per Bar Close”以外的任何频率触发。
避免此类重绘的最简单方法是配置警报的触发频率,使其仅在实时K线收盘时触发。没有万能药;避免这种类型的重绘总是需要等待确认信息,这意味着交易者必须牺牲即时性来实现可靠性。
请注意,其他类型的再绘制(如Repainting部分中记录的那些类型)可能无法通过简单地在实时K线收盘时触发警报来避免。
背景着色
bgcolor()函数用于更改脚本背景的颜色。如果脚本在overlay = true 模式下运行,那么它将为图表背景着色。
函数的签名是:
bgcolor(color, offset, editable, show_last, title) → void
它的 color 参数允许使用 "series color"作为参数,因此可以在表达式中动态计算。
如果要使用的颜色中不含合适的透明度,则可以使用 color.new()函数生成。
下面是一个为交易时段背景着色的脚本(以 30 分钟欧元兑美元为例进行尝试):
//@version=5
indicator("Session backgrounds", overlay = true)
//默认颜色常数的透明度为 25。
BLUE_COLOR = #0050FF40
PURPLE_COLOR = #0000FF40
PINK_COLOR = #5000FF40
NO_COLOR = color(na)
// 允许用户更改颜色。
preMarketColor = input.color(BLUE_COLOR, "Pre-market")
regSessionColor = input.color(PURPLE_COLOR, "Pre-market")
postMarketColor = input.color(PINK_COLOR, "Pre-market")
// 当K线处于时间范围内时,函数返回ture
timeInRange(tf, session) =>
time(tf, session) != 0
// 功能在图表右下方打印一条信息。
f_print(_text) =>
var table _t = table.new(position.bottom_right, 1, 1)
table.cell(_t, 0, 0, _text, bgcolor = color.yellow)
var chartIs30MinOrLess = timeframe.isseconds or (timeframe.isintraday and timeframe.multiplier <=30)
sessionColor = if chartIs30MinOrLess
switch
timeInRange(timeframe.period, "0400-0930") => preMarketColor
timeInRange(timeframe.period, "0930-1600") => regSessionColor
timeInRange(timeframe.period, "1600-2000") => postMarketColor
=> NO_COLOR
else
f_print("No background is displayed.\nChart timeframe must be <= 30min.")
NO_COLOR
bgcolor(sessionColor)
l 脚本仅适用于 30 分钟或更短的图表时间框架。当图表的时间框架大于 30 分钟时,脚本会打印错误信息。
l 由于图表的时间框架不正确而使用 if 结构的 else 分支时,本绘制会返回 NO_COLOR 颜色,因此在这种情况下不会显示背景。
l 我们首先使用基本颜色初始化常量,其中包括末尾以十六进制表示的 40 透明度。在 Pine Script® 的 0-100 十进制透明度标尺中,40 对应 00-FF 十六进制透明度标尺中的 75。
l 提供了颜色输入,允许脚本用户更改我们建议的默认颜色。
下一示例中,我们将为CCI行的背景生成一个渐变色:
//@version=5
indicator("CCI Background")
bullColor = input.color(color.lime, "↑", inline = "1")
bearColor = input.color(color.fuchsia, "↓", inline = "1")
// 计算 CCI。商品路径指标、顺势指标
myCCI = ta.cci(hlc3, 20)
// 以 0-100% 的比例获取 CCI 在最近 100 个K线中的相对位置。
myCCIPosition = ta.percentrank(myCCI, 100)
//当位置为 50-100% 时生成牛梯度,当位置为 0-50% 时生成熊梯度。
backgroundColor = if myCCIPosition >= 50
color.from_gradient(myCCIPosition, 50, 100, color.new(bullColor, 75), bullColor)
else
color.from_gradient(myCCIPosition, 0, 50, bearColor, color.new(bearColor, 75))
//更宽的白色线条背景。
plot(myCCI, "CCI", color.white, 3)
//想象一下黑线。
plot(myCCI, "CCI", color.black, 1)
// 零级。
hline(0)
// 渐变背景
bgcolor(backgroundColor)
· 我们使用 ta.cci() 内置函数计算指标值。
· 我们使用 ta.percentrank() 内置函数计算 myCCIP position,即在过去 100 个K线中,myCCI 值低于当前值的百分比。
· 为了计算梯度,我们使用了 color.from_gradient() 内置函数的两个不同调用:一个是当 myCCIP 位置在 50-100% 范围内时的牛市梯度,这意味着更多的过去值低于其当前值;另一个是当 myCCIP 位置在 0-49.99% 范围内时的熊市梯度,这意味着更多的过去值高于其当前值。
· 我们提供输入,用户可以更改牛市/熊市颜色,我们将两个颜色输入窗口部件放在同一行,在两个 input.color()调用中使用 inline = "1"。
· 我们使用两个plot()调用绘制CCI信号,以在杂乱的背景上实现最佳对比:第一个绘线是3像素宽的白色背景,第二个plot()绘制1像素宽的黑色细线。
K线着色
使用 barcolor()函数可以为图表K线着色。它是唯一一个允许在窗格中运行的脚本影响图表的 Pine Script®函数。
该函数的签名如下:
barcolor(color, offset, editable, show_last, title) → void
由于color参数接受 "series color"参数,因此着色可以是有条件的。
下面的脚本用不同的颜色显示内部和外部K线:
//@version=5
indicator("barcolor example", overlay = true)
isUp = close > open
isDown = close <= open
isOutsideUp = high > high[1] and low < low[1] and isUp
isOutsideDown = high > high[1] and low < low[1] and isDown
isInside = high < high[1] and low > low[1]
barcolor(isInside ? color.yellow : isOutsideUp ? color.aqua : isOutsideDown ? color.purple:na)
l "na "值会使K线保持原样。
l 在 barcolor()调用中,我们使用嵌入的 ?: 三元运算符表达式来选择颜色。
K线绘制
简介
plotcandle() 内置函数用于绘制蜡烛图,而 plotbar() 则用于绘制常规K线。
这两个函数都需要四个参数,用于绘制K线的 OHLC 价格(开盘价、最高价、最低价、收盘价)。如果其中一个参数为空,则不会绘制K线。
使用 `plotcandle()` 绘制蜡烛图
plotcandle() 的签名是:
plotcandle(open, high, low, close, title, color, wickcolor, editable, show_last, bordercolor, display) → void
在单独窗格中使用OHLC绘制简单的蜡烛图,所有蜡烛均为蓝色:
indicator("Single-color candles")
plotcandle(open, high, low, close)
要将它们染成绿色或红色,我们可以使用以下代码:
indicator("Example 2")
paletteColor = close >= open ? color.lime : color.red
plotbar(open, high, low, close, color = paletteColor)
请注意,color参数接受"series color"参数,因此诸如 color.red、color.lime、"#FF9090" 等常量值,以及在运行时计算颜色的表达式(如此处使用的paletteColor变量)都可以使用。
您可以使用实际 OHLC 值以外的值构建K线或蜡烛图。例如,您可以使用以下代码计算和绘制平滑蜡烛图,该代码还可以根据收盘价相对于我们指标的平滑收盘价 (c) 的位置为蜡烛芯着色:
indicator("Smoothed candles", overlay = true)
lenInput = input.int(9)
smooth(source, length) =>
ta.sma(source, length)
o = smooth(open, lenInput)
h = smooth(high, lenInput)
l = smooth(low, lenInput)
c = smooth(close, lenInput)
ourWickColor = close > c ? color.green : color.red
plotcandle(o, h, l, c, wickcolor = ourWickColor)
您可能会发现,绘制更高时间框架的 OHLC 值非常有用。例如,您可以在盘中图表上绘制日线图:
// 注意:在盘中图表上使用此脚本。
//@version=5
indicator("Daily bars")
// 使用gaps参数,仅在1D时间框架结束时返回数据,否则返回`na。
[o, h, l, c] = request.security(syminfo.tickerid, "D", [open, high, low, close], gaps = barmerge.gaps_on)
var color UP_COLOR = color.silver
var color DN_COLOR = color.blue
color wickColor = c >= o ? UP_COLOR : DN_COLOR
color bodyColor = c >= o ? color.new(UP_COLOR, 70) : color.new(DN_COLOR, 70)
// 只在日内时间框架上绘制蜡烛图、
//以及当 `request.security()`返回非 `na` 值(因 HTF 已完成)。
plotcandle(timeframe.isintraday ? o : na, h, l, c, color = bodyColor, wickcolor = wickColor)
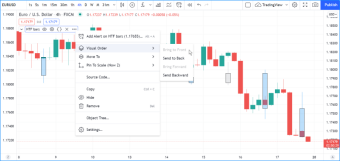
请注意:
l 我们在脚本的"更多"菜单中使用"视觉顺序/置于顶层"后显示脚本的曲线图。这将使脚本的蜡烛图显示在图表蜡烛图的顶部。·
l 只有在满足两个条件时,脚本才会显示蜡烛图:·
o 图表使用的是日内时间框架(参见plotcandle()调用中对timeframe.isintraday的检查)。这样做是因为在高于或等于1D的时间框架上显示日线值无效。
o request.security()函数返回非na值(参见函数调用中的 gaps = barmerge.gaps_on)。
l 我们使用一个元组([open, high, low, close])和 request.security(),在一次调用中获取四个值。·
l 使用var仅在首条K线声明UP_COLOR和DN_COLOR颜色常量。使用常量是因为这些颜色在代码中不止一处使用。如果要更改它们,只需在一处进行更改即可。
l 在 bodyColor 变量初始化中,我们为蜡烛体创建了较浅的透明度,这样它们就不会阻碍图表中的蜡烛。·
使用 `plotbar()` 绘制K线
plotbar()的签名是:
plotbar(open, high, low, close, title, color, editable, show_last, display) → void
请注意,plotbar() 没有 bordercolor 或 wickcolor 参数,因为传统K线上没有边框或灯芯。本例使用与上一节第二个示例相同的着色逻辑绘制传统K线:
indicator("Dual-color bars")
paletteColor = close >= open ? color.lime : color.red
plotbar(open, high, low, close, color = paletteColor)
K线状态
简介
barstate 命名空间中的一组内置变量允许脚本检测当前执行脚本的K线的不同属性。
这些状态用于将代码的执行或逻辑限制在特定K线上。
有些内置函数会返回当前K线所属交易时段的信息。它们将在Session states部分进行解释。
K线状态内置变量
请注意,虽然指标和库会在所有价格或成交量实时更新时运行,但未使用calc_on_every_tick的策略不会;它们只会在实时K线关闭时执行。这将影响该类脚本对K线状态的检测。例如,在开市市场上,该代码在实时K线关闭前不会显示背景,因为实时K线关闭时策略才会运行:
//@version=5
strategy("S")
bgcolor(barstate.islast ? color.silver : na)
barstate.isfirst
barstate.isfirst仅在数据集的第一个K线上为真,即bar_index为零时。仅在第一个K线上初始化变量可能很有用,例如
// 声明数组,并仅在第一条K线上设置其值。
FILL_COLOR = color.green
var fillColors = array.new_color(0)
if barstate.isfirst
// 用逐渐变浅的填充颜色初始化数组元素。
array.push(fillColors, color.new(FILL_COLOR, 70))
array.push(fillColors, color.new(FILL_COLOR, 75))
array.push(fillColors, color.new(FILL_COLOR, 80))
array.push(fillColors, color.new(FILL_COLOR, 85))
array.push(fillColors, color.new(FILL_COLOR, 90))
barstate.islast
如果当前K线是图表中的最后一个K线,则 barstate.islast 为 true,无论该K线是否为实时K线。
它可用于将代码执行限制在图表的最后一个K线上,这在绘制线条、标签或表格时非常有用。在这里,我们用它来决定何时更新一个标签,因为我们希望该标签只出现在最后一个K线上。我们只创建一次标签,然后使用 label.set_*()函数更新其属性,因为这样效率更高:
//@version=5
indicator("", "", true)
// 只在第一栏创建标签。
var label hiLabel = label.new(na, na, "")
// 在最后一个K线上更新标签的位置和文本、
// 包括所有实时K线更新。
if barstate.islast
label.set_xy(hiLabel, bar_index, high)
label.set_text(hiLabel, str.tostring(high, format.mintick))
barstate.ishistory
barstate.ishistory在所有历史K线上为真。当barstate.isrealtime也为真时,它永远不会在某个K线上为真,也不会在实时K线的收盘更新(当barstate.isconfirmed变为真时)时变为真。在休市市场上,当barstate.islast也为真时,它可能在同一条K线上为真。
barstate.isrealtime
如果当前数据更新是实时K线更新,则barstate.isrealtime为 true,否则为 false(因此是历史数据)。请注意,barstate.islast 在所有实时K线上也为真。
barstate.isnew
barstate.isnew 在所有历史K线和实时K线首次(开盘)更新时为真。
所有历史K线都被视为新K线,因为 Pine Script® 运行时会按顺序在每个K线上执行脚本,从图表中的第一个K线开始,直到最后一个K线。因此,你的脚本在逐条执行时,会发现每一条历史K线。
当出现新的实时K线时,barstate.isew 可以用来重置 varip 变量。下面的代码会在所有历史K线和每个实时K线开始时将 updateNo 重置为 1。它会计算每个实时K线中的实时更新次数:
//@version=5
indicator("")
updateNo() =>
varip int updateNo = na
if barstate.isnew
updateNo := 1
else
updateNo += 1
plot(updateNo())
barstate.isconfirmed
barstate.isconfirmed 在所有历史K线和实时K线的最后(收盘)更新时为真。
它可以通过要求实时K线在条件为真之前关闭来避免重绘。在这里,我们使用它来保持 RSI 的绘制,直到实时K线关闭并成为已结束的实时K线。它会在历史K线上绘制,因为 barstate.isconfirmed 在历史K线上总是为真:
//@version=5
indicator("")
myRSI = ta.rsi(close, 20)
plot(barstate.isconfirmed ? myRSI : na)
在request.security()调用中使用barstate.isconfirmed时将不起作用。
`barstate.islastconfirmedhistory`
如果在市场休市时,脚本在数据集的最后一个K线上执行,或在市场开市时,在实时K线的前一个K线上执行,则 barstate.islastconfirmedhistory为 true。
它可用于使用barstate.islastconfirmedhistory[1]检测第一个实时K线,或推迟服务器密集计算直到到最后一个历史K线,否则在开市市场上将无法检测。
示例
下面是一个使用 barstate.* 变量的脚本示例:
//@version=5
indicator("Bar States", overlay = true, max_labels_count = 500)
stateText() =>
string txt = ""
txt += barstate.isfirst ? "isfirst\n" : ""
txt += barstate.islast ? "islast\n" : ""
txt += barstate.ishistory ? "ishistory\n" : ""
txt += barstate.isrealtime ? "isrealtime\n" : ""
txt += barstate.isnew ? "isnew\n" : ""
txt += barstate.isconfirmed ? "isconfirmed\n" : ""
txt += barstate.islastconfirmedhistory ? "islastconfirmedhistory\n" : ""
labelColor = switch
barstate.isfirst => color.fuchsia
barstate.islastconfirmedhistory => color.gray
barstate.ishistory => color.silver
barstate.isconfirmed => color.orange
barstate.isnew => color.red
=> color.yellow
label.new(bar_index, na, stateText(),yloc = yloc.abovebar, color = labelColor)
· 每个状态的名称为真时,将显示在标签文本中。
· 标签背景有五种可能的颜色:
o 第一条K线为紫红色
o 最后确认的历史K线为灰色
o 实时K线被确认时为橙色(当K线关闭并成为已结束的实时K线时)
o 实时K线首次执行时为红色
o 实时K线的其他执行时为黄色
我们首先将指标添加到开市市场的图表中,但此时尚未收到任何实时更新。请注意#1中如何识别最后一个确认的历史K线,以及如何识别最后一个K线,但仍被视为历史K线,因为尚未收到任何实时更新。

让我们看看实时K线更新开始后会发生什么:
· 实时K线是红色的,因为这是它的第一次执行,因为 barstate.isnew 为真,而 barstate.ishistory 不再为真,所以我们决定颜色的switch结构使用了 barstate.isnew => color.red 分支。这通常不会持续很长时间,因为在下一次更新时,barstate.isnew 不再为真,因此标签的颜色将变为黄色。
· 过期实时K线的标签为橙色,这些K线在收盘时不是历史K线。因此,swich中的barstate.ishistory => color.silver分支没有执行,但下一个分支barstate.isconfirmed => color.orange执行了。
最后一个示例显示了实时K线的标签在第一次执行后将变成黄色。实时K线上的标签通常就是这样显示的:
· 简介
· 价格和成交量
· 商品信息
· 图表时间框架
· 交易时段信息
脚本简介
脚本可以通过 Pine Script® 的内置变量子集来获取当前运行的图表和商品的相关信息。我们在这里介绍的变量可以让脚本获取以下相关信息:
· 图表的价格和成交量
· 图表商品
· 图表的时间框架
· 商品的交易时段(或时间段)
价格和交易量
OHLCV 值的内置变量有:
l open:K 线的开盘价。
l high:K 线的最高价,或在实时时间内达到的最高价。
l low:K线的最低价,或在实时时间内的最低价。
l close:K 线的收盘价,或实时K线中的当前价格。
l volume(成交量):K 线期间的成交量,或实时K线在经过的时间内的成交量。成交量信息的单位因交易工具而异。股票以股为单位,外汇以手为单位,期货以合约为单位,加密货币以基础货币为单位,等等。
其他数值可通过:
l hl2:K 线的最高值和最低值的平均值。
l hlc3:K 线的最高值、最低值和收盘价的平均值。
l ohlc4:K线的开盘价、最高价、最低值和收盘价平均值。
在历史K线中,上述变量的值在K线中不会变化,因为只有 OHLCV 信息可用。在历史K线上运行时,脚本在K线收盘时执行,此时K线的所有信息都是已知的,脚本在K线上执行期间不会发生变化。
实时K线则完全不同。当指标(或calc_on_every_tick = true的策略)以实时方式运行时,上述变量(除 open 外)的值在实时K线上连续迭代的脚本之间会发生变化,因为它们代表的是实时K线进程中某个时间点的当前值。这可能会导致某种形式的重绘。更多详情,请参阅 Pine Script® 的执行模型页面。
[]历史引用操作符可用于引用内置变量的过去值,例如,close[1]指的是相对于脚本正在执行的特定K线而言,前一个K线的收盘价。
商品信息
syminfo 命名空间中的内置变量可为脚本提供有关脚本所运行图表的商品信息。每次脚本用户更改图表商品时,这些信息都会发生变化。然后,脚本将使用内置变量的新值在图表的所有K线上重新执行:
· syminfo.basecurrency: 基本货币,例如 "BTCUSD "中的 "BTC "或 "EURUSD "中的 "EUR"。
· syminfo.currency:报价货币,例如,"BTCUSD "中的 "USD",或 "USDCAD "中的 "CAD"。
· syminfo.description: 商品的描述。
· syminfo.mintick: 商品的刻度值,或价格可移动的最小增量。不要与点或点数混淆。在 "ES1! (S&P 500 E-Mini")的刻度值是 0.25,因为这是价格移动的最小增量。
· syminfo.pointvalue: 点值是决定合约价值的标的资产的倍数。在 "ES1! (S&P 500 E-Mini")的点值是 50,因此一份合约的价值是该工具价格的 50 倍。
· syminfo.prefix:前缀是交易所或经纪商的标识符:"AAPL"为"NASDAQ"或"BATS","ES1!"为 "CME_MINI_DL"。
· syminfo.root: 这是结构化代码(如期货代码)的前缀。ES1!"的前缀是 "ES","ZW1!"的前缀是 "ZW"。
· syminfo.session:该商品在图表上的交易时段设置。如果"Chart settings/Symbol/Session"字段设置为 "Extended",则只有在商品和用户输入允许扩展交易时段时才会返回"extended"。它很少显示,主要用作ticker.new()中session参数的参数。
· syminfo.ticker: 是商品名称,不含交易所部分(syminfo.prefix): "btcusd"、"aapl"、"es1!"、"usdcad"。
· syminfo.tickerid: 该字符串很少显示。它主要用作request.security() 中symbol参数的参数。它包括交易时段、前缀和股票信息。
· syminfo.timezone:商品交易的时区。该字符串是 IANA 时区数据库名称(如 "America/New_York")。
· syminfo.type: 商品所属的市场类型。包括“stock”, “futures”,“index”,“forex”,“crypto”,“fund”,“dr”, “cfd”,“bond”,“warrant”,“structured”和“right”。
该脚本将在图表中显示这些内置变量的值:
//version=5
indicator("`syminfo.*` built-ins", "", true)
printTable(txtLeft, txtRight) =>
var table t = table.new(position.middle_right, 2, 1)
table.cell(t, 0, 0, txtLeft, bgcolor = color.yellow, text_halign = text.align_right)
table.cell(t, 1, 0, txtRight, bgcolor = color.yellow, text_halign = text.align_left)
nl = "\n"
left =
"syminfo.basecurrency: " + nl +
"syminfo.currency: " + nl +
"syminfo.description: " + nl +
"syminfo.mintick: " + nl +
"syminfo.pointvalue: " + nl +
"syminfo.prefix: " + nl +
"syminfo.root: " + nl +
"syminfo.session: " + nl +
"syminfo.ticker: " + nl +
"syminfo.tickerid: " + nl +
"syminfo.timezone: " + nl +
"syminfo.type: "
right =
syminfo.basecurrency + nl +
syminfo.currency + nl +
syminfo.description + nl +
str.tostring(syminfo.mintick) + nl +
str.tostring(syminfo.pointvalue) + nl +
syminfo.prefix + nl +
syminfo.root + nl +
syminfo.session + nl +
syminfo.ticker + nl +
syminfo.tickerid + nl +
syminfo.timezone + nl +
syminfo.type
printTable(left, right)
图表时间框架
脚本可以使用这些内置函数获取图表所用时间框架类型的信息,这些内置函数都返回一个 simple bool结果:
· timeframe.isseconds
· timeframe.isminutes
· timeframe.isintraday
· timeframe.isdaily
· timeframe.isweekly
· timeframe.ismonthly
· timeframe.isdwm
还有两个内置函数返回更具体的时间框架信息:
· timeframe.multiplier 返回一个“simple int",包含时间框架单位的乘数。一小时的图表时间框架将返回 60,因为盘中时间框架以分钟为单位。30 秒的时间框架将返回 30(秒),日线图将返回 1(天),季度图将返回 3(月),年线图将返回 12(月)。该变量的值不能用作内置函数中timeframe参数的参数,因为这些函数需要一个timeframe规格格式的字符串。·
· timeframe.period 以 Pine Script® 的时间框架规范格式返回字符串。
更多信息,请参阅 "timeframe"页面。
交易时段信息
交易时段信息有不同的形式:
· syminfo.session 内置变量返回的值是 session.regular 或 session.extended。它反映了该商品在图表中的交易时段设置。如果 "Chart settings/Symbol/Session(图表设置/商品/交易时段)"字段设置为 "Extended(扩展)",则只有在商品和用户输入允许扩展交易时段时才会返回 "extended"。它用于预期交易时段类型时,例如作为 ticker.new() 中session参数的参数。
· Session 状态内置项提供有关K线所属交易时段的信息。
简介
脚本的视觉效果对我们用Pine Script®编写的指标的可用性起着至关重要的作用。设计精良的图表和绘图能使指标更易于使用和理解。好的视觉设计能建立视觉层次,使重要信息更突出,次要信息不碍事。
在Pine中使用颜色可以很简单,也可以根据构思的需要而有所变化。Pine Script® 中可使用的 4,294,967,296 种颜色和透明度组合可应用于以下方面:
· 在指标的可视空间中绘线或绘制的任何元素,无论是线条、填充物、文本还是蜡烛。
· 脚本可视化空间的背景,无论脚本是在自己的窗格中运行,还是在图表上以叠加模式运行。
· 图表中出现的K线或蜡烛体的颜色。
脚本只能为其自身视觉空间中的元素着色。唯一的例外是,窗格指标可以为图表K线或蜡烛图着色。Bar.color()
Pine Script®内置了color.green等颜色以及color.rgb() 函数,可以动态生成RGBA颜色空间中的任何颜色。
透明度
Pine Script® 中的每种颜色都由四个数值定义:
l 它的红色、绿色和蓝色分量(0-255),遵循 RGB 颜色模型。
l 其透明度(0-100),在 Pine 外部通常称为 Alpha 通道,由 RGBA 颜色模型定义。尽管透明度以 0-100 范围表示,但在函数中使用时,其值可以是 "float",这样就可以访问 Alpha 通道的 256 个基本值。
一种颜色的透明度决定了它的不透明程度:0表示完全不透明,100则表示颜色不可见(完全透明)。调节透明度对于色彩视觉效果或使用背景时非常重要,可以控制哪些颜色主导其他颜色,以及叠加时它们如何混合在一起。
当你在脚本的视觉空间中放置元素时,它们在Z轴上有相对深度;一些元素会出现在另一些元素之上。z-index 是一个表示元素在z轴上位置的值。z-index 最高的元素位于顶部。
Pine Script® 中绘制的元素分为若干组。在同一组中,脚本逻辑中最后创建的元素将显示在同组其他元素的顶部。一个组中的元素不能被放置在其所属组的z空间区域之外,因此,例如,一个绘线永远不能出现在一个表格的顶部,因为表格的z指数最高。
该列表包含视觉元素组,按z索引递增顺序排列,因此背景色始终位于z空间的底部,表格始终位于所有其他元素顶部:
· 背景颜色
· 填充
· 绘线
· Hlines
· LineFills
· 线条
· 框
· 标签
· 表格
请注意,通过在indicator()或strategy()中使用explicit_plot_zorder = true,可以使用脚本中的顺序控制 plot*()、hline() 和 fill() 视觉效果的相对 z 轴索引。
颜色常量
Pine Script®共有17种内置颜色。本表列出了这些颜色的名称、十六进制等效值以及作为color.rgb()参数的RGB值:
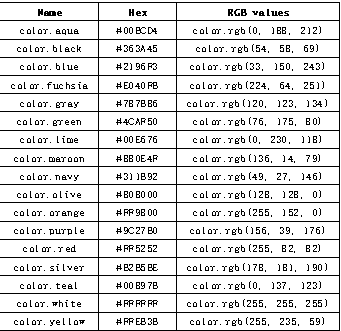
脚本中,所有绘图都使用了相同的color.olive(橄榄色)透明度为40,表达方式不同。所有五种方法在功能上是等同的:
//@version=5
indicator("", "", true)
// ———— 十六进制值中包含透明度 (#99).
plot(ta.sma(close, 10), "10", #80800099)
// ———— 透明度包含在颜色生成函数的参数中.
plot(ta.sma(close, 30), "30", color.new(color.olive, 40))
plot(ta.sma(close, 50), "50", color.rgb(128, 128, 0, 40))
// ———— 使用 `transp` 参数(已过时,建议不要使用)
plot(ta.sma(close, 70), "70", color.olive, transp = 40)
plot(ta.sma(close, 90), "90", #808000, transp = 40)
最后两次调用plot()时使用transp参数指定透明度。在Pine Script® v5中,transp已被弃用,因此应避免使用。使用transp参数定义透明度并不灵活,因为它需要一个输入整数类型的参数,这就意味着必须在脚本执行前知道该参数,因此无法在脚本逐条执行时动态计算。此外,如果您使用的color参数已包含透明度信息,就像在接下来的三次plot()调用中所做的那样,任何用于transp参数的参数都不会有任何影响。其他带有transp参数的函数也是如此。
前面脚本中的颜色不会随着脚本逐条执行而变化。但有时,由于颜色取决于编译时未知的条件,或当脚本在第 0 条开始执行时,颜色需要在脚本执行每条K线时创建。在这种情况下,程序员有两种选择:
1.使用条件语句从预先确定的基本颜色中选择颜色。
2.在脚本逐条执行的过程中,通过计算动态生成新的颜色,例如实现颜色渐变。
比方说,您想根据自己定义的一些条件,为移动平均线着色。为此,您可以使用条件语句,为每种状态选择不同的颜色。首先,当移动平均线上升时,用牛市颜色着色;当移动平均线下降时,用熊市颜色着色:
indicator("Conditional colors", "", true)
int lengthInput = input.int(20, "Length", minval = 2)
color maBullColorInput = input.color(color.green, "Bull")
color maBearColorInput = input.color(color.maroon, "Bear")
float ma = ta.sma(close, lengthInput)
// 定义我们的状态.
bool maRising = ta.rising(ma, 1)
//创建色彩
color c_ma = maRising ? maBullColorInput : maBearColorInput
plot(ma, "MA", c_ma, 2)
l 我们为脚本用户提供牛熊颜色选择。
l 我们定义了一个 maRising 布尔变量,当当前K线的移动平均线高于上一K线时,该变量将为真。
l 我们定义了一个 c_ma 颜色变量,根据 maRising 布尔变量的值,从两种颜色中选择一种。我们使用 ? : 三元运算符来编写条件语句。
还可以使用条件颜色来避免在特定条件下绘制。在这里,我们使用一条线绘制枢轴高点和枢轴低点,但当出现新的枢轴时,我们不想绘制任何线,以避免枢轴转换时出现接头。为此,我们会检测枢轴的变化,并在检测到变化时使用 na 作为颜色值,这样就不会在该K线上绘制任何线:
//@version=5
indicator("Conditional colors", "", true)
int legsInput = input.int(5, "Pivot Legs", minval = 1)
color pHiColorInput = input.color(color.olive, "High pivots")
color pLoColorInput = input.color(color.orange, "Low pivots")
// 初始化枢轴变量。
var float pHi = na
var float pLo = na
// 检测到新的枢轴时,保存其值。
pHi := nz(ta.pivothigh(legsInput, legsInput), pHi)
pLo := nz(ta.pivotlow( legsInput, legsInput), pLo)
//检测到新的枢轴时,不要绘制颜色。
plot(pHi, "High", ta.change(pHi) ? na : pHiColorInput, 2, plot.style_line)
plot(pLo, "Low", ta.change(pLo) ? na : pLoColorInput, 2, plot.style_line)
要理解这段代码的工作原理,首先必须知道 ta.pivothigh() 和 ta.pivotlow(),这两个函数在这里使用时没有source参数参数,当它们找到高/低枢轴时会返回一个值,否则会返回 na。
当我们使用 nz()函数测试 pivot函数返回的值是否为 na 时,只有当返回的值不是 na 时,我们才允许将其赋值给 pHi 或 pLo 变量,否则只是将变量之前的值重新赋值给它,这对其值没有任何影响。请记住,pHi 和 pLo 之前的值是逐条保留的,因为我们在初始化它们时使用了 var 关键字,这导致初始化只发生在第一个K线。
接下来要做的就是在绘制线条时,插入一个三元条件语句,当枢轴值发生变化时,颜色将产生 na;当枢轴水平未发生变化时,颜色将产生脚本输入中所选的颜色。
使用color.new()、color.rgb()和color.from_gradient()等函数,可以在脚本逐条执行的过程中即时创建颜色。
当需要从基色生成不同透明度的颜色时,color.new() 最为有用。
如果需要从红、绿、蓝或透明成分动态生成颜色,color.rgb()就非常有用。color.rgb()可以创建颜色,而它的姊妹函数 color.r()、color.g()、color.b() 和 color.t() 可以用来从颜色中提取红、绿、蓝或透明度值,进而生成变体。
color.from_gradient()用于在两种基色之间创建线性渐变。它根据最小值和最大值评估源值来确定使用哪种中间色。
让我们使用 color.new(color,transp),使用牛/熊两种基色中的一种,为交易量柱子创建不同的透明度:
//@version=5
indicator("Volume")
// 我们给颜色常量命名是为了让它们更容易读取。
var color GOLD_COLOR = #CCCC00ff
var color VIOLET_COLOR = #AA00FFff
color bullColorInput = input.color(GOLD_COLOR, "Bull")
color bearColorInput = input.color(VIOLET_COLOR, "Bear")
int levelsInput = input.int(10, "Gradient levels", minval = 1)
//我们只在第零K线用 `var` 初始化一次,否则计数会在每个K线重置为零。 var float riseFallCnt = 0
// 计算上升/下降,将范围限定为: 1 至 `i_levels`。 riseFallCnt := math.max(1, math.min(levelsInput, riseFallCnt + math.sign(volume - nz(volume[1]))))
// 按 80 的比例重新调整计数,反转计数,并将透明度上限设为 <80,使颜色保持可见。 float transparency = 80 - math.abs(80 * riseFallCnt / levelsInput)
// 构建牛或熊颜色的正确透明度。
color volumeColor = color.new(close > open ? bullColorInput : bearColorInput, transparency)
plot(volume, "Volume", volumeColor, 1, plot.style_columns)
l 在脚本的倒数第二行,我们通过改变所使用的基础颜色(取决于K线是上涨还是下跌)和透明度级别(根据成交量的累计涨跌计算得出)来动态计算柱体颜色。
l 不仅为脚本用户提供了牛市/熊市基础颜色的控制权,还提供了亮度级别数量的控制权。我们使用该值来确定我们将跟踪的最大涨跌次数。为用户提供管理该值的可能性,可以让他们根据所使用的时间框架或市场来调整指标的视觉效果。
l 我们注意控制使用的最大透明度,使其永远不会超过 80。这可以确保我们的颜色始终保持一定的可见度。
l 我们还在输入中将级别数的最小值设置为1。当用户选择"1"时,交易量柱子要么是牛色,要么是最大亮度的熊色,或者透明度为0。
color.rgb()
在下一个示例中,我们使用color.rgb(red, green, blue, transp)从RGBA值生成颜色。我们将结果用于送给朋友的节日礼物,这样他们就可以带着TradingView图表参加聚会了:
//@version=5
indicator("Holiday candles", "", true)
float r = math.random(0, 255)
float g = math.random(0, 255)
float b = math.random(0, 255)
float t = math.random(0, 100)
color holidayColor = color.rgb(r, g, b, t)
plotcandle(open, high, low, close, color = c_holiday, wickcolor = holidayColor, bordercolor = c_holiday)
l 我们生成的红、绿、蓝通道值范围为0至255,透明度值范围为0至100。还要注意的是,由于math.random()返回的是浮点数值,因此浮点 0.0-100.0 的范围可以访问底层阿尔法通道的 0-255 全透明度值。
l 我们使用 math.random(min, max, seed)函数生成伪随机值。我们没有为函数的第三个参数:seed 使用参数。当你想确保函数结果的可重复性时,使用它很方便。使用相同的seed调用该函数,将产生相同的随机值序列。
color.from_gradient()
最后一个颜色计算示例将使用color.from_gradient (value,bottom_value,top_value,bottom_color,top_color)。首先,让我们以最简单的形式使用它,在与内置指标相似的版本中为 CCI 信号着色:

//@version=5
indicator(title="CCI line gradient", precision=2, timeframe="")
var color GOLD_COLOR = #CCCC00
var color VIOLET_COLOR = #AA00FF
var color BEIGE_COLOR = #9C6E1B
float srcInput = input.source(close, title="Source")
int lenInput = input.int(20, "Length", minval = 5)
color bullColorInput = input.color(GOLD_COLOR, "Bull")
color bearColorInput = input.color(BEIGE_COLOR, "Bear")
float signal = ta.cci(srcInput, lenInput)
color signalColor = color.from_gradient(signal, -200, 200, bearColorInput, bullColorInput)
plot(signal, "CCI", signalColor)
bandTopPlotID = hline(100, "Upper Band", color.silver, hline.style_dashed)
bandBotPlotID = hline(-100, "Lower Band", color.silver, hline.style_dashed)
fill(bandTopPlotID, bandBotPlotID, color.new(BEIGE_COLOR, 90), "Background")
请注意:
l 要计算梯度,color.from_gradient()需要最小值和最大值,用于value参数的参数将与这两个值进行比较。我们需要为CCI这样的无边界信号(即没有固定边界,如RSI,总是在0-100之间震荡)计算梯度,但这并不意味着不能使用 color.from_gradient()。在这里,我们通过提供 -200 和 200 作为参数值来解决我们的难题。这两个值并不代表 CCI 的实际最小值和最大值,但它们处于我们不介意颜色不再变化的水平,因为只要系列超出了bottom_value和top_value的限制,用于bottom_color和top_color 的颜色就会适用。
l color.from_gradient() 计算出的颜色递增是线性的。如果系列值介于bottom_value和top_value参数之间,则生成的颜色的 RGBA 分量也将介于 bottom_color 和 top_color 的 RGBA 分量之间。
l Pine Script® 内建了许多常用的指标计算函数。在这里,我们使用 ta.cci() 代替传统的计算方法。
color.from_gradient()中用于value的参数并不一定是我们正在计算的线的值。只要能提供bottom_value和top_value参数,任何我们想要的参数都可以使用。在这里,我们通过使用信号高于/低于中心线后的K线数量为波段着色来增强 CCI 指标:

//@version=5
indicator(title="CCI line gradient", precision=2, timeframe="")
var color GOLD_COLOR = #CCCC00
var color VIOLET_COLOR = #AA00FF
var color GREEN_BG_COLOR = color.new(color.green, 70)
var color RED_BG_COLOR = color.new(color.maroon, 70)
float srcInput = input.source(close, "Source")
int lenInput = input.int(20, "Length", minval =5)
int stepsInput = input.int(50, "Gradient levels", minval = 1)
color bullColorInput = input.color(GOLD_COLOR, "Line: Bull", inline = "11")
color bearColorInput = input.color(VIOLET_COLOR, "Bear", inline = "11")
color bullBgColorInput = input.color(GREEN_BG_COLOR, "Background: Bull", inline = "12")
color bearBgColorInput = input.color(RED_BG_COLOR, "Bear", inline = "12")
// 绘制彩色信号线.
float signal = ta.cci(srcInput, lenInput)
color signalColor = color.from_gradient(signal, -200, 200, color.new(bearColorInput, 0), color.new(bullColorInput, 0))
plot(signal, "CCI", signalColor, 2)
// 检测中心线的交叉点.
bool signalX = ta.cross(signal, 0)
// 计算交叉点后的K线数。以输入的步数为上限.
int gradientStep = math.min(stepsInput, nz(ta.barssince(signalX)))
// 为渐变选择牛/熊末端颜色.
color endColor = signal > 0 ? bullBgColorInput : bearBgColorInput
// 从无颜色到`c_endColor`的渐变色中获取颜色
color bandColor = color.from_gradient(gradientStep, 0, stepsInput, na, endColor)
bandTopPlotID = hline(100, "Upper Band", color.silver, hline.style_dashed)
bandBotPlotID = hline(-100, "Lower Band", color.silver, hline.style_dashed)
fill(bandTopPlotID, bandBotPlotID, bandColor, title = "Band")
请注意:
l 信号线使用的基本颜色和梯度与之前的示例相同。不过,我们将线条的宽度从默认的 1 增加到了 2。它是我们视觉效果中最重要的组成部分;增加它的宽度是为了让它更加突出,并确保用户不会被波段分散注意力,因为波段已经变得比原来的浅米色更加杂乱。
l 填充必须保持不引人注目,原因有二。首先,它对视觉效果来说是次要的,因为它提供了补充信息,即信号处于牛市/熊市区域的持续时间。其次,由于填充图的 Z 指数大于绘线,填充图将覆盖信号线。基于这些原因,我们将填充的底色设为 70,使其相当透明,这样就不会遮挡绘线。用于波段的梯度从完全没有颜色开始(参见 color.from_gradient()调用中作为 bottom_color 参数的 na),然后转为输入的牛/熊基本颜色,条件c_endColor颜色变量包含了这些颜色。
l 我们为用户提供了线和填充带的不同牛/熊颜色选择。
l 在计算gradientStep变量时,我们在ta.barssince()上使用nz(),因为在数据集的早期K线中,当测试的条件尚未发生时,ta.barssince()将返回 na。由于我们使用了nz(),在这种情况下返回的值将被替换为0。
在本示例中,我们将把 CCI 指标引向另一个方向。我们将使用根据 CCI 计算出的唐氏通道(历史高点/低点)来建立动态调整的极值区域缓冲区。我们通过使其高度为 DC 的 1/4 来建立顶部/底部带。我们将使用动态调整回溯来计算 DC。为了调节回看,我们将通过保持短周期 ATR 与长周期 ATR 的比率来计算简单的波动率。当该比率高于最近 100 个值中的 50 个值时,我们认为波动率较高。当波动率较高/较低时,我们会减少/增加回看次数。
我们的目标是为指标用户提供以下信息:
· CCI 线使用牛/熊梯度着色,正如我们在最近的示例中所说明的那样。
· 唐氏通道的顶部和底部色带,其填充方式使其颜色随着历史高点/低点时间的推移而变深。
· 作为一种强化波动水平情况的方法,我们将在背景上涂上一种颜色,当波动率增加时,这种颜色的强度也会增加。
这是我们的指标在使用浅色主题时的样子:
还有深色主题:
//@version=5
indicator("CCI DC", precision = 6)
color GOLD_COLOR = #CCCC00ff
color VIOLET_COLOR = #AA00FFff
int lengthInput = input.int(20, "Length", minval = 5)
color bullColorInput = input.color(GOLD_COLOR, "Bull")
color bearColorInput = input.color(VIOLET_COLOR, "Bear")
// —————函数将 `val` 限定在 `min` 和 `max` 之间。
clamp(val, min, max) =>
math.max(min, math.min(max, val))
// ————— 波动率以 0-100 表示。
float v = ta.atr(lengthInput / 5) / ta.atr(lengthInput * 5)
float vPct = ta.percentrank(v, lengthInput * 5)
// ————— 计算 DC 的动态回溯。它在低/高波动率时增加/减少。
bool highVolatility = vPct > 50
var int lookBackMin = lengthInput * 2
var int lookBackMax = lengthInput * 10
var float lookBack = math.avg(lookBackMin, lookBackMax)
lookBack += highVolatility ? -2 : 2
lookBack := clamp(lookBack, lookBackMin, lookBackMax)
// ————— Donchian通道信号的动态回测长度 。
float signal = ta.cci(close, lengthInput)
// `lookBack` 是一个浮点数,需要将其转换为 int 才能用作长度。
float hiTop = ta.highest(signal, int(lookBack))
float loBot = ta.lowest( signal, int(lookBack))
// 获取DC高度 25% 的余量,以建立高频和低频带。
float margin = (hiTop - loBot) / 4
float hiBot = hiTop - margin
float loTop = loBot + margin
//DC中心线。
float center = math.avg(hiTop, loBot)
// ————— 创建色彩。
color signalColor = color.from_gradient(signal, -200, 200, bearColorInput, bullColorInput)
//波段: 计算透明度时,高/低变化后的时间越长越好、
// 颜色就越深。最高透明度上限为 90。
float hiTransp = clamp(100 - (100 * math.max(1, nz(ta.barssince(ta.change(hiTop)) + 1)) / 255), 60, 90)
float loTransp = clamp(100 - (100 * math.max(1, nz(ta.barssince(ta.change(loBot)) + 1)) / 255), 60, 90)
color hiColor = color.new(bullColorInput, hiTransp)
color loColor = color.new(bearColorInput, loTransp)
// 背景:将`vPct`的0-100范围调整为 0-25,以创建75-100透明度。
color bgColor = color.new(color.gray, 100 - (vPct / 4))
// ————— 绘线
// 用于波段填充的隐形线
hiTopPlotID = plot(hiTop, color = na)
hiBotPlotID = plot(hiBot, color = na)
loTopPlotID = plot(loTop, color = na)
loBotPlotID = plot(loBot, color = na)
//绘制信号和中心线。
p_signal = plot(signal, "CCI", signalColor, 2)
plot(center, "Centerline", color.silver, 1)
// 填充波段区间。
fill(hiTopPlotID, hiBotPlotID, hiColor)
fill(loTopPlotID, loBotPlotID, loColor)
// ————— 背景色
bgcolor(bgColor)
请注意:
l 将背景的透明度控制在 100-75 之间,这样就不会让人感到压抑。我们还使用了中性色,以避免过多分散注意力。背景颜色越深,波动性就越高。
l 我们还将波段填充的透明度值控制在60到90之间。我们使用90,这样当发现新的高点/低点并重置梯度时,起始透明度会使颜色在一定程度上清晰可见。我们不使用低于60的透明度值,因为我们不想让这些波段遮盖信号线。
l 我们使用非常方便的ta.percentrank()函数从衡量波动率的ATR比率中生成一个0-100的值。它可以将未知的刻度值转换为已知值,用于生成透明图。
l 由于我们必须在脚本中三次限定数值,因此我们编写了一个f_clamp()函数,而不是明确地编码三次逻辑。
建议
设计可用的颜色方案
如果您为其他交易者编写脚本,请尽量避免使用在某些环境下效果不佳的颜色,无论是绘线、标签、表格还是填充。至少要测试您的视觉效果,确保它们在浅色和深色 TradingView 主题下的表现令人满意;这两种主题是最常用的。应避免使用黑白等颜色。
建立适当的输入,使脚本用户能够灵活地调整脚本的视觉效果,以适应其特定的环境。
在使用色彩时,要注意建立一个视觉层次,使其与脚本视觉组件的相对重要性相匹配。优秀的设计师懂得如何实现色彩和权重的最佳平衡,从而使人们的视线自然而然地被吸引到设计中最重要的元素上。如果你让所有元素都很突出,那就什么都不突出了。通过淡化周围的视觉效果,为某些元素留出突出的空间。
在输入中提供可选的颜色预设,而不是可以改变的单一颜色,可以帮助有颜色障碍的用户。我们的 "技术评级 "演示了实现这一目标的一种方法。
绘制清晰的线条
最好使用零透明度来绘制视觉效果中的重要线条,以保持清晰。这样,它们就能更精确地通过填充显示出来。请记住,填充的 z-index 要高于绘线,因此要将其置于绘线之上。稍微增加线条的宽度也能使其更加突出。
如果想让一个特殊的绘线脱颖而出,也可以通过为同一行使用多个绘线来提高它的重要性。这些示例中,我们通过调节绘线的连续宽度和透明度来实现这一目的:
![]()
indicator("")
plot(high, "", color.new(color.orange, 80), 8)
plot(high, "", color.new(color.orange, 60), 4)
plot(high, "", color.new(color.orange, 00), 1)
plot(hl2, "", color.new(color.orange, 60), 4)
plot(hl2, "", color.new(color.orange, 00), 1)
plot(low, "", color.new(color.orange, 0), 1)
自定义渐变
在制作渐变时,要根据所应用的视觉效果进行调整。例如,如果使用渐变给蜡烛上色,通常最好将渐变的步数限制在 10 步或更少,因为眼睛很难感知离散物体的强度变化。就像我们在示例中做的那样,为最小和最大透明度设置上限,这样视觉元素就能保持可见,而不会在不必要的时候被淹没。
脚本中使用的颜色类型会影响脚本用户更改脚本视觉效果颜色的方式。只要不使用必须在运行时计算RGBA成分的颜色,脚本用户就可以通过脚本的"Settings/Style"选项卡修改所使用的颜色。本页第一个示例脚本就符合这一标准,下面的截图显示了如何使用脚本的 "Settings/Style"选项卡来更改第一条移动平均线的颜色:
如果您的脚本使用了计算颜色,即只有在运行时才能知道至少一个 RGBA 分量的颜色,那么 "Settings/Style"选项卡将不会为用户提供常用的颜色窗口小部件来修改绘图颜色。未使用计算颜色的同一脚本的绘图也会受到影响。例如,在本脚本中,第一个 plot()调用使用了计算出的颜色,而第二个则没有:
indicator("Calculated colors", "", true)
float ma = ta.sma(close, 20)
float maHeight = ta.percentrank(ma, 100)
float transparency = math.min(80, 100 - maHeight)
// 该线使用的是计算得出的颜色。
plot(ma, "MA1", color.rgb(156, 39, 176, transparency), 2)
// 该线不使用计算出的颜色。
plot(close, "Close", color.blue)
第一条线中使用的颜色是计算出来的颜色,因为只有在运行时才能知道其透明度。它是根据移动平均线与过去100个值的相对位置计算得出的。过去的值低于当前值的百分比越大,maHeight的0-100值就越高。由于我们希望当maHeight值为100时颜色最暗,因此我们要从中减去 100 来获得零透明度。我们还将计算出的透明度值上限设定为80,以便始终保持可见。
由于我们的脚本使用了计算出的颜色,因此"Settings/Style"选项卡不会显示任何颜色部件:
让脚本用户控制所用颜色的解决方案是为他们提供自定义输入,就像我们在这里所做的那样:
indicator("Calculated colors", "", true)
color maInput = input.color(color.purple, "MA")
color closeInput = input.color(color.blue, "Close")
float ma = ta.sma(close, 20)
float maHeight = ta.percentrank(ma, 100)
float transparency = math.min(80, 100 - maHeight)
// 该线使用的是计算得出的颜色。
plot(ma, "MA1", color.new(maInput, transparency), 2)
// 该线不使用计算出的颜色。
plot(close, "Close", closeInput)
请注意,脚本的"Settings"现在显示了一个"input"选项卡,我们在这里创建了两个颜色输入。第一个输入使用color.purple作为默认值。无论脚本用户是否更改该颜色,它都将被用于 color.new()调用,以便在 plot()调用中生成计算出的透明度。第二个输入将我们之前在 plot()调用中使用的内置 color.blue 作为默认值,并在第二个 plot()调用中按原样使用。
填充
简介
有两种不同的机制专门用于填充Pine视觉效果之间的空间:
l 通过 fill()函数,您可以为使用 plot() 绘制的两条线或使用 hline() 绘制的两条水平线之间的背景着色。
l linefill.new()函数用于填充用line.new()创建的线条之间的空间。
fill()函数有两个签名:
fill(plot1, plot2, color, title, editable, show_last,fillgaps)→void
fill(hline1, hline2, color, title, editable, fillgaps) → void
用于 plot1、plot2、hline1 和 hline2 参数的参数必须是 plot() 和 hline()调用返回的 ID。fill()函数是唯一使用这些 ID 的内置函数。
请看第一个示例,调用plot()和hline()函数返回的ID被保存在p1、p2、p3 以及h1、h2、h3 和h4变量中,以便作为fill()参数重复使用:
//@version=5
indicator("Example 1")
p1 = plot(math.sin(high))
p2 = plot(math.cos(low))
p3 = plot(math.sin(close))
fill(p1, p3, color.new(color.red, 90))
fill(p2, p3, color.new(color.blue, 90))
h1 = hline(0)
h2 = hline(1.0)
h3 = hline(0.5)
h4 = hline(1.5)
fill(h1, h2, color.new(color.yellow, 90))
fill(h3, h4, color.new(color.lime, 90))
由于 fill() 需要来自同一函数的两个 ID,因此有时我们需要使用 plot()调用,否则就需要使用 hline()调用,本例就是如此:
//@version=5
indicator("Example 2")
src = close
ma = ta.sma(src, 10)
osc = 100 * (ma - src) / ma
oscPlotID = plot(osc)
// 在这里,没有用hline()函数 ,而是用了两个 "plot() "函数.
zeroPlotID = plot(0, "Zero", color.silver, 1, plot.style_circles)
fill(oscPlotID, zeroPlotID, color.new(color.blue, 90))
由于 "series color"可以作为 fill() 中color参数的参数,因此可以使用 color.red 或 #FF001A 等常量,也可以使用在每个K线上计算颜色的表达式,如本例所示:
//@version=5
indicator("Example 3", "", true)
line1 = ta.sma(close, 5)
line2 = ta.sma(close, 20)
p1PlotID = plot(line1)
p2PlotID = plot(line2)
fill(p1PlotID, p2PlotID, line1 > line2 ? color.new(color.green, 90) : color.new(color.red, 90))
线条填充对象可以填充用line.new()函数创建的两条线条之间的空间。调用 linefill.new()函数时,图表上会显示一个线条填充对象。该函数的签名如下:
linefill.new(line1, line2, color) → series linefill
line1和line2参数是要填充的两行之间的线条ID。color参数是填充的颜色。任何一对双线之间只能有一个linefill,因此在同一对双线上连续调用linefill.new()将用一个新的linefill替换之前的linefill。函数会返回其创建的linefill对象的ID,该ID可以保存在一个变量中,以便在调用linefill.set_color()时使用,从而改变现有linefill的颜色。
Linefill的行为取决于它们所连接的线。linefill不能直接移动,它们的坐标与所连接线的坐标一致。如果两条线都向同一方向延伸,那么linefill也会随之延伸。
需要注意的是,要使线条扩展正常工作,line.new()线条的x1坐标必须小于其x2坐标。如果线条的x1参数大于 x2 参数,即使使用了extend.left参数,线条实际上仍会向右延伸,因为x2被假定为最右边的x坐标。
在下面的示例中,我们的指标绘制了两条连接图表最后两个高点和低点枢轴的线条。我们将线条向右延伸,以投射图表的短期走势,并linefill条之间的空间,以增强线条所创建通道的可见度:
//@version=5
indicator("Channel", overlay = true)
LEN_LEFT = 15
LEN_RIGHT = 5
pH = ta.pivothigh(LEN_LEFT, LEN_RIGHT)
pL = ta.pivotlow(LEN_LEFT, LEN_RIGHT)
// 枢轴点的K线索引。Ta.valuewhen()中PH强制转为bool
pH_x1 = ta.valuewhen(pH, bar_index, 1) - LEN_RIGHT
pH_x2 = ta.valuewhen(pH, bar_index, 0) - LEN_RIGHT
pL_x1 = ta.valuewhen(pL, bar_index, 1) - LEN_RIGHT
pL_x2 = ta.valuewhen(pL, bar_index, 0) - LEN_RIGHT
// 枢轴点的价格值。PH转为bool,有值时ture,0值时false
pH_y1 = ta.valuewhen(pH, pH, 1)
pH_y2 = ta.valuewhen(pH, pH, 0)
pL_y1 = ta.valuewhen(pL, pL, 1)
pL_y2 = ta.valuewhen(pL, pL, 0)
if barstate.islastconfirmedhistory
// Lines
lH = line.new(pH_x1, pH_y1, pH_x2, pH_y2, extend = extend.right)
lL = line.new(pL_x1, pL_y1, pL_x2, pL_y2, extend = extend.right)
// Fill
fillColor = switch
pH_y2 > pH_y1 and pL_y2 > pL_y1 =>color.green
pH_y2 < pH_y1 and pL_y2 < pL_y1 => color.red
=> color.silver
linefill.new(lH, lL, color.new(fillColor, 90))
输入
简介
输入允许脚本接收用户可以更改的值。对关键值使用输入将使脚本更能适应用户的偏好。
下面的脚本使用ta.sma(close,20)绘制20K期简单移动平均线(SMA)。虽然编写简单,但灵活性不高,只会绘制特定的MA:
//@version=5
indicator("MA", "", true)
plot(ta.sma(close, 20))
如果我们下面以这种方式编写脚本,它将变得更加灵活,因为它的用户将能够选择用于MA计算的源值和长度:
//@version=5
indicator("MA", "", true)
sourceInput = input(close, "Source")
lengthInput = input(20, "Length")
plot(ta.sma(sourceInput, lengthInput))
只有在图表上运行脚本时才能访问输入。脚本用户可以通过脚本的"Settings"对话框访问这些输入:
l 双击图表上的指标名称
l 右键单击脚本名称,然后从下拉菜单中选择"Settings"项
l 在图表上将鼠标悬停在指标名称上时出现的 "更多 "菜单图标(三个点)中选择"Settings"项
l 双击数据窗口(图表右下方第四个图标)中的指标名称
"Settings"对话框始终包含 "Style"和 "Visibility"选项卡,用户可以通过这两个选项卡指定自己对脚本视觉效果和图表时间间隔的偏好。
当脚本包含对input.*()函数的调用时,"Setting"对话框中将出现"input"选项卡。
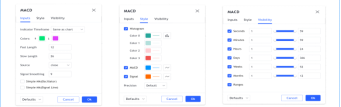
在脚本的执行流程中,当脚本已在图表上,而用户更改了"input"选项卡中的值时,就会处理输入。这些更改会触发在所有K线图上重新执行脚本,因此当用户更改输入值时,脚本会使用新值重新计算。
可使用以下输入函数
· input()
在 "输入"选项卡中创建了一个特定的输入部件,以接受每种类型的输入。除非input.*()调用中另有说明,否则每个输入都会按照input.*()调用在脚本中出现的顺序出现在 "input "选项卡的新行中。
我们的样式指南建议将input.*()调用放在脚本的开头。
输入函数定义包含许多参数,通过这些参数,可以控制输入的默认值、限制以及在"输入"选项卡中的组织结构。
input*.()调用只是 Pine Script® 中的另一个函数调用,其结果可以与算术、比较、逻辑或三元运算符相结合,形成一个要赋值给变量的表达式。在这里,我们将调用 input.string() 的结果与字符串 "On "进行比较。然后将表达式的结果存储到 plotDisplayInput 变量中。由于该变量存储的是 true 或 false 值,因此属于 "input bool "类型:
//@version=5
indicator("Input in an expression`", "", true)
bool plotDisplayInput = input.string("On", "Plot Display", options = ["On", "Off"]) == "On"
plot(plotDisplayInput ? close : na)
除“source”值外,input.*()函数返回的所有值均为"input"形式(更多信息请参阅 "forms"部分)。
输入函数参数
所有输入函数共有的参数是:defval、title、tooltip、inline和group。其他输入函数也会使用一些参数:options、minval、maxval、step和 confirm。
所有这些参数都是"const "形式的参数(用于"source "的输入除外,它返回的是"series float "结果)。这意味着它们必须在编译时已知,并且在脚本执行过程中不能更改。由于input.*()函数的结果始终是"input"或"series"形式,因此一次 input.*()函数调用的结果不能用作后续input.*()函数调用的参数,"input"形式比"const "形式更强。
让我们来看看每个参数:
· defval 是所有输入函数的第一个参数。它是将出现在"input"窗口小组件中的默认值。它需要一个input类型的参数。
· title需要一个 "const string "参数。它是字段的标签。
· tooltip (tooltip),需要一个"const string"参数。使用该参数时,字段右侧会出现一个问号图标。当用户将鼠标悬停在该图标上时,将显示tooltip的文本。请注意,如果使用 inline 将多个输入字段组合在一行中,tooltip将始终显示在最右边字段的右侧,并显示该行中使用的最后一个参数的tooltip文本。参数字符串中支持换行 (\n)。
· inline 需要一个 "const string "参数。在多个 input.*() 调用中使用相同的参数,将在同一行中组合输入部件。"input"选项卡的展开宽度是有限制的,因此一行中能容纳的输入字段数量有限。使用带有同样inline参数的input.*() 调用,会使输入字段靠向左边,紧跟在标签之后,不同于在未使用inline参数时所有输入字段的默认左对齐方式。
· group 需要一个 "const string "参数。它用于将任意数量的输入分组到同一部分。用作 group 参数的字符串将成为该部分的标题。所有要分组的 input.*() 调用的group参数必须使用相同的字符串。
· options 要求使用方括号括起来的逗号分隔元素列表(如["ON"、"OFF"])。它用于创建一个下拉菜单,以菜单选项的形式提供列表中的元素。只能选择一个菜单项。使用选项列表时,defval 值必须是列表元素之一。在允许使用 minval、maxval 或 step 的输入函数中使用 options 时,不能同时使用这些参数。
· minval 需要一个 "const int/float "参数,具体取决于 defval 值的类型。它是输入字段的最小有效值。
· maxval 需要一个 "const int/float "参数,具体取决于 defval 值的类型。它是输入字段的最大有效值。
· step 是使用小部件的向上/向下箭头时字段值变动的增量。
· confirm 需要一个"const bool"(true或false)参数。使用confirm = true的input.*()调用将导致在将脚本添加到图表时弹出"设置/"input""选项卡。confirm对于确保用户配置特定字段非常有用。
minval、maxval 和 step 参数只出现在 input.int() 和 input.float()函数的签名中。
接下来的章节将解释每个输入函数的功能。接下来,我们将探讨使用输入函数和组织显示的不同方式。
l 简单输入
input() 是一个简单的通用函数,支持基本的 Pine Script® 类型: "int"、"float"、"bool"、"color "和 "string"。它还支持“source”输入,即与价格相关的值,如 close、hl2、hlc3 和 hlcc4,或用于接收其他脚本的输出值。
它的签名是:
input(defval, title, tooltip, inline, group) → input int/float/bool/color/string | series float
该函数通过分析函数调用中使用的defval参数的类型,自动检测输入类型。本脚本显示了所有支持的类型,以及函数在使用不同类型的defval参数时返回的表单类型:
//@version=5
indicator("`input()`", "", true)
a = input(1, "input int")
b = input(1.0, "input float")
c = input(true, "input bool")
d = input(color.orange, "input color")
e = input("1", "input string")
f = input(close, "series float")
plot(na)
l 整数输入
input.int()函数有两个签名;一个在不使用options时签名,另一个在使用options时签名:
input.int(defval, title, minval, maxval, step, tooltip, inline, group, confirm) → input int
input.int(defval, title, options, tooltip, inline, group, confirm) → input int
该调用使用options参数为 MA 预设长度列表:
//@version=5
indicator("MA", "", true)
maLengthInput = input.int(10, options = [3, 5, 7, 10, 14, 20, 50, 100, 200])
ma = ta.sma(close, maLengthInput)
plot(ma)
这个参数使用 minval 参数来限制长度:
//@version=5
indicator("MA", "", true)
maLengthInput = input.int(10, minval = 2)
ma = ta.sma(close, maLengthInput)
plot(ma)
带有option列表的版本使用下拉菜单作为窗口部件。不使用option参数时,则使用一个简单的输入框来输入值。
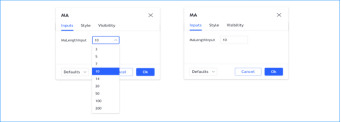
l 浮点输入
输入.float()函数有两个签名;一个是不使用选项时的签名,另一个是使用选项时的签名:
input.int(defval, title, minval, maxval, step, tooltip, inline, group, confirm) → input int
input.int(defval, title, options, tooltip, inline, group, confirm) → input int
在此,我们使用 "浮动 "输入用于倍增标准偏差的因子,以计算布林带:
indicator("MA", "", true)
maLengthInput = input.int(10, minval = 1)
bbFactorInput = input.float(1.5, minval = 0, step = 0.5)
ma = ta.sma(close, maLengthInput)
bbWidth = ta.stdev(ma, maLengthInput) * bbFactorInput
bbHi = ma + bbWidth
bbLo = ma - bbWidth
plot(ma)
plot(bbHi, "BB Hi", color.gray)
plot(bbLo, "BB Lo", color.gray)
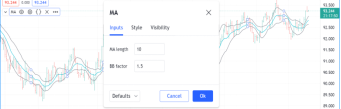
浮点数输入部件与整数输入部件类似。
l 布尔输入
让我们继续进一步开发我们的脚本,这次要添加一个布尔输入法,允许用户切换BB布林带的显示:
indicator("MA", "", true)
maLengthInput = input.int(10, "MA length", minval = 1)
bbFactorInput = input.float(1.5, "BB factor", inline = "01", minval = 0, step = 0.5)
showBBInput = input.bool(true, "Show BB", inline = "01")
ma = ta.sma(close, maLengthInput)
bbWidth = ta.stdev(ma, maLengthInput) * bbFactorInput
bbHi = ma + bbWidth
bbLo = ma - bbWidth
plot(ma, "MA", color.aqua)
plot(showBBInput ? bbHi : na, "BB Hi", color.gray)
plot(showBBInput ? bbLo : na, "BB Lo", color.gray)
请注意:
l 我们使用 input.bool() 添加了一个输入,用于设置 showBBInput 的值。
l 我们在该输入和 bbFactorInput 输入中使用了inline参数,以便将它们放在同一行。在这两种情况下,我们都使用 "01 "作为参数。这就是 Pine Script® 编译器识别它们属于同一行的方法。作为参数的字符串并不重要,也不会出现在"input"选项卡的任何地方;它只是用来识别哪些输入属于同一行。
l 对input.*()调用的title参数进行垂直对齐,以便阅读。
l 我们在两个 plot() 调用中使用 showBBInput 变量进行有条件绘图。当用户取消选中 showBBInput 输入的复选框时,变量值将变为 false。此时,我们的 plot() 调用将绘制 na 值,即不显示任何内容。我们使用 true 作为输入的默认值,因此默认情况下会绘制布林带BB。
l 由于我们为bbFactorInput变量使用了inline参数,因此其在"input"选项卡中的输入栏不会与不使用inline参数的maLengthInput的输入栏垂直对齐。
l 颜色输入
正如"颜色"页面的"通过脚本设置选择颜色"部分所述,"Settings/Style"选项卡中通常显示的颜色选择并非总是可用。在这种情况下,脚本用户将无法更改脚本使用的颜色。如果希望脚本的颜色可以通过"Settings"进行修改,就必须提供颜色输入。您可以让脚本用户通过调用input.color()来更改颜色,而不是使用"Settings/Style"选项卡来更改颜色。
假设我们想在最高值和最低值比BB值的高值高或比其低值低时,用更浅的颜色绘制BB值。您可以使用这样的代码来创建颜色:
bbHiColor = color.new(color.gray, high > bbHi ? 60 : 0)
bbLoColor = color.new(color.gray, low < bbLo ? 60 : 0)
在使用动态(或"series")颜色组件(如此处的透明度)时,"Settings/Style"中的颜色部件将不再出现。让我们创建自己的部件,它将出现在"input"选项卡中:
indicator("MA", "", true)
maLengthInput = input.int(10, "MA length", inline = "01", minval = 1)
maColorInput = input.color(color.aqua, "", inline = "01")
bbFactorInput = input.float(1.5, "BB factor", inline = "02", minval = 0, step = 0.5)
bbColorInput = input.color(color.gray, "", inline = "02")
showBBInput = input.bool(true, "Show BB", inline = "02")
ma = ta.sma(close, maLengthInput)
bbWidth = ta.stdev(ma, maLengthInput) * bbFactorInput
bbHi = ma + bbWidth
bbLo = ma - bbWidth
bbHiColor = color.new(bbColorInput, high > bbHi ? 60:0)
bbLoColor = color.new(bbColorInput, low < bbLo ? 60:0)
plot(ma, "MA", maColorInput)
plot(showBBInput ? bbHi : na, "BB Hi", bbHiColor, 2)
plot(showBBInput ? bbLo : na, "BB Lo", bbLoColor, 2)
l 我们向 input.color()添加了两次调用,以收集maColorInput和bbColorInput变量的值。我们在plot(ma,"MA",maColorInput)调用中直接使用maColorInput,并使用bbColorInput建立bbHiColor和bbLoColor变量,这两个变量使用价格相对于BB的位置来调节透明度。我们在调用color.new()时使用了一个条件值,以生成相同基色的不同透明度。
l 我们没有为新颜色输入使用title参数,因为它们与其他输入在同一行,用户可以了解它们适用于哪些图表。
l 我们重新组织了inline参数,使它们能够反映出我们将输入分组在两条不同行上的事实。
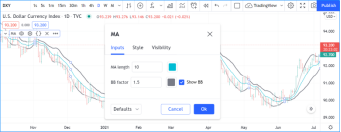
l 时间框架输入
当您希望更改用于计算脚本中数值的时间框架时,时间框架输入非常有用。
让我们抛开前面章节中的 BB,在一个简单的 MA 脚本中添加一个时间框架输入:
//@version=5
indicator("MA", "", true)
tfInput = input.timeframe("D", "Timeframe")
ma = ta.sma(close, 20)
securityNoRepaint(sym, tf, src) =>
request.security(sym, tf, src[barstate.isrealtime ? 1 : 0])[barstate.isrealtime ? 0 : 1]
maHTF = securityNoRepaint(syminfo.tickerid, tfInput, ma)
plot(maHTF, "MA", color.aqua)
l 我们使用 input.timeframe()函数接收时间框架输入。
l 该函数会创建一个下拉部件,其中会提出一些标准时间框架。时间框架列表还包括您在图表用户界面中偏好的任何时间框架。
l 我们在 request.security() 调用中使用了 tfInput。我们还在调用中使用了 gaps = barmerge.gaps_on,因此函数只有在较高时间框架完成后才会返回数据。
商品输入
input.symbol()函数创建了一个窗口小部件,允许用户像在图表用户界面上一样搜索和选择商品。
让我们在脚本中添加一个商品输入:
//@version=5
indicator("MA", "", true)
tfInput = input.timeframe("D", "Timeframe")
symbolInput = input.symbol("", "Symbol")
ma = ta.sma(close, 20)
securityNoRepaint(sym, tf, src) =>
request.security(sym, tf, src[barstate.isrealtime ? 1 : 0])[barstate.isrealtime ? 0 : 1]
maHTF = securityNoRepaint(symbolInput, tfInput, ma)
plot(maHTF, "MA", color.aqua)
请注意:
l 我们使用的defval参数是空字符串。这将导致request.security()(我们使用包含该输入的symbolInput变量)默认使用商品。如果用户选择了其他商品,并希望使用商品返回默认值,则需要使用"input"选项卡"Default"菜单中的"Reset Settings"选项。
l 使用securityNoRepaint()用户定义函数来使用request.security(),这样它就不会重新绘制;它只会在较高时间框架结束时返回值。
l 交易时段输入
交易时段输入可用于收集一个时间段的起止值。input.session()内置函数创建了一个输入框,允许用户指定交易时段的开始和结束时间。用户可以使用下拉菜单进行选择,也可以输入"hh:mm "格式的时间值。
input.session()返回的值是交易时段格式的有效字符串。更多信息请参阅手册中的交易时段页面。
交易时段信息还可以包含交易时段有效天数的信息。我们在此使用 input.string()函数调用来输入日期信息:
indicator("Session input", "", true)
string sessionInput = input.session("0600-1700","Session")
string daysInput = input.string("1234567", tooltip = "1 = Sunday, 7 = Saturday")
sessionString = sessionInput + ":" + daysInput
inSession = not na(time(timeframe.period, sessionString))
bgcolor(inSession ? color.silver : na)
请注意:
l 本脚本建议默认交易时段为 "0600-1700"。
l "input.string() "调用使用tooltip,帮助用户了解输入日期信息的格式。
l 将脚本接收到的两个字符串作为输入串联起来,就建立了一个完整的交易时段字符串。
l 我们使用字符串关键字明确声明了两个输入的类型,以明确这些变量将包含一个字符串。
l 我们使用交易时段字符串调用time()来检测图表K线是否处于用户定义的交易时段中。如果当前K线的时间值(K线打开时的时间)不在交易时段中,time()将返回na,因此只要time()返回的值不是na,inSession就会为true。
l 源值输入
源值输入用于提供两种源值的选择:
l 价格值,即:开盘价、最高价、最低价、收盘价、hl2、hlc3和ohlc4。
l 其他脚本在图表上绘制的数值。通过将一个脚本的输出作为另一个脚本的输入,可将两个或多个脚本"关联"在一起。
该脚本只绘制用户选择的源值。我们将high作为默认值:
//@version=5
indicator("Source input", "", true)
srcInput = input.source(high, "Source")
plot(srcInput, "Src", color.new(color.purple, 70), 6)
这是一张图表,除了脚本之外,我们还加载了一个 "Arnaud Legoux 移动平均线 "指标。请看我们如何使用脚本的源值输入框选择 ALMA 脚本的输出作为我们脚本的输入。由于我们的脚本以浅紫色粗线绘制了源值,因此您可以看到两个脚本的绘图重叠,因为它们绘制的是相同的值:
l 时间输入
时间输入使用 input.time()函数。该函数以毫秒为单位返回Unix时间(更多信息请参阅时间页面)。这类数据还包含日期信息,因此input.time()函数会返回时间和日期。这也是为什么它的组件可以同时选择时间和日期的原因。
在这里,我们将根据输入值测试K线的时间,当时间大于输入值时,我们将绘制一个箭头:
//@version=5
indicator("Time input", "T", true)
timeAndDateInput = input.time(timestamp("1 Aug 2021 00:00 +0300"), "Date and time")
barIsLater = time > timeAndDateInput
plotchar(barIsLater, "barIsLater", "→", location.top, size = size.tiny)
注意,我们使用的defval值是对timestamp()函数的调用。
使用indicator()函数的某些参数时,会在"input"选项卡中填入一个字段。这些参数是timeframe 和 timeframe_gaps。举例:
indicator("MA", "", true, timeframe = "D", timeframe_gaps = false)
plot(ta.vwma(close, 10))
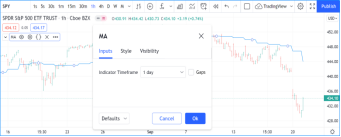
脚本输入的设计对脚本的可用性有重要影响。设计良好的输入更直观易用,用户体验更好:·
l 选择简洁明了的标签(输入的title参数)。
l 谨慎选择默认值。
l 提供最小值和最大值,以防止代码产生意外结果,例如,根据您使用的 MA 类型,将长度的最小值限制为 1 或 2。
l 提供一个与获取值一致的step值。例如,在 0-200 的范围内,5 的步长可能更有用;在 0.0-1.0 的范围内,0.05 的步长可能更有用。
l 使用inline方式将相关的输入值组合在同一行上;例如牛和熊的颜色,或者一条线的宽度和颜色。
l 当输入内容较多时,使用group将其分成好理解的不同部分。将最重要的部分放在顶部。
l 对同一部分内的单个输入进行同样的处理。
在代码中对多个 input.*() 调用的不同参数进行垂直对齐可能会有好处。当您需要进行全局更改时,这将允许您使用编辑器的多光标功能一次性对所有行进行操作。
因为有时有必要使用 Unicode 空格来实现输入的最佳对齐方式。下面就是一个例子:
//@version=5
indicator("Aligned inputs", "", true)
var GRP1 = "Not aligned"
ma1SourceInput = input(close, "MA source", inline = "11", group = GRP1)
ma1LengthInput = input(close, "Length", inline = "11", group = GRP1)
long1SourceInput = input(close, "Signal source", inline = "12", group = GRP1)
long1LengthInput = input(close, "Length", inline = "12", group = GRP1)
var GRP2 = "Aligned"
// MA source后面的三个空格是 Unicode EN 空格(U+2002)。
ma2SourceInput = input(close, "MA source ", inline = "21", group = GRP2)
ma2LengthInput = input(close, "Length", inline = "21", group = GRP2)
long2SourceInput = input(close, "Signal source", inline = "22", group = GRP2)
long2LengthInput = input(close, "Length", inline = "22", group = GRP2)
plot(ta.vwma(close, 10))
请注意:·
l 使用group参数来区分两部分输入。我们使用一个常量来保存组(即group)的名称。这样,如果我们决定更改组的名称,只需在一处进行更改即可。
l 第一部分的输入部件不是垂直对齐的。我们使用的是inline方式,即输入部件紧靠标签右侧。由于 ma1SourceInput 和 long1SourceInput 输入的标签长度不同,因此标签处于不同的 y 位置。
l 为了弥补错位,我们在ma2SourceInput行的title参数中填充了三个Unicode EN空格(U+2002)。之所以需要Unicode空格,是因为普通空格会从标签中删除。通过组合不同数量和类型的Unicode空格,可以实现精确对齐。有关不同宽度的Unicode空格列表,参见此处。
水平线是使用 hline()函数绘制的线条。它旨在使用单一颜色绘制水平线,即在不同的K线上不会改变。当 hline() 无法满足您的需求时,请参阅 plot() 页面的水平线部分,了解绘制水平线的其他方法。
该函数的签名如下:
hline(price, title, color, linestyle, linewidth, editable) → hline
hline() 与 plot() 相比有一些限制:
l 该函数的目标是绘制水平线,因此其price参数需要一个input int/float参数,这意味着不能使用收盘价或动态计算值等series float值。
l 它的color参数需要一个input int参数,这就排除了使用动态颜色(即在每个K线上计算的颜色)或series color的可能性。
l 通过linestyle参数支持三种不同的线型:hline.style_solid、hline.style_dotted和hline.style_dashed。
让我们看看hline()在True Strength Index指标中的应用:
//@version=5
myTSI = 100 * ta.tsi(close, 25, 13)
hline( 50, "+50", color.lime)
hline( 25, "+25", color.green)
hline( 0, "Zero", color.gray, linestyle = hline.style_dotted)
hline(-25, "-25", color.maroon)
hline(-50, "-50", color.red)
plot(myTSI)
请注意:
l 我们显示 5 条水平线,每条线颜色不同。
l 我们为0中心线使用了不同的线条样式。
l 我们选择的颜色在浅色和深色主题下均可使用。
l 指标值的惯常范围是 +100 至 -100。由于 ta.tsi() 内置返回值的范围是 +1 至 -1,因此我们在代码中进行了调整,tsi*100。
可以使用fill()为使用hline()绘制的两个图层之间的空间着色。请记住,两条线必须都是用hline()绘制的。
让我们在TSI指标中添加一些背景颜色:
//@version=5
indicator("TSI")
myTSI = 100 * ta.tsi(close, 25, 13)
plus50Hline = hline( 50, "+50", color.lime)
plus25Hline = hline( 25, "+25", color.green)
zeroHline = hline( 0, "Zero", color.gray,
linestyle = hline.style_dotted)
minus25Hline = hline(-25, "-25", color.maroon)
minus50Hline = hline(-50, "-50", color.red)
// —————函数返回用作背景的浅色阴影。
fillColor(color col) =>
color.new(col, 90)
fill(plus50Hline, plus25Hline, fillColor(color.lime))
fill(plus25Hline, zeroHline, fillColor(color.teal))
fill(zeroHline, minus25Hline, fillColor(color.maroon))
fill(minus25Hline, minus50Hline, fillColor(color.red))
plot(myTSI)
请注意:
l 我们现在使用了 hline()函数调用的返回值,它属于 hline 特殊类型。我们使用 plus50Hline、plus25Hline、zeroHline、minus25Hline 和 minus50Hline 变量来存储这些 "hline "ID,因为在稍后的 fill() 调用中会用到它们。
l 为了为背景色生成较浅的色调,我们声明了一个fillColor()函数,该函数接受一种颜色并返回其90透明度。我们在fill()调用中使用该函数作为color参数。
l 我们在四对不同的水平线之间,分别为所需的四种不同填充调用 fill()。
l 我们在第二个填充中使用颜色:color.teal,因为它产生的绿色比color.green更适合25 TSI线的配色方案。
Pine Script®库是包含函数的出版物,这些函数可在指标、策略或其他库中重复使用。Pine脚本库用于定义常用函数,因此无需在每个脚本中都包含这些函数的源代码。
在其他脚本中使用库之前,必须先发布(私人发布或公开发布)。所有库都是开源发布的。公共脚本只能使用公共库,而且必须是开源的。私人脚本或保存在 Pine Script® 编辑器中的个人脚本可以使用公共或私人库。一个库可以使用其他库,甚至是其自身的先前版本。
库程序员应该熟悉Pine Script®的输入术语、作用域和用户自定义函数。如果你需要温习形式和类型,请参阅《用户手册》中关于类型系统的页面。有关用户自定义函数和作用域的更多信息,参阅用户自定义函数页面。
您可以浏览TradingView社区脚本中成员公开发布的库脚本。
库是一种特殊的脚本,以library()声明语句开头,而不是以indicator()或strategy()开头。库包含可导出的函数定义,当库被其他脚本使用时,函数定义是库中唯一可见的部分。库也可以在全局范围内使用其他Pine Script®代码,就像普通指标一样。这些代码通常用于演示如何使用库函数。
库脚本具有以下结构,其中必须定义一个或多个可导出函数:
//@version=5
// @description <library_description>
library(title, overlay)
<script_code>
// @function <function_description>
// @param <parameter> <parameter_description>
// @returns <return_value_description>
export <function_name>([simple/series] <parameter_type> <parameter_name> [= <default_value>] [, ...]) =>
<function_code>
<script_code>
请注意:
l // @description, // @function, // @param 和// @returns 编译器注释是可选的,但我们强烈建议您使用它们。它们有双重作用:记录库的代码并填充默认的库描述,以便作者在发布库时使用。
l 导出关键字是强制性的。
l <parameter_type> 是强制性的,这与指标或策略中用户定义的函数参数定义相反,后者是无类型的。
l <script_code> 可以是通常在指标中使用的任何代码,包括输入或绘图。
下面是一个示例库:
//@version=5
// @description 提供计算series变量的最高/最低值的函数。
library("AllTimeHighLow", true)
// @function 计算series的最高点。
// @param val使用var series(如果没有参数,默认`high`)。
// 返回series的最高值。
export hi(float val = high) =>
var float ath = val
ath := math.max(ath, val)
// @function 计算series最低点。
// @param val 使用var series(如果没有参数,默认`low`)。
// @returns 该series最低点。
export lo(float val = low) =>
var float atl = val
atl := math.min(atl, val)
plot(hi())
plot(lo())
l 库函数
函数库中的函数定义与指标和策略中的用户自定义函数定义略有不同。库函数正文中的内容有一定限制。
库函数签名(第一行)中,必须使用export关键字:
l export关键字是强制性的。
l 必须明确描述每个参数的参数类型。
l simple或series形式修饰符可以限制允许的参数形式(下一节将解释其用法)。
以下是对库函数的限制:
l 它们不能使用库全局范围内的变量,除非这些变量是 "const"形式的。这意味着不能使用从脚本输入中初始化的全局变量或全局声明的数组。
l 不允许调用request.*()。
l 不允许调用input.*()。
l 不允许调用plot*()、fill() 和 bgcolor()。
库函数总是返回"simple"或"series"形式的结果。您不能使用库函数计算需要"const"或"input"形式的值,某些内置函数就是这种情况。例如,库函数不能用于计算plot()调用中show_last的参数,因为show_last需要一个input int参数。
l 参数形式控制
在调用库函数时,会根据函数内部使用的参数自动检测所提供参数的形式。如果参数可以使用series,就以series形式使用。如果不能则尝试使用simple形式。这就解释了为什么这段代码:
export myEma(int x) =>
ta.ema(close, x)
在使用myCustomLibrary.myEma(20)时是可行的,即使ta.ema()的长度参数需要一个"simple int"参数。当Pine Script®编译器检测到ta.ema()不能使用"series"长度时,会尝试使用simple形式,这种情况下,simple形式是允许的。
虽然库函数不能返回"const"或"input"形式的结果,但可以编写它们来产生"simple"形式的结果。这使得它们比返回"series"形式结果的函数在更多情况下有用,因为某些内置函数不允许使用"series"参数。例如,request.security()的symbol需要一个"simple string"参数。如果我们编写一个库函数,以下面的方式将参数组装为symbol,函数的结果将无法返回,因为它是"series"形式的:
export makeTickerid(string prefix, string ticker) =>
prefix + ":" + ticker
不过,通过将参数的形式限制为simple,我们可以强制函数产生一个simple的结果。为此,我们可以在参数类型前加上 simple关键字:
export makeTickerid(simple string prefix, simple string ticker) =>
prefix + ":" + ticker
请注意,要使函数返回simple结果,其计算中不能使用series值;否则结果将是series形式。
我们也可以使用series关键字为库函数参数的类型添加前缀。不过,由于参数默认被转换为series形式,因此使用series修饰符是多余的;它的存在更多是为了完备性。
l 用户自定义类型和对象
您可以从库中导出用户定义类型(UDT),库函数也可以返回对象。要导出UDT,请在定义前加上export关键字,就像导出函数一样:
//@version=5
library("Point")
export type point
int x
float y
bool isHi
bool wasBreached = false
导入该库并从point UDT创建一个对象的脚本看起来有点像这样:
//@version=5
indicator("")
import userName/Point/1 as pt
newPoint = pt.point.new()
请注意:
l 此代码无法编译,因为没有发布 "Point "库,而且脚本不显示任何内容。
l userName要替换为库发布者的TradingView用户名。
l 我们用内置的new()方法从pointUDT创建一个对象。
l 我们在引用库的point UDT前加上导入语句中定义的pt别名,就像使用导入库中的函数一样。
如果一个库的任何导出函数使用了该用户定义类型的参数或返回了该用户定义类型的结果,那么该库中使用的UDT必须是导出的。
如果库仅在内部使用UDT,则不必导出。下面的库在内部使用了point UDT,但只导出了drawPivots()函数,该函数不使用参数,也不返回point类型的结果:
//@version=5
library("PivotLabels", true)
// 我们在库中使用了这个 `point` UDT,但不需要导出,因为:
// 1. 导出函数的参数不使用 UDT。
// 2. 导出函数不返回 UDT 结果。 type point
int x
float y
bool isHi
bool wasBreached = false
fillPivotsArray(qtyLabels, leftLegs, rightLegs) =>
// 创建一个数组,其中包含指定数量的枢轴。
var pivotsArray = array.new<point>(math.max(qtyLabels, 0))
// 检测枢轴.
float pivotHi = ta.pivothigh(leftLegs, rightLegs)
float pivotLo = ta.pivotlow(leftLegs, rightLegs)
// 当找到一个枢轴时,创建一个新的 `point` 对象。
point foundPoint = switch
pivotHi => point.new(time[rightLegs], pivotHi, true)
pivotLo => point.new(time[rightLegs], pivotLo, false)
=> na
// 在数组中添加新的枢轴信息,并移除最旧的枢轴。
if not na(foundPoint)
array.push(pivotsArray, foundPoint)
array.shift(pivotsArray)
array<point> result = pivotsArray
detectBreaches(pivotsArray) =>
// 检测终止。
for [i, eachPoint] in pivotsArray
if not na(eachPoint)
if not eachPoint.wasBreached
bool hiWasBreached = eachPoint.isHi and high[1] <= eachPoint.y and high > eachPoint.y
bool loWasBreached = not eachPoint.isHi and low[1] >= eachPoint.y and low < eachPoint.y
if hiWasBreached or loWasBreached
//枢轴被突破;更改wasBreached字段
point p = array.get(pivotsArray, i)
p.wasBreached := true
array.set(pivotsArray, i, p)
drawLabels(pivotsArray) =>
for eachPoint in pivotsArray
if not na(eachPoint)
label.new(
eachPoint.x,
eachPoint.y,
str.tostring(eachPoint.y, format.mintick),
xloc.bar_time,
color = eachPoint.wasBreached ? color.gray : eachPoint.isHi ? color.teal : color.red,
style = eachPoint.isHi ? label.style_label_down: label.style_label_up,
textcolor = eachPoint.wasBreached ? color.silver : color.white)
//@function 显示最后 `qtyLabels` 枢轴的标签。
// 枢轴高点标签为绿色,枢轴低点标签为红色,终止枢轴标签为灰色。
// @param qtyLabels(simple int)要显示的最后标签的数量。
// @param leftLegs (simple int) 枢轴左长度。
// @param rightLegs (simple int) 枢轴右长度。
// @returns Nothing.
export drawPivots(int qtyLabels, int leftLegs, int rightLegs) =>
//在枢轴出现时收集它们。
pointsArray = fillPivotsArray(qtyLabels, leftLegs, rightLegs)
//标记突破枢轴。
detectBreaches(pointsArray)
// 绘制一次标签。
if barstate.islastconfirmedhistory
drawLabels(pointsArray)
//函数使用示例。
drawPivots(20, 10, 5)
如果 TradingView 用户发布了上述库,可以这样使用:
//@version=5
indicator("")
import TradingView/PivotLabels/1 as dpl
dpl.drawPivots(20, 10, 10)
在您或其他Pine Script®程序员重新使用任何库之前,必须先发布该库。如果您想与所有TradingViewers共享您的程序库,请将其公开发布。如需私人使用,请使用私人发布。与指标或策略一样,当您发布库时,活动图表将同时出现在其窗口小部件(TradingView 脚本流中表示库的小占位符)和脚本页面(用户点击窗口小部件时看到的页面)中。
私有库可用于受保护或仅受邀请的公共脚本。
将我们的示例库添加到图表中并设置一个干净的图表,按我们想要的方式显示我们的库绘图后,我们使用Pine编辑器的"发布脚本"按钮,“发布库”窗口就会出现:
请注意:
l 我们保持库的标题不变(library()声明语句中的title参数被用作默认值)。虽然可以更改出版物的标题,但最好保留默认值,因为title参数用于在import语句中引用导入的库。当出版物的标题与库的实际名称一致时,库用户的使用会更方便。
l 默认描述是根据我们在库中使用的编译器注释建立的。我们将不加修饰地发布该库。
l 我们选择公开发布库,则所有TradingViewer都可以看到它。
l 我们无法选择"公开"以外的可见类型,因为库始终是开源的。
l 库的类别目录与指标和策略不同。我们选择了"统计和度量"类别。
l 我们添加了一些自定义标签:"all-time"、"high"和"low"。
公共库的目标用户是其他Pine程序员;您对库功能的解释和记录越完善,其他人使用它们的机会就越大。在出版物代码中提供如何使用库函数的示例也会有所帮助。
在我们的《脚本发布规则》中,Pine库被视为"公共领域"代码,这意味着如果你在开源脚本中调用其函数或重用其代码,无需获得其作者的许可。不过,如果你打算在受公共保护或仅受邀请的出版物中重复使用Pine Script®库函数中的代码,则必须获得其作者的明确许可。
无论是使用库函数还是重复使用其代码,你都必须在出版物的说明中注明作者。在开源注释中注明作者也是一种良好的方式。
通过导入语句可以从其他脚本中使用库(可以是指标、策略或其他库):
import <username>/<libraryName>/<libraryVersion> [as <alias>]
其中:
l <username>/<libraryName>/<libraryVersion>路径将唯一标识该库。
l <libraryVersion>必须明确指定。为确保使用库的脚本的可靠性,无法自动使用库的最新版本。每次库的作者发布库更新时,库的版本号都会增加。要使用最新版本的库,需要在导入语句中更新<libraryVersion>值。
l as <alias>部分是可选的。它定义了引用库函数的命名空间。例如,如果使用allTime别名导入一个库,就会将该库的函数称为allTime.<function_mame>()。如果没有定义别名,库的名称将成为其命名空间。
要使用我们在上一节中发布的库,我们的下一个脚本将需要导入语句:
import PineCoders/AllTimeHighLow/1 as allTime
在键入库作者的用户名时,可以使用编辑器的 ctrl + 空格/cmd + 空格 "自动完成 "命令,弹出一个与可用库匹配的选项:

这是一个重复使用我们库的指标:
//@version=5
indicator("Using AllTimeHighLow library", "", true)
import PineCoders/AllTimeHighLow/1 as allTime
plot(allTime.hi())
plot(allTime.lo())
plot(allTime.hi(close))
请注意:
l 我们选择在脚本中使用"allTime "作为库实例的别名。在编辑器中键入该别名时,将出现一个弹出窗口,帮助您选择要使用的库中的特定函数。
l 我们使用函数库的hi()和lo()函数时不使用参数,因此默认的high和low内置变量将分别用于它们的序列。
l 我们再次调用allTime.hi(),但这次使用close作为参数,以绘制图表历史上的最高收盘价。
线条和方框
简介
线条和方框只适用于Pine Script®的第4版或更高版本。它们可用于绘制支撑位和阻力位、趋势线和价格区间。在绘制复杂的几何图形时,多个小线段也很有用。
线段和方框的定位机制非常灵活,因此特别适用于绘制过去的点位,而这些点位是在事后的不同K线段中检测到的。
线条和方框是一种对象,就像标签和表格一样。与它们一样,它们也使用ID(类似于指针)来表示。线条ID属于"line"类型,方框ID属于"box"类型。与其他对象一样,线条和方框ID也是"时间序列",用于管理它们的所有函数都接受"series"参数,因此非常灵活。
注意事项
在TradingView图表中,一整套绘图工具允许用户使用鼠标操作来创建和修改绘图。虽然它们有时看起来与使用Pine Script®代码创建的绘图对象相似,但它们是毫不相关的实体。使用Pine代码创建的线条和方框无法通过鼠标操作进行修改,而Pine脚本也无法显示图表用户界面中的手绘图形。
线可以是水平的,也可以是有角度的,而方框总是矩形的。两者有许多共同特点:
l 它们可以从图表上的任意点开始和结束,包括未来。
l 用于管理它们的函数可以放在条件或循环结构中,从而更容易控制它们的行为。
l 它们可以在锚定坐标的左侧或右侧无限延伸。
l 它们的属性可以在脚本执行过程中更改。
l 用于定位它们的x坐标可以表示为K线索引或时间值。
l 在x坐标中,它们在K线的中间位置开始和停止。
l 不同的预定义样式可用于线型、端点和方框边框。
l 在任何给定时间内,图表上最多可绘制500种样式。默认值为50,但可以在indicator()或strategy()声明语句中使用max_lines_count和max_boxes_count参数指定最多500个。线条和方框与标签一样,使用垃圾回收机制进行管理,该机制会删除图表上最旧的线条和方框,因此只有最近显示的线条和方框才可见。
本脚本同时绘制线条和方框:
//@version=5
indicator("Opening bar's range", "", true)
string tfInput = input.timeframe("D", "Timeframe")
// 仅在第 0 个K线时初始化变量,因此它们的值会跨K线保留。
var hi = float(na)
var lo = float(na)
var line hiLine = na
var line loLine = na
var box hiLoBox = na
// 检测时间框架的变化。
bool newTF = ta.change(time(tfInput))
if newTF
//更高时间框架中新建K线;重置数值并创建新线条和方框
hi := high
lo := low
hiLine := line.new(bar_index - 1, hi, bar_index, hi, color = color.green, width = 2)
loLine := line.new(bar_index - 1, lo, bar_index, lo, color = color.red, width = 2)
hiLoBox := box.new(bar_index - 1, hi, bar_index, lo, border_color = na, bgcolor = color.silver)
int(na)
else
// 在其他 K 条上,扩展线条和方框的右坐标。
line.set_x2(hiLine, bar_index)
line.set_x2(loLine, bar_index)
box.set_right(hiLoBox, bar_index)
// 根据高/低是否高于/低于方框,改变方框背景的颜色。
boxColor = high > hi ? color.green : low < lo ? color.red : color.silver
box.set_bgcolor(hiLoBox, color.new(boxColor, 50))
int(na)
请注意:
l 我们检测用户定义的较高时间框架的第一个K线,并保存其最高价和低位值。
l 我们用一个线条分别绘制最高价hi和最低价low。
l 我们用方框填充中间的空间。
l 每次创建两条新线和一个方框时,我们都会将其ID保存在变量 hiLine、loLine和hiLoBox 中,然后在调用设置函数时使用这些变量,以便在较高时间框架中出现新的K线时延长这些对象的时间。
l 我们使用K线的最高价和最低价相对于开始K线相应价格的位置来更改方框背景的颜色(boxColor)。这意味着我们的脚本需要重新绘制,因为根据当前K线的值,过去K线上的方框的颜色会发生变化。
l 我们特意将if结构的两个分支的返回类型都改为 int(na),这样编译器就不会抱怨它们的返回类型不一样。出现这种情况是因为第一个分支中的box.new() 返回的结果类型为"box",而第二个分支中的box.set_bgcolor() 返回的类型为"void"。
更多信息,请参阅 "匹配局部块类型要求 "部分。
线条使用行命名空间中的内置函数进行管理。它们包括:
l line.new() 用于创建行。
l line.set_*()函数用于修改行的属性。
l line.get_*()函数用于读取现有行的属性。
l line.copy() 用来克隆它们。
l line.delete() 用于删除它们。
l line.all 数组始终包含图表上所有可见线条的ID。数组的大小取决于脚本的最大线条数和已绘制的线条数。aray.size(line.all) 将返回数组的大小。
line.new()函数用于创建新线条。其签名如下:
line.new(x1, y1, x2, y2, xloc, extend, color, style, width) → series line
线根据 x(K 线)和 y(价格)坐标在图表上定位。影响这种行为的参数有五个:x1、y1、x2、y2和xloc:
x1和x2
它们是线条起点和终点的x坐标。它们可以是K线索引,也可以是时间值,由xloc使用的参数决定。使用K线索引时,该值可以偏移到过去(最多5000条)或未来(最多500条)。使用时间值时,也可以计算过去或未来的偏移量。使用line.set_x1()、line.set_x2()、line.set_xy1() 或 line.set_xy2()可以修改现有线条的x1和x2值。
xloc
是xloc.bar_index(默认值)或xloc.bar_time。它决定了哪种类型的参数必须与x1和x2一起使用。如果使用 xloc.bar_index,x1和x2必须是绝对K线索引。对于 xloc.bar_time,x1和x2必须是一个UNIX时间戳,单位为毫秒,与某条K线的开盘时间值相对应。使用 line.set_xloc()可以修改现有线条的xloc值。
y1和y2
它们是线条起点和终点的y坐标。虽然被称为价位,但在脚本的视觉空间它们的值必须有意义。例如对于RSI指标,它们通常介于0和100之间。当指标以叠加方式运行时,价格刻度通常是商品的价格刻度。使用line.set_y1()、line.set_y2()、line.set_xy1()或line.set_xy2() 可以修改现有线条的y1和y2值。
line.new() 中的其余四个参数控制线条的视觉外观:
决定线条是否超出其坐标。可以是 extend.none、extend.left、extend.right 或 extend.both。
线条的颜色。
是线条的样式。请参阅本页的线条样式部分。
以像素为单位确定线条的宽度。
下面是个创建最简单线条的方法。我们将前一K线的高点与当前K线的低点连接起来:
//@version=5
indicator("", "", true)
line.new(bar_index - 1, high[1], bar_index, low, width = 3)
请注意:
l 我们使用不同的x1和x2值:bar_index - 1和bar_index。这是必要的,否则将无法创建线条。
l 我们使用width = 3将线条宽度设为3像素。
l 没有逻辑控制我们的line.new()调用,因此在每个K线都会创建线条。
l 只显示大约最后50行,因为这是indicator()中max_lines_count参数的默认值,我们未指定该参数。
l 线条在K线上持续存在,直到脚本使用line.delete()将其删除,或垃圾回收将其移除。
在下一个示例中,我们使用线条为价格创建可能的移动路径。我们从上一K线的收盘价和开盘价之间的中心点绘制用户选择数量的线条。这些线沿着当前K线的收盘价和开盘价范围分布后,在当前K线之后投影一个K线:
//@version=5
indicator("Price path projection", "PPP", true, max_lines_count = 100)
qtyOfLinesInput = input.int(10, minval = 1)
y2Increment = (close - open) / qtyOfLinesInput
// 风扇的起点,单位y。
lineY1 = math.avg(close[1], open[1])
//在每个K线上循环创建扇形线。
for i = 0 to qtyOfLinesInput
// 如果线条在当前K线处停止,以 y 为单位的终点。
lineY2 = open + (y2Increment * i)
// 将必要的 y 位置推断到下一K线,因为我们将线延伸到未来的一个K线。
lineY2 := lineY2 + (lineY2 - lineY1)
lineColor = lineY2 > lineY1 ? color.lime : color.fuchsia
line.new(bar_index - 1, lineY1, bar_index + 1, lineY2, color = lineColor)
请注意:
l 我们在for结构中创建一组线条。
l 我们使用默认的xloc = xloc.bar_index,因此我们的x1和x2值是K线索引。
l 我们希望从上一个K线开始绘制线条,因此我们使用bar_index - 1表示x1,使用bar_index + 1表示x2。
l 我们使用"series color "值(其值可在循环的任何迭代中改变)作为线条的颜色。当线条上升时,我们将其颜色设为草绿色;当线条下降时,我们将其颜色设为紫红色。
l 脚本会实时重新绘制,因为它使用实时K线的收盘和开盘价来计算线的投影。一旦实时K线收盘,在经过的实时K线上绘制的线条将不再更新。
l 我们在indicator()调用中使用max_lines_count = 100来保留最后100条线。
允许您更改线条属性的设置函数有:
它们都有相似的签名。line.set_color()的签名是:
line.set_color(id, color) → void
其中
l id是要修改属性的线条的ID。
l 下一个参数是要修改的线条的属性,这取决于所使用的设置函数。line.set_xy1()和line.set_xy2()修改了两个属性,因此有两个这样的参数。
在下一个示例中,我们将显示一线条,显示最后一个 lookbackInput条K线中的最高high值。我们将使用setter函数来修改现有的线条:
//@version=5
MAX_BARS_BACK = 500
indicator("Last high", "", true, max_bars_back = MAX_BARS_BACK)
repaintInput = input.bool(false, "Position bars in the past")
lookbackInput = input.int(50, minval = 1, maxval = MAX_BARS_BACK)
//持续跟踪最高 "high "值,并在其发生变化时进行线条检测。
hi = ta.highest(lookbackInput)
newHi = ta.change(hi)
// 找出过去 50 个K线中最高 "high"的偏移量。将其符号改为正数。
highestBarOffset = - ta.highestbars(lookbackInput)
//只在零号K线上创建标签。
var lbl = label.new(na, na, "", color = color(na), style = label.style_label_left)
var lin = line.new(na, na, na, na, xloc = xloc.bar_time, style = line.style_arrow_right)
// 发现新的高点后,将标签移动到该高点,并更新其文本和tooltip。
if newHi
//建设线路。
lineX1 = time[highestBarOffset + 1]
// 获取此偏移量的 `high` 值。请注意,"highest(50) "是等价的、
// 但在进入此 `if` 结构之前,需要对每个 K 行进行评估。
lineY = high[highestBarOffset]
// 确定线条的起点,用户可设置是否在过去绘制。
line.set_xy1(lin, repaintInput ? lineX1 : time[1], lineY)
line.set_xy2(lin, repaintInput ? lineX1 : time, lineY)
// 重新定位标签,显示新高值。
label.set_xy(lbl, bar_index, lineY)
label.set_text(lbl, str.tostring(lineY, format.mintick))
else
// 将线的右端点和标签更新为当前K线的右端点和标签。
line.set_x2(lin, time)
label.set_x(lbl, bar_index)
// 发现新高时,显示一个蓝点。
plotchar(newHi, "newHighFound", "•", location.top, size = size.tiny)
请注意:
l 我们绘制的线条起始于发现新高点的前一K线。我们从前面的K线开始绘线,这样当发现新高点时,我们就能看到一条单K线。·
l 只有当用户通过脚本输入明确选择时,我们才会从实际最高点开始绘制过去的线。这样,用户就可以控制脚本的重绘行为。这也避免了误导交易者,让他们以为我们的脚本先知先觉,能提前知道n个K线之后的回溯期中,某个高点是否还是高点。
l 我们对历史缓冲区进行管理,以避免在引用过去太远的K线时出现运行错误。为此,我们做了两件事:在我们的indicator()调用中使用max_bars_back参数,并在我们的input.int()调用中使用maxval为lookbackInput的输入设置上限。我们没有在两个地方使用500字面量,而是创建了一个MAX_BARS_BACK常量。
l 我们只在第一条K线上使用var创建线条和标签。从那时起,我们只需要更新它们的属性,因此我们是在移动同一条线条和标签,在发现新高时重置它们的位置和标签的文字,然后只在新的K线出现时更新它们的x坐标。我们在发现新高时使用line.set_xy1() 和 line.set_xy1()函数,在其他K线时使用line.set_x2(),以扩展线条。
l 我们为 x1 和 x2 使用时间值,因为我们的line.new()调用指定xloc = xloc.bar_time。
l 我们在line.new()调用中使用style = line.style_arrow_right,以显示右箭头线条样式。
l 尽管标签的背景不可见,但我们还是在label.new()调用中使用了style = label.style_label_left,以便将价格值定位在图表最后一个K线的右侧。
l 为了更直观地显示新的最高high是在哪一K线出现的,我们使用plotchar()绘制一个蓝点。请注意,这并不一定意味着出现蓝点的K线就是新的最高值。虽然这种情况可能会发生,但新的最高值也可能是由于一个长期存在的高点从回溯长度中跌落并被另一个高点所取代而计算出来的,而这个高点可能不在出现蓝点的K线上。
l 我们的图表光标指向最近50个K线中具有最高high值的K线。
l 当用户不选择绘制过去时,我们的脚本不会重新绘制。
l 线条样式
可以使用line.new()或line.set_style()函数对线条应用各种样式:
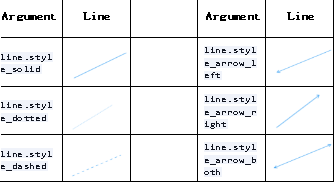
l 获取线条属性
以下获取器函数可用于线条:
l ·line.get_price()
l ·line.get_x1()
l ·line.get_y1()
l ·line.get_x2()
l ·line.get_y2()
line.get_price()的签名是:
line.get_price(id, x) → series float
其中:
l id是要获取x1值的线条
l x是要返回y坐标的线条上点的K线索引。
最后四个函数都有类似的签名。line.get_x1()的签名是:
line.get_x1(id) → series int
其中id是要获取x1值的线条的ID。
l 克隆线条
line.copy()函数用于克隆线条。其语法如下:
line.copy(id) → void
l 删除线条
line.delete()函数用于删除线条。其语法如下:
line.delete(id) → void
要在图表上只保留用户定义数量的线,可以使用类似这样的代码,在用户定义数量的连续K线中,每次RSI上升/下降时,我们都会显示一个水平线:
//@version=5
int MAX_LINES_COUNT = 500
indicator("RSI levels", max_lines_count = MAX_LINES_COUNT)
int linesToKeepInput = input.int(10, minval = 1, maxval = MAX_LINES_COUNT)
int sensitivityInput = input.int(5, minval = 1)
float myRSI = ta.rsi(close, 20)
bool myRSIRises = ta.rising(myRSI,sensitivityInput)
bool myRSIFalls ta.falling(myRSI,sensitivityInput)
if myRSIRises or myRSIFalls
color lineColor = myRSIRises ? color.new(color.green, 70) : color.new(color.red, 70)
line.new(bar_index, myRSI, bar_index + 1, myRSI, color = lineColor, width = 2)
// 创建新线条后,如果线条数过多,则删除最早的一线条。
if array.size(line.all) > linesToKeepInput
line.delete(array.get(line.all, 0))
int(na)
else
// 延长所有可见线条。
int lineNo = 0
while lineNo < array.size(line.all)
line.set_x2(array.get(line.all, lineNo), bar_index)
lineNo += 1
int(na)
plot(myRSI)
hline(50)
// 绘制标记以显示触发条件为 "真 "的位置。
plotchar(myRSIRises, "myRSIRises", "��", location.top, color.green, size = size.tiny)
plotchar(myRSIFalls, "myRSIFalls", "��", location.bottom, color.red, size = size.tiny)
请注意:
l 我们定义了一个MAX_LINES_COUNT常量,用于保存脚本可容纳的最大线条数。我们使用该值来设置indicator()调用中的max_lines_count参数值,并将其作为input.int()调用中的maxval值,以限制用户值。
l 我们使用myRSIRises和myRSIFalls变量来保存决定我们何时创建新级别的状态。之后,我们删除line.all内置数组中最旧的一线条,该数组由Pine Script®运行时自动维护,包含脚本绘制的所有可见线条的ID。我们使用array.get()函数获取索引为0的数组元素(最旧的可见线条ID)。然后,我们使用line.delete()删除该ID所引用的线条。
l 另外,我们需要在if结构的两个局部块中人为地返回int(na),这样编译器就不会报错了。更多信息,请参见"匹配局部块类型要求"部分。
l 这一次,我们在声明变量时明确提到了变量的类型,例如 float myRSI = ta.rsi(close, 20)。这些声明在功能上是多余的,但它们有助于让代码读者明确你的意图--你是最常阅读代码的人。
方框
方框使用box命名空间中的内置函数进行管理。它们包括:
l box.new()用于创建方框。
l box.set_*()函数用于修改方框的属性。
l box.get_*()函数用于读取现有方框的部分属性。
l box.copy()用于克隆它们。
l box.delete()用于删除它们。
l The box.all数组始终包含图表上所有可见方框的ID。数组的大小取决于脚本的最大方框数和已绘制的方框数。aray.size(box.all)将返回数组的大小。
box.new()函数用于创建新行。其签名如下:
box.new(left, top, right, bottom, border_color, border_width, border_style, extend, xloc, bgcolor, text, text_size, text_color, text_halign, text_valign, text_wrap, text_font_family) → series box
方框根据x(K线)和y(价格)坐标在图表上定位。影响这种行为的参数有五个:left, top, right, bottom和xloc:
它们是方框起点和终点的x坐标。它们可以是K线索引,也可以是时间值,由xloc使用的参数决定。使用K线索引时,该值可以偏移到过去(最多5000条)或未来(最多500条)。使用时间值时,也可以计算过去或未来的偏移量。使用 box.set_left()、box.set_right()、box.set_lefttop() 或 box.set_rightbottom() 可以修改现有方框的左右值。
xloc
是xloc.bar_index(默认值)或xloc.bar_time。它决定了左和右必须使用哪种类型的参数。使用xloc.bar_index时,左和右必须是绝对K线索引。如果使用xloc.bar_time,左侧和右侧必须是UNIX时间戳,单位为毫秒,对应K线的time(开盘时间)和time_close(收盘时间)值之间的某个值。
方框顶部和底部水平的y坐标(方框总是矩形的)。虽然它们被称为价位,但其值必须在脚本的可视空间中具有意义。例如,对于RSI指标,它们通常介于0和100之间。当指标以叠加方式运行时,价格刻度通常是商品的价格刻度。使用box.set_top()、box.set_bottom()、box.set_lefttop()或box.set_rightbottom()可以修改现有线条的顶部和底部值。
box.new() 中的其余五个参数控制方框的视觉外观:
border_color
是边框的颜色。默认为color.blue。
border_width
确定边框的宽度(以像素为单位)。
border_style
是边框的样式。请参阅本页的方框样式部分。
extend扩展
决定边框是否超出方框坐标。可以是extend.none、extend.left、extend.right或extend.both。
bgcolor颜色
是方框的背景颜色。默认为 color.blue。
让我们创建一个简单的方框:
//@version=5
indicator("", "", true)
box.new(bar_index, high, bar_index + 1, low, border_color = color.gray, bgcolor = color.new(color.silver, 60))
请注意:
l 方框的起点和终点与线一样,总是K线的水平中心。
l 我们从bar_index开始这些方框,并在bar_index + 1(未来的下一个K线)上结束它们,这样就得到了一个实际的方框。如果我们使用bar_index作为两个坐标,则只会在K线的中心绘制一条垂线条。
l 没有逻辑控制着我们的box.new()调用,因此在每个K线上都会创建方框。
l 只显示大约最后50个方框,因为这是indicator()中参数max_boxes_count的默认值,而我们没有指定该参数。
l 方框会一直存在于K线中,直到脚本使用box.delete()将其删除,或者垃圾回收将其移除。
方框图的可用设置函数有
·box.set_left()
·box.set_top()
·box.set_lefttop()
·box.set_right()
·box.set_bottom()
·box.set_rightbottom()
·box.set_border_color()
·box.set_border_width()
·box.set_border_style()
·box.set_extend()
·box.set_bgcolor()
不同于线条,没有修改方框xloc的设置函数。
此脚本使用设置函数更新方框。它检测用户定义的时间框架内涨跌幅度最大的K线,并根据这些K线的high和low绘制方框。如果出现更高的交易量K线,则会使用新K线的high和low重绘时间框架的方框:
//@version=5
indicator("High volume bar boxes", "", true)
string tfInput = input.timeframe("D", "Resetting timeframe")
int transpInput = 100 - input.int(100, "Line Brightness", minval = 0, maxval = 100, step = 5, inline = "1", tooltip = "100 is brightest")
int widthInput = input.int(2, "Width", minval = 0, maxval = 100, step = 5, inline = "1")
color upColorInput = input.color(color.lime, "��", inline = "1")
color dnColorInput = input.color(color.fuchsia, "��", inline = "1")
bool newTF = ta.change(time(tfInput))
bool barUp = close > open
// TF 期间,持续记录 发现的最高增多/减小交易量。
var float hiVolUp = na
var float hiVolDn = na
// 这些总是当前 TF 框的 ID。
var box boxUp = na
var box boxDn = na
if newTF and not na(volume)
// 新 TF 开始;创建新方框,其中一个方框将是不可见的。
if barUp
hiVolUp := volume
hiVolDn := na
boxUp := box.new(bar_index, high, bar_index + 1, low, border_color = color.new(upColorInput, transpInput), border_width = widthInput, bgcolor = na)
boxDn := box.new(na, na, na, na, border_color = color.new(dnColorInput, transpInput), border_width = widthInput, bgcolor = na)
else
hiVolDn := volume
hiVolUp := na
boxDn := box.new(bar_index, high, bar_index + 1, low, border_color = color.new(dnColorInput, transpInput), border_width = widthInput, bgcolor = na)
boxUp := box.new(na, na, na, na, border_color = color.new(upColorInput, transpInput), border_width = widthInput, bgcolor = na)
int(na)
else
// 在 HTF 期间的K线上,记录最高涨/跌量柱。
if barUp
hiVolUp := math.max(nz(hiVolUp), volume)
else
hiVolDn := math.max(nz(hiVolDn), volume)
// 如果新的K线具有更高的音量,则重置其方框。
if hiVolUp > nz(hiVolUp[1])
box.set_lefttop(boxUp, bar_index, high)
box.set_rightbottom(boxUp, bar_index + 1, low)
else if hiVolDn > nz(hiVolDn[1])
box.set_lefttop(boxDn, bar_index, high)
box.set_rightbottom(boxDn, bar_index + 1, low)
int(na)
// 所有K线上,向右延长方框
box.set_right(boxUp, bar_index + 1)
box.set_right(boxDn, bar_index + 1)
// TF改变时,画一个圆点。
plotchar(newTF, "newTF", "•", location.top, size = size.tiny)
请注意:
l 我们在与方框视觉外观相关的输入中使用inline参数,将方框置于同一行。
l 从100中减去用户指定的0-100亮度级别,从而为方框边框生成正确的透明度。这样做,对于用户来说,指定一个亮度级别(100代表最大亮度)更为直观。我们设置了一个tooltip来解释这个等级。
l 当发现新的较高时间框架K线,且该商品返回成交量数据时,我们会重置信息。如果时间框架的第一个K线是升高的,我们就会创建一个新的可见boxUp方框和一个不可见boxDn方框。如果第一条K线的方向是下降的,则做相反的操作。我们会将新创建的方框的ID重新分配给boxUp和boxUp,这样我们就能在稍后的脚本中更新这些方框。更多信息,请参阅var声明模式部分。
l 在同一较高时间框架的所有K线上,我们会监控成交量值,以跟踪最高的成交量。找到新的较高成交量K线,我们会使用box.set_lefttop()和box.set_rightbottom()重置新K线上相应方框的坐标。
l 在所有K线上,我们使用box.set_right()扩展时间框架右侧的两个方框。
l 由于我们没有在indicator()调用中使用max_boxes_count来更改默认值,因此图表上将显示大约最后50个方框。
这是我们脚本的"设置/输入"选项卡:
可以使用box.new()或box.set_border_style()函数为方框应用各种样式:
Argument | Box |
line.style_solid |
|
line.style_dotted |
|
line.style_dashed |
|
以下获取器函数适用于方框:
u box.get_bottom()
u box.get_left()
u box.get_right()
u box.get_top()
box.get_top() 的签名是:
box.get_top(id) → series float
其中id是要获取顶值的方框的ID。
box.copy()函数用于克隆方框。其语法如下:
box.copy(id) → void
box.delete()函数用于删除方框。其签名为:
box.delete(id) → void
实时行为
线条和方框都会受到提交和回滚操作的影响,这两个操作会影响脚本在实时K线中执行时的行为。请参阅 Pine Script® 的执行模型页面。
本脚本演示了在实时K线中运行时的回滚效果:
//@version=5
indicator("My Script", overlay = true)
line.new(bar_index, high, bar_index, low, width = 6)
当实时K线中的价格发生变化时,line.new()会在脚本的每次迭代中创建一条新线条,但由于下一次迭代前的回滚,上一次迭代中创建的最近一条线也会自动删除。只有在实时K线收盘前创建的最后一条线才会被提交,因此会持续存在。
限制条件
线条和方框会消耗服务器资源,因此每个指标或策略的绘图总数是有限制的。当创建的线条和方框过多时,Pine Script® 运行时会自动删除旧线条和方框,这一过程被称为垃圾回收。
这段代码会在每一个K线上创建一条线:
//@version=5
indicator("", "", true)
line.new(bar_index, high, bar_index, low, width = 6)
向左滚动图表,可以看到大约50个K线之后就没有线了:
使用indicator()或strategy()函数中的max_lines_count和max_boxes_count参数,将绘制限制为1至500之间的某个值:
//@version=5
indicator("", "", true, max_lines_count = 100)
line.new(bar_index, high, bar_index, low, width = 6)
使用xloc.bar_index定位的对象无法在未来绘制超过 500 条的K线。
l 其他securities
线条和方框不能在通过request.security()调用发送的函数中管理。虽然可以使用通过request.security()获取的值,但必须在主商品环境中绘制。
这也是为什么线条和方框绘制代码无法在使用indicator()中的时间框架参数的脚本中运行的原因。
将barstate.isrealtime与绘图结合使用有时会产生意想不到的结果。例如,此代码的意图是忽略所有历史K线,并在实时K线上创建标签绘图:
//@version=5
indicator("My Script", overlay = true)
if barstate.isrealtime
label.new(bar_index[300], na, text = "Label", yloc = yloc.abovebar)
发生运行时错误。错误的原因是脚本无法确定time坐标历史值的缓冲区大小,尽管代码中并未提及time内置变量。这是因为内置变量bar_index在其内部运作中使用了时间序列。要访问300条后的K线索引,需要时间序列的历史缓冲区大小达到或超过 300。
在 Pine Script® 中,有一种机制可以自动检测大多数情况下所需的历史缓冲区大小。自动检测的工作原理是,让脚本在有限的时间内访问任意数量的K线历史值。在本脚本中,if barstate.isrealtime 条件阻止了任何此类访问,因此无法推断出所需的历史缓冲区大小,代码也就失效了。
解决这一难题的办法是使用 max_bars_back函数显式设置时间序列的历史缓冲区大小:
//@version=5
indicator("My Script", overlay = true)
max_bars_back(time, 300)
if barstate.isrealtime
label.new(bar_index[300], na, text = "Label", yloc = yloc.abovebar)
这种情况虽然令人困惑,但并不多见。Pine Script®团队希望能及时消除这种现象。
范例
//@version=5
indicator("Pivot Points Standard", overlay = true)
higherTFInput = input.timeframe("D")
prevCloseHTF = request.security(syminfo.tickerid, higherTFInput, close[1], lookahead = barmerge.lookahead_on)
prevOpenHTF = request.security(syminfo.tickerid, higherTFInput, open[1], lookahead = barmerge.lookahead_on)
prevHighHTF = request.security(syminfo.tickerid, higherTFInput, high[1], lookahead = barmerge.lookahead_on)
prevLowHTF = request.security(syminfo.tickerid, higherTFInput, low[1], lookahead = barmerge.lookahead_on)
pLevel = (prevHighHTF + prevLowHTF + prevCloseHTF) / 3
r1Level = pLevel * 2 - prevLowHTF
s1Level = pLevel * 2 - prevHighHTF
var line r1Line = na
var line pLine = na
var line s1Line = na
if pLevel[1] != pLevel
line.set_x2(r1Line, bar_index)
line.set_x2(pLine, bar_index)
line.set_x2(s1Line, bar_index)
line.set_extend(r1Line, extend.none)
line.set_extend(pLine, extend.none)
line.set_extend(s1Line, extend.none)
r1Line := line.new(bar_index, r1Level, bar_index, r1Level, extend = extend.right)
pLine := line.new(bar_index, pLevel, bar_index, pLevel, width=3, extend = extend.right)
s1Line := line.new(bar_index, s1Level, bar_index, s1Level, extend = extend.right)
label.new(bar_index, r1Level, "R1", style = label.style_none)
label.new(bar_index, pLevel, "P", style = label.style_none)
label.new(bar_index, s1Level, "S1", style = label.style_none)
if not na(pLine) and line.get_x2(pLine) != bar_index
line.set_x2(r1Line, bar_index)
line.set_x2(pLine, bar_index)
line.set_x2(s1Line, bar_index)
//@version=5
indicator("Pivot Points High Low", "Pivots HL", true)
int lenHInput = input.int(10, "Length High", minval = 1)
int lenLInput = input.int(10, "Length Low", minval = 1)
float pivotHigh = ta.pivothigh(high, lenHInput, lenHInput)
float pivotLow = ta.pivotlow(low, lenLInput, lenLInput)
float pivot = 0.0
if not na(pivotHigh)
pivot := nz(high[lenHInput])
label.new(nz(bar_index[lenHInput]), pivot, str.tostring(pivot, format.mintick), style = label.style_label_down, yloc = yloc.abovebar, color = color.lime)
if not na(pivotLow)
pivot := nz(low[lenLInput])
label.new(nz(bar_index[lenLInput]), pivot, str.tostring(pivot, format.mintick), style = label.style_label_up, yloc = yloc.belowbar, color = color.red)
//@version=5
indicator('Linear Regression', shorttitle='LinReg', overlay=true)
upperMult = input(title='Upper Deviation', defval=2)
lowerMult = input(title='Lower Deviation', defval=-2)
useUpperDev = input(title='Use Upper Deviation', defval=true)
useLowerDev = input(title='Use Lower Deviation', defval=true)
showPearson = input(title='Show Pearson\'s R', defval=true)
extendLines = input(title='Extend Lines', defval=false)
len = input(title='Count', defval=100)
src = input(title='Source', defval=close)
extend = extendLines ? extend.right : extend.none
calcSlope(src, len) =>
if not barstate.islast or len <= 1
[float(na), float(na), float(na)]
else
sumX = 0.0
sumY = 0.0
sumXSqr = 0.0
sumXY = 0.0
for i = 0 to len - 1 by 1
val = src[i]
per = i + 1.0
sumX := sumX + per
sumY := sumY + val
sumXSqr := sumXSqr + per * per
sumXY := sumXY + val * per
sumXY
slope = (len * sumXY - sumX * sumY) / (len * sumXSqr - sumX * sumX)
average = sumY / len
intercept = average - slope * sumX / len + slope
[slope, average, intercept]
[s, a, intercpt] = calcSlope(src, len)
startPrice = intercpt + s * (len - 1)
endPrice = intercpt
var line baseLine = na
if na(baseLine) and not na(startPrice)
baseLine := line.new(bar_index - len + 1, startPrice, bar_index, endPrice, width = 1, extend=extend, color = color.red)
baseLine
else
line.set_xy1(baseLine, bar_index - len + 1, startPrice)
line.set_xy2(baseLine, bar_index, endPrice)
na
calcDev(src, len, slope, average, intercept) =>
upDev = 0.0
dnDev = 0.0
stdDevAcc = 0.0
dsxx = 0.0
dsyy = 0.0
dsxy = 0.0
periods = len - 1
daY = intercept + slope * periods / 2
val = intercept
for i = 0 to periods by 1
price = high[i] - val
if price > upDev
upDev := price
upDev
price := val - low[i]
if price > dnDev
dnDev := price
dnDev
price := src[i]
dxt = price - average
dyt = val - daY
price := price - val
stdDevAcc := stdDevAcc + price * price
dsxx := dsxx + dxt * dxt
dsyy := dsyy + dyt * dyt
dsxy := dsxy + dxt * dyt
val := val + slope
val
stdDev = math.sqrt(stdDevAcc / (periods == 0 ? 1 : periods))
pearsonR = dsxx == 0 or dsyy == 0 ? 0 : dsxy / math.sqrt(dsxx * dsyy)
[stdDev, pearsonR, upDev, dnDev]
[stdDev, pearsonR, upDev, dnDev] = calcDev(src, len, s, a, intercpt)
upperStartPrice = startPrice + (useUpperDev ? upperMult * stdDev : upDev)
upperEndPrice = endPrice + (useUpperDev ? upperMult * stdDev : upDev)
var line upper = na
lowerStartPrice = startPrice + (useLowerDev ? lowerMult * stdDev : -dnDev)
lowerEndPrice = endPrice + (useLowerDev ? lowerMult * stdDev : -dnDev)
var line lower = na
if na(upper) and not na(upperStartPrice)
upper := line.new(bar_index - len + 1, upperStartPrice, bar_index, upperEndPrice, width=1, extend=extend, color=#0000ff)
upper
else
line.set_xy1(upper, bar_index - len + 1, upperStartPrice)
line.set_xy2(upper, bar_index, upperEndPrice)
na
if na(lower) and not na(lowerStartPrice)
lower := line.new(bar_index - len + 1, lowerStartPrice, bar_index, lowerEndPrice, width=1, extend=extend, color=#0000ff)
lower
else
line.set_xy1(lower, bar_index - len + 1, lowerStartPrice)
line.set_xy2(lower, bar_index, lowerEndPrice)
na
// Pearson's R
var label r = na
transparent = color.new(color.white, 100)
label.delete(r[1])
if showPearson and not na(pearsonR)
r := label.new(bar_index - len + 1, lowerStartPrice, str.tostring(pearsonR, '#.################'), color=transparent, textcolor=#0000ff, size=size.normal, style=label.style_label_up)
r
l Zig Zag-之字形
//@version=5
indicator('Zig Zag', overlay = true)
float dev_threshold = input.float(title = 'Deviation (%)', defval = 5, minval = 1, maxval = 100)
int depth = input.int(title = 'Depth', defval = 10, minval = 1)
type Point
int index
float price
type Pivot
line ln
bool isHigh
Point point
var pivotArray = array.new<Pivot>()
int length = math.floor(depth / 2)
float pH = ta.pivothigh(high, length, length)
float pL = ta.pivotlow(low,length, length)
calcDeviation(base_price, price) =>
100 * math.abs(price - base_price) / base_price
newPivot(Point lastPoint, bool isHigh, int index, float price) =>
line ln = line.new(lastPoint.index, lastPoint.price, index, price, color = color.red, width = 2)
Pivot pivot = Pivot.new(ln, isHigh, Point.new(index, price))
array.push(pivotArray, pivot)
pivot
updatePivot(Pivot pivot, int index, float price) =>
line ln = pivot.ln
line.set_xy2(ln, index, price)
pivot.point.index := index
pivot.point.price := price
pivot
isPivotFound(bool isHigh, float price) =>
bool result = false
int index = bar_index[length]
int size = array.size(pivotArray)
Pivot prevPivot = size >= 1 ? array.get(pivotArray, size - 1) : newPivot(Point.new(index, price), isHigh, index, price)
if prevPivot.isHigh and not na(prevPivot.ln)
m = isHigh ? 1 : -1
if price * m > prevPivot.point.price * m
updatePivot(prevPivot, index, price)
result := true
else if na(prevPivot.ln) or math.abs(calcDeviation(prevPivot.point.price, price)) >= dev_threshold
newPivot(prevPivot.point, isHigh, index, price)
result := true
result
isPivotFound(true, pH)
isPivotFound(false, pL)
非标准图表数据
功能介绍
这些函数允许脚本从非标准K线或图表类型中获取信息,与脚本运行的图表类型无关。它们是:ticker.heikinashi()、ticker.renko()、ticker.linebreak()、ticker.kagi() 和 ticker.pointfigure()。它们的工作方式相同,都是创建一个特殊的 ticker 标识符,作为 request.security()函数调用的第一个参数。
ticker.heikinashi()`
Heikin-Ashi 在日语中是平均K线的意思。Heikin-Ashi 蜡烛图的开盘价/最高价/最低价/收盘价是合成的,并非实际市场价格。它们是通过计算当前和前一K线的实际OHLC值组合的平均值得出的。所使用的计算方法使Heikin-AshiK线的噪声小于普通蜡烛图。它们有助于进行直观评估,但不适用于回溯测试或自动交易,因为订单是根据市场价格而非 Heikin-Ashi 价格执行的。
ticker.heikinashi()函数创建了一个特殊的股票标识符,用于使用 request.security()函数请求Heikin-Ashi数据。
该脚本请求Heikin-Ashi线的收盘价,并将其绘制在普通蜡烛图之上:
//@version=5
indicator("HA Close", "", true)
haTicker = ticker.heikinashi(syminfo.tickerid)
haClose = request.security(haTicker, timeframe.period, close)
plot(haClose, "HA Close", color.black, 3)
请注意:
l ·黑线绘制的 Heikin-AshiK线的收盘价与使用市场价格绘制的真实蜡烛图的收盘价截然不同。它们更像是移动平均线。
l ·黑线出现在图表K线之上,是因为我们从脚本的"更多"菜单中选择了"视觉顺序/置于顶层"。
如果您想省略上一个示例中的延长时间值,则需要先创建一个不包含延长交易时段信息的中介商交易码:
indicator("HA Close", "", true)
regularSessionTicker = ticker.new(syminfo.prefix, syminfo.ticker, session.regular)
haTicker = ticker.heikinashi(regularSessionTicker)
haClose = request.security(haTicker, timeframe.period, close, gaps = barmerge.gaps_on)
plot(haClose, "HA Close", color.black, 3, plot.style_linebr)
请注意:
l ·我们首先使用 ticker.new()函数创建一个没有扩展交易时段信息的代号。
l ·我们在 ticker.heikinashi() 调用中使用该代号而不是 syminfo.tickerid 。
l ·在 request.security() 调用中,我们将 gaps 参数的值设置为 barmerge.gaps_on。这将指示函数不要使用以前的值来填补没有数据的空隙。这样,它就可以在常规交易时段之外返回 na 值。
l ·为了能在图表上看到这一点,我们还需要使用特殊的plot.style_linebr样式,该样式根据na值中断绘图。
该脚本在图表下绘制 Heikin-Ashi 蜡烛图:
//@version=5
indicator("Heikin-Ashi candles")
CANDLE_GREEN = #26A69A
CANDLE_RED = #EF5350
haTicker = ticker.heikinashi(syminfo.tickerid)
[haO, haH, haL, haC] = request.security(haTicker, timeframe.period, [open, high, low, close])
candleColor = haC >= haO ? CANDLE_GREEN :CANDLE_RED
plotcandle(haO, haH, haL, haC, color = candleColor)
l 我们在 request.security() 中使用元组,通过相同的调用获取四个值。
l 我们使用 plotcandle() 绘制蜡烛图。更多信息,请参阅 "K线绘图 "页面。
ticker.renko()
Renko柱只绘制价格走势,不考虑时间或成交量,看起来就像堆叠在相邻柱子上的砖块[1]。只有当价格超过顶部或底部的预定值时,才会绘制新的砖块。ticker.renko()创建了一个ticker id,可与request.security()一起用于获取Renko值,但没有Pine Script®函数在图表上绘制Renko柱:
indicator("", "", true)
lineBreakTicker = ticker.linebreak(syminfo.tickerid, 3)
lineBreakClose = request.security(lineBreakTicker, timeframe.period, close)
plot(lineBreakClose)
ticker.linebreak()
折线图类型显示一系列基于价格变化的垂直方框[1]。ticker.linebreak()函数创建了一个ticker id,可与request.security()配合使用,以获取"折线图"值,但没有 Pine Script®函数在图表上绘制此类K线:
indicator("", "", true)
kagiBreakTicker = ticker.linebreak(syminfo.tickerid, 3)
kagiBreakClose = request.security(kagiBreakTicker, timeframe.period, close)
plot(kagiBreakClose)
`ticker.kagi()`
Kagi 图表是由一条不断改变方向的连续线段组成的。当价格变化[1]超过预定值时,方向就会改变。ticker.kagi()函数创建了一个 ticker id,可与 request.security() 一起使用以获取 "Kagi "值,但目前还没有 Pine Script®函数在图表上绘制此类K线:
//@version=5
indicator("", "", true)
kagiBreakTicker = ticker.linebreak(syminfo.tickerid, 3)
kagiBreakClose = request.security(kagiBreakTicker, timeframe.period, close)
plot(kagiBreakClose)
点数图(PnF)图表只绘制价格走势[1],而不考虑时间。价格上涨时绘制一列X,价格下跌时绘制一列O。ticker.pointfigure()函数创建了一个 ticker id,可以与 request.security() 一起使用来获取 "PnF "值,但没有 Pine Script®函数在图表上绘制此类K线。每列 X 或 O 用四个数字表示。你可以将它们视为合成的 OHLC PnF 值:
//@version=5
indicator("", "", true)
pnfTicker = ticker.pointfigure(syminfo.tickerid, "hl", "ATR", 14, 3)
[pnfO, pnfC] = request.security(pnfTicker, timeframe.period, [open, close], barmerge.gaps_on)
plot(pnfO, "PnF Open", color.green, 4, plot.style_linebr)
plot(pnfC, "PnF Close", color.red, 4, plot.style_linebr)
脚注
(1, 2, 3, 4)在TradingView上,Renko、Line Break、Kagi和PnF图表类型是根据较低时间框架的OHLC值生成的,因此这些图表类型仅代表从tick数据生成时的近似值。
绘图
· 简介
· `plot()` 参数
· 条件绘图
o 数值控制
o 颜色控制
· 水平线
· Offsets
· 绘图计数限制
· 刻度
o 合并两个指标
引言
plot()函数是最常用的函数,用于显示使用 Pine 脚本计算的信息。它用途广泛,可以绘制不同风格的线条、K线、面积、柱图(如成交量)、填充、圆或交叉点。
关于使用plot()创建填充的说明,请参阅"填充"页面。
本脚本展示了 plot() 在叠加脚本中的几种不同用法:
//@version=5
indicator("`plot()`", "", true)
plot(high, "Blue `high` line")
plot(math.avg(close, open), "Crosses in body center", close > open ? color.lime : color.purple, 6, plot.style_cross)
plot(math.min(open, close), "Navy step line on body low point", color.navy, 3, plot.style_stepline)
plot(low, "Gray dot on `low`", color.gray, 3, plot.style_circles)
color VIOLET = #AA00FF
color GOLD = #CCCC00
ma = ta.alma(hl2, 40, 0.85, 6)
var almaColor = color.silver
almaColor := ma > ma[2] ? GOLD : ma < ma[2] ? VIOLET : almaColor
plot(ma, "Two-color ALMA", almaColor, 2)
请注意:
l 第一个 plot() 调用在K线高点上绘制一条 1 像素的蓝线。
l 第二次在机构的中间点绘制交叉点。当K线上涨时,交叉点的颜色为草绿色;当K线下跌时,交叉点的颜色为紫色。线宽参数为 6,但不是像素值,只是相对大小。
l 第三次调用绘制了一条 3 像素宽的阶梯线,该阶梯线紧随机构的低点。
l 第四次调用在K线的低点绘制一个灰色圆圈。
l 最后一个图需要一些准备工作。我们首先定义牛市/熊市颜色,计算 Arnaud Legoux 移动平均线,然后进行颜色计算。我们使用 var 将颜色变量初始化为 color.silver,因此在数据集的第一个K线上,直到我们的某个条件导致颜色改变,线都将是银色的。改变线条颜色的条件要求线条的颜色高于/低于两个 K 条前的值。这样,颜色转换时的噪音就会小于我们仅仅寻找比前一个值更高/更低的值。
该脚本展示了 plot() 在窗格中的其他用途:
//@version=5
indicator("Volume change", format = format.volume)
color GREEN = #008000
color GREEN_LIGHT = color.new(GREEN, 50)
color GREEN_LIGHTER = color.new(GREEN, 85)
color PINK = #FF0080
color PINK_LIGHT = color.new(PINK, 50)
color PINK_LIGHTER = color.new(PINK, 90)
bool barUp = ta.rising(close, 1)
bool barDn = ta.falling(close, 1)
float volumeChange = ta.change(volume)
volumeColor = barUp ? GREEN_LIGHTER : barDn ? PINK_LIGHTER : color.gray
plot(volume, "Volume columns", volumeColor, style = plot.style_columns)
volumeChangeColor = barUp ? volumeChange > 0 ? GREEN : GREEN_LIGHT : volumeChange > 0 ? PINK : PINK_LIGHT
plot(volumeChange, "Volume change columns", volumeChangeColor, 12, plot.style_histogram)
plot(0, "Zero line", color.gray)
请注意:
l 我们将正常的成交量值绘制为零线上方的宽柱图(参见我们 plot() 调用中的 style = plot.style_columns)。
l 在绘制列之前,我们使用 barUp 和 barDn 布尔变量的值计算 volumeColor。当当前K线的收盘价高于/低于上一个K线时,它们分别变为 true。请注意,内置的 "成交量 "并不使用相同的条件;它识别的是收盘价大于开盘价的上涨K线。我们对成交量列使用 GREEN_LIGHTER 和 PINK_LIGHTER 颜色。
l 由于第一幅图绘制的是K线,我们不使用线宽参数,因为它对K线没有影响。
l 我们脚本的第二幅图是成交量的变化,我们之前使用 ta.change(volume) 计算过。该值以K线的形式绘制,线宽参数控制着K线的宽度。我们将线宽设为 12,这样直方图元素就会比第一幅图的列更细。正/负的 volumeChange 值会绘制在零线上方/下方;无需任何操作即可实现这种效果。
l 绘制volumeChange值的K线之前,先计算其颜色值,它可以是四种不同颜色之一。当K线向上/向下,且成交量自上一个K线以来有所增加(volumeChange > 0)时,我们使用明亮的绿色或粉红色。由于在这种情况下volumeChange为正值,因此K线的元素将绘制在零线上方。当K线向上/向下,且成交量自上一交易日以来没有增加时,我们使用明亮的GREEN_LIGHT或PINK_LIGHT颜色。由于在这种情况下 volumeChange 为负值,因此直方图的元素将绘制在零线以下。
l 最后,我们绘制了一条零线。我们也可以在这里使用 hline(0)。
l 在indicator()调用中使用format = format.volume,这样本脚本显示的大数值就会像内置的"Volume"指标一样缩写。
plot()调用必须放在行的第一个位置,它们始终处于脚本的全局范围内。它们不能放在用户定义的函数或结构(如if、for等)中。不过,对plot()的调用可以通过两种方式有条件地绘制,我们将在本页的"有条件绘制"部分介绍。
脚本只能在自己的可视空间中绘制,无论是在窗格中还是在图表上作为叠加。在窗格中运行的脚本只能为图表区域中的K线着色。
plot()` 参数
plot()函数的签名如下:
plot(series, title, color, linewidth, style, trackprice, histbase, offset, join, editable, show_last, display) →plot
plot() 的参数如下:
series 系列
这是唯一的必选参数。它的参数必须是"int/float类型的序列"。请注意,由于Pine Script®中的自动转换规则是按int→float→bool方向转换的,因此"bool "类型的变量不能直接使用,必须转换为"int"或"float"类型才能作为参数使用。例如,如果newDay属于"bool"类型,那么newDay ? 1 : 0可以用来在变量为真时绘制1,在变量为假时绘制0。
title 标题
需要一个 "const string "参数,因此必须在编译时知道。该字符串会出现在
l 选中 "图表设置/刻度/指标名称标签 "字段后,会出现在脚本的刻度中。
l 在数据窗口中。
l 在 "设置/样式 "选项卡中。
l 在 input.source() 字段的下拉菜单中。
l 选择脚本后,在“创建警报”对话框的“条件”字段中。
l ·As 导出图表数据到 CSV 文件时的列标题。
color 颜色
接受 "series color",因此可以逐条计算。用 na 或任何透明度为 100 的颜色绘制图表,是在不需要时隐藏图表的一种方法。
linewidth 线宽
是绘图元素的大小,但并不适用于所有样式。绘制线条时,单位是像素。使用 plot.style_columns 时,它没有影响。
style 样式
可用参数如下:
l ·plot.style_line (默认): 它使用以像素为单位的线宽参数绘制一条连续的线。na值不会绘制成一条线,但当出现非na值时,它们会被桥接。非na值只有在图表上可见时才会被桥接。
l ·plot.style_linebr:允许绘制不连续的线,不在na值上绘制,也不连接间隙-即在na值上桥接。
l ·plot.style_stepline: 使用阶梯效果绘图。数值变化之间的过渡是通过在K线中间画一条垂线条来完成的,而不是通过连接K线中点的点对点对角线。也可用于实现与plot.style_linebr类似的效果,但必须注意在na值上不绘制颜色。
l plot.style_area:绘制具有线宽的线条,填充线条与基线之间的区域。color参数同时用于线条和填充。您可以通过调用 plot() 使线条变成不同的颜色。正值绘制在柱基上方,负值绘制在柱基下方。
l plot.style_areabr:它与 plot.style_area 类似,但不会在 na 值上搭桥。另一个区别是如何计算指标的刻度。只有绘制的数值才用于计算脚本视觉空间的 y 范围。例如,如果只绘制远离基线的高值,这些值将用于计算脚本视觉空间的 y 范围。正值绘制在柱基上方,负值绘制在柱基下方。
l plot.style_columns: 绘制与 "成交量 "内置指标类似的列。线宽值不会影响列的宽度。正值绘制在柱基上方,负值绘制在柱基下方。在脚本视觉空间的 y 比例中始终包含历史基点值。
l plot.style_histogram: 绘制的K线与 "成交量 "内置指标的K线类似,但线宽值用于确定K线柱条的宽度(以像素为单位)。需要注意的是,由于线宽需要一个 "输入 int 值",因此K线的K线宽度不能逐条变化。正值绘制在K线基数之上,负值绘制在K线基数之下。在脚本视觉空间的 y 比例中,始终包含 histbase 的值。
l plot.style_circles 和 plot.style_cross: 这些样式绘制的形状不会跨K线连接,除非同时使用 join = true。对于这些样式,线宽参数变成了一个相对的尺寸度量,其单位不是像素。
trackprice 跟踪价格
默认值为假。为真时,将在脚本的整个可视空间宽度上绘制一条虚线。它通常与 show_last = 1、offset = -99999 结合使用,以隐藏实际绘图,只留下残余的虚线。
histbase 基准点
这是用于 plot.style_area、plot.style_columns 和 plot.style_histogram 的参考点。它决定了系列参数正负值的分隔水平。它不能动态计算,因为需要 "输入 int/float"。
offset 偏移
允许使用负/正偏移量(以K线为单位)在过去/未来移动曲线图。该值在脚本执行期间不能更改。
join 连接
仅影响 plot.style_circles 或 plot.style_cross 样式。为真时,图形将由一条一像素的线连接。
editable 可编辑
此布尔参数控制是否可以在 "设置/样式 "选项卡中编辑绘图的属性。默认值为 "true"。
show_last 显示最后
允许控制所绘制数值中最后几条K线的可见度。需要输入 int 参数,因此无法动态计算。
display 显示
默认为display.all。当设置为display.none时,绘制的值不会影响脚本可视空间的比例。绘图将是不可见的,不会出现在指标值或数据窗口中。它适用于用作其他脚本外部输入的绘图,或在alertcondition()调用中使用{{plot("[plot_title]")}}占位符的绘图,如:
//@version=5
indicator("")
r = ta.rsi(close, 14)
xUp = ta.crossover(r, 50)
plot(r, "RSI", display = display.none)
alertcondition(xUp, "xUp alert", message = 'RSI is bullish at: {{plot("RSI")}}')
有条件地绘图
plot() 调用不能在 if 等条件结构中使用,但可以通过改变绘制值或颜色来控制它们。当不需要绘制时,可以绘制 na 值,或者使用 na 颜色或任何透明度为 100 的颜色(也可以使其不可见)绘制值。
l 数值控制
控制绘图显示的一种方法是在不需绘图时绘制na值。有时,当使用gaps = barmerge.gaps_on时,request.security()等函数返回的值会返回na值。在这两种情况下,绘制不连续的线条有时会很有用。本脚本展示了几种方法:

indicator("Discontinuous plots", "", true)
bool plotValues = bar_index % 3 == 0
plot(plotValues ? high : na, color = color.fuchsia, linewidth = 6, style = plot.style_linebr)
plot(plotValues ? high : na)
plot(plotValues ? math.max(open, close) : na, color = color.navy, linewidth = 6, style = plot.style_cross)
plot(plotValues ? math.min(open, close) : na, color = color.navy, linewidth = 6, style = plot.style_circles)
plot(plotValues ? low : na, color = plotValues ? color.green : na, linewidth = 6, style = plot.style_stepline)
l 定义的条件决定了我们何时使用 bar_index % 3 == 0 进行绘图,当K线索引除以 3 的余数为零时,该条件变为真。这将每隔三个K线发生一次。
l 在第一幅图中,我们使用plot.style_linebr,在高点绘制紫红色线。它以K线的水平中点为中心。
l 第二幅图显示的是绘制相同数值的结果,但没有对折线进行特殊处理。这里的情况是,调用普通plot()时的蓝色细线会自动越过Na值(或间隙),因此绘图不会中断。
l 然后在主体顶部和底部绘制海军蓝色的交叉点和圆圈。plot.style_circles 和 plot.style_cross 样式是绘制不连续值的简单方法,例如止损或止盈水平,或支撑和阻力水平。
l 最后一个绿色的K线低点图是使用plot.style_stepline绘制的。请注意,它的线段比用plot.style_linebr绘制的紫红色线段更宽。还请注意,在最后一个K线中,它只绘制了一半,直到下一个K线到来。
l 每个曲线图的绘制顺序由它们在脚本中的出现顺序控制。
本脚本展示了如何将绘图限制在用户定义日期之后的K线。我们使用input.time()函数创建一个输入widget,允许脚本用户选择日期和时间,默认值为2021年1月1日:
//@version=5
indicator("", "", true)
startInput = input.time(timestamp("2021-01-01"))
plot(time > startInput ? close : na)
l 颜色控制
颜色页面的"条件着色"部分讨论了绘图的颜色控制。这里我们将举例说明。
plot()中color参数的值可以是一个常量,例如内置常量颜色或颜色字面值。在Pine中,此类颜色的形式类型称为"const color"(参见类型系统页面),在编译时就已知:
//@version=5
indicator("", "", true)
plot(close, color = color.gray)
也可以使用只有当脚本在图表的第一个历史K线(K线零,即 bar_index == 0 或 barstate.isfirst ==true)上开始执行时才知道的信息来确定绘图的颜色,当确定颜色所需的信息取决于脚本运行的图表时,就会出现这种情况。在这里,我们使用 syminfo.type 内置变量计算绘图颜色,该变量返回商品的类型。在这种情况下,plotColor 的 form-type 将是 "simple color":
//@version=5
indicator("", "", true)
plotColor = switch syminfo.type
"stock" => color.purple
"futures" => color.red
"index" => color.gray
"forex" => color.fuchsia
"crypto" => color.lime
"fund" => color.orange
"dr" => color.aqua
"cfd" => color.blue
plot(close, color = plotColor)
printTable(txt) => var table t = table.new(position.middle_right, 1, 1), table.cell(t, 0, 0, txt, bgcolor = color.yellow)
printTable(syminfo.type)
也可以通过脚本的输入来选择绘图颜色。在这种情况下,lineColorInput 变量的表单类型为 "input color":
//@version=5
indicator("", "", true)
color lineColorInput = input(#1848CC,"Line color")
plot(close, color = lineColorInput)
最后,绘图颜色也可以是动态值,即只在每个K线中知道的计算值。这些颜色属于 "系列颜色 "表格类型:
//@version=5
indicator("", "", true)
plotColor = close >= open ? color.lime : color.red
plot(close, color = plotColor)
在绘制枢轴水平线时,一个常见的要求是避免绘制水平线的转换。使用线条是一种替代方法,但也可以像这样使用 plot():
//@version=5
indicator("Pivot plots", "", true)
pivotHigh = fixnan(ta.pivothigh(3,3))
plot(pivotHigh, "High pivot", ta.change(pivotHigh) ? na : color.olive, 3)
plotchar(ta.change(pivotHigh), "ta.change(pivotHigh)", "•", location.top, size = size.small)
请注意:
l 我们使用pivotHigh = fixnan(ta.pivothigh(3,3))来保存我们的枢轴值。因为ta.pivothigh()只在找到新的枢轴时才返回值,所以我们用fixnan()最后返回的枢轴值填补空白。空白指的是ta.pivothigh()没有找到新的枢轴时返回的na值。
l 我们在枢轴出现三个K线后才检测到它们,因为我们在 ta.pivothigh() 调用中的 leftbars 和 rightbars 参数都使用了参数 3。
l 最后一个曲线图绘制的是连续值,但当枢轴值发生变化时,它将曲线图的颜色设置为 na,因此此时曲线图不可见。因此,只有在使用 na 颜色绘制的K线之后的K线上才会出现可见的绘图。
l 蓝点表示检测到新的高点枢轴时,在前一K线和该K线之间不绘制图形。请注意,箭头指示的K线上的枢轴刚刚在实时K线中检测到,即三个K线之后,没有绘制任何曲线图。只有在下一个K线时才会出现绘图,因此在实际枢轴出现四个K线后才会出现绘图。
水平线
Pine Script® 的hline()函数可以绘制水平线(请参阅 "levels"页面)。hline()函数的作用在于它具有plot()函数无法提供的一些线条样式,但它也有一些限制,即它不接受series color,而且它的price参数需要 "input int/float,因此在脚本执行过程中不能改变"。
使用 plot() 绘制水平线有几种不同的方法。下面显示的是一个使用 plot() 绘制水平线的 CCI 指标:
//@version=5
indicator("CCI levels with `plot()`")
plot(ta.cci(close, 20))
plot(0, "Zero", color.gray, 1, plot.style_circles)
plot(bar_index % 2 == 0 ? 100 : na, "100", color.lime, 1, plot.style_linebr)
plot(bar_index % 2 == 0 ? -100 : na, "-100", color.fuchsia, 1, plot.style_linebr)
plot( 200, "200", color.green, 2, trackprice = true, show_last = 1, offset = -99999)
plot(-200, "-200", color.red, 2, trackprice = true, show_last = 1, offset = -99999)
plot( 300, "300", color.new(color.green, 50), 1)
plot(-300, "-300", color.new(color.red, 50), 1)
请注意:
l 零级使用 plot.style_circles 绘制。
l 100 级使用条件值绘制,仅每隔一K线绘制一次。为了防止 na 值被桥接,我们使用 plot.style_linebr 线样式。
l 使用 trackprice = true 绘制 200 级,以绘制出明显的小方块图案,扩展脚本视觉空间的整个宽度。其中的 show_last = 1 只显示最后绘制的值,如果不使用下一个技巧,该值将显示为一条K线线条:偏移 = -99999 将该K线段推远,使其永远不可见。
l 连续绘制 300 水平线,但透明度较低,不那么显眼。
偏移量
偏移参数指定绘制线条时使用的偏移(负值向过去偏移,正值向未来偏移)。例如:
//@version=5
indicator("", "", true)
plot(close, color = color.red, offset = -5)
plot(close, color = color.lime, offset = 5)
从屏幕截图中可以看到,红色系列被左移(因为参数值为负数),而绿色系列被右移(参数值为正数)。
绘图次数限制
每个脚本的最大绘图次数限制为 64。所有 plot*() 调用和 alertcondition() 调用都计入脚本的绘图次数。某些类型的调用在绘图总数中的计算次数超过一次。
如果 plot() 调用的color参数为 "const color"(即在编译时已知),则在总的绘图次数中计入一次,例如:
plot(close, color = color.green)
当他们使用另一种形式(如其中任何一种)时,将在总情节数中计入两个:
plot(close, color = syminfo.mintick > 0.0001 ? color.green : color.red) //→ "simple color"
plot(close, color = input.color(color.purple)) //→ "input color"
plot(close, color = close > open ? color.green : color.red) //→ "series color"
plot(close, color = color.new(color.silver, close > open ? 40 : 0)) //→ "series color"
范围
并非所有数值都能随处绘制。脚本的可视化空间总是受到上下限的限制,而上下限会随着绘制的数值动态调整。RSI 指标将绘制 0 到 100 之间的数值,这就是为什么它通常显示在图表上方或下方的不同窗格或区域中。如果将 RSI 值叠加绘制在图表上,其效果将是扭曲商品的正常价格范围,除非它恰好接近 RSI 的 0 至 100 范围。这显示的是 RSI 信号线和 50 水平的中心线,脚本在单独的窗格中运行:
//@version=5
indicator("RSI")
myRSI = ta.rsi(close, 20)
bullColor = color.from_gradient(myRSI, 50, 80, color.new(color.lime, 70), color.new(color.lime, 0))
bearColor = color.from_gradient(myRSI, 20, 50, color.new(color.red, 0), color.new(color.red, 70))
myRSIColor = myRSI > 50 ? bullColor : bearColor
plot(myRSI, "RSI", myRSIColor, 3)
hline(50)
请注意,我们脚本视觉空间的y轴是根据绘制的数值范围(即RS 值)自动调整大小的。有关脚本中使用的 color.from_gradient()函数的更多信息,请参阅"color"页面。
如果我们在脚本中添加以下一行,尝试在同一空间绘制符号的收盘价:
plot(close)
将发生这样:
该图表以 BTCUSD 为符号,其收盘价在此期间约为 40000。绘制 40000 范围内的数值会使我们绘制的 0 至 100 范围内的 RSI 图变得难以辨认。如果我们将 RSI 指标叠加到图表上,也会出现同样的扭曲图。
合并两个指标
如果计划在一个脚本中合并两个信号,首先要考虑两个信号的范围。例如,在同一个脚本的可视空间中不可能正确绘制RSI和MACD,因为RSI有固定的范围(0至100),而MACD没有,因为它绘制的是根据价格计算的移动平均线。
如果您的两个指标都使用固定范围,您可以移动其中一个指标的值,这样它们就不会重叠。例如,我们可以通过移动其中一个指标来绘制RSI(0至100)和真实强度指标 (TSI)(-100至+100)。在此,我们的策略是压缩并移动TSI值,使其绘制在RSI上:
//@version=5
indicator("RSI and TSI")
myRSI = ta.rsi(close, 20)
bullColor = color.from_gradient(myRSI, 50, 80, color.new(color.lime, 70), color.new(color.lime, 0))
bearColor = color.from_gradient(myRSI, 20, 50, color.new(color.red, 0), color.new(color.red, 70))
myRSIColor = myRSI > 50 ? bullColor : bearColor
plot(myRSI, "RSI", myRSIColor, 3)
hline(100)
hline(50)
hline(0)
// 1. 将 TSI 的范围从 -100/100 压缩到 -50/50。
// 2. 将其上移 150,使其 -50 最小值变为 100。
myTSI = 150 + (100 * ta.tsi(close, 13, 25) / 2)
plot(myTSI, "TSI", color.blue, 2)
plot(ta.ema(myTSI, 13), "TSI EMA", #FF006E)
hline(200)
hline(150)
请注意:·
l 我们使用 hline 添加了两个信号线的位置。·
l 为了使两条信号线在 100 的相同范围内摆动,我们将 TSI 值除以 2,因为它的范围是 200(-100 至 +100)。然后将该值上移 150,使其在 100 和 200 之间摆动,从而使 150 成为中心线。·
l 我们在这里所做的操作是将两个不同标度的指标置于同一视觉空间所需的典型折衷方法,即使它们的值与 MACD 相反,都在一个固定的范围内。
重绘
·
· 简介
· 面向脚本用户
· 面向 Pine Script® 程序员
· 历史计算与实时计算
· 流体数据值
· 重新调用 `request.security()
· o 在较低时间范围内使用 `request.security()
· 使用 `request.security()` 时的未来泄露
· o`varip
· o 工具栏状态插件
· o`timenow
· o 策略
· · 过去的绘图
· · 数据集变化
· o 起始点
· o 修订历史数据
重绘简介
我们将 "重绘"定义为:导致历史计算或绘图与实时计算或绘图表现不同的脚本行为。
重绘行为非常普遍,可由多种因素造成。根据我们的定义,我们估计95%以上的现存指标都存在重绘现象。例如,MACD和RSI等广泛使用的指标就表现出一种形式的重绘,因为它们在历史K线上显示的是一个值,但在实时运行时,它们产生的结果会不断波动,直到实时K线关闭。因此,它们在历史K线和实时K线上的表现是不同的。重绘不一定会使指标在所有情形下都失效,也不会妨碍资深交易者使用它们。例如,谁会因为成交量曲线指标由于实时更新而导致了重新绘制,因此就否定它呢?
我们在本页讨论的不同类型的再绘制可以这样划分:
l 广泛存在且通常可以接受的情况:在实时K线期间重新计算(大多数经典指标,如MACD、RSI,以及社区脚本中的绝大多数指标、使用重绘request.security()调用的脚本等)。使用这些脚本通常不会有什么问题,前提是你了解它们是如何工作的。但是,如果您选择使用这些脚本来发出警报或交易指令,那么您应该知道它们是使用实时值还是确认值生成的,并自行决定脚本的行为是否符合您的要求。
l 误解:在过去的K线上绘图、结果在实时K线中计算却无法在历史K线上进行,重新定位过去的事件(Ichimoku、大多数枢轴脚本、大多数使用calc_on_evey_tick = true的策略、当其值在历史K线上绘制时使用重绘request.security()调用的脚本,因为其行为在实时K线中不会相同、大多数使用varip的脚本、大多数使用timenow的脚本、一些使用barstate.* 变量的脚本)。
l 不可接受:使用未来信息的脚本、在非标准图表上运行的策略、在实时K线内生成警报或订单的脚本。
l 无法避免:数据供应商修改历史返馈,历史K线的起始K线不一致。
如果符合以下条件,前两种类型的重绘完全可以接受的:
1.您知道这种行为。
2.可以接受,或
3.可以规避。
现在大家应该清楚了,并非所有重绘行为本质上都是错误、要不惜一切代价避免的。在很多情况下,重绘指标正是我们所需要的。重要的是要知道什么时候重绘行为是你不能接受的。要避免出现这种情况,您必须准确了解您使用的工具是如何工作的,或者您应该如何设计您构建的工具。如果您要发布脚本,则应将任何可能误导您的重绘行为与脚本的其他限制一并提及。
注意事项
我们将不讨论在非标准图表上使用策略的危险,因为这个问题与重绘无关。请参阅在非标准图表上进行回溯测试: 脚本中的讨论。
l 对于脚本使用者
如果您了解重绘指标的行为方式,并且该行为方式符合您的交易方法要求,那么您完全可以决定使用重绘指标。不要像那些交易新手一样,在已发布的脚本上打上"重绘"的字样,好像脚本不可信。这样做只会暴露你对这一主题的不理解。
"它能重绘吗?"这个问题毫无意义。因此,这个问题无法得到有意义的回答。为什么?因为这个问题需要限定。相反,我们可以问:
l 您是否等待实时K线收盘后才显示入场/退场标记?
l 警报是否等待实时K线结束后才触发?
l 较高时间框架的绘图是否会重新绘制(这意味着它们在实时K线上的绘制方式与在历史K线上的绘制方式不同)?
l 您的脚本是否在过去的K线上绘制(大多数枢轴或之字形脚本都会这样做)?
l 您的策略是否使用 calc_on_every_tick = true?
l 您的指标在实时K线中的显示方式是否与在历史K线中的显示方式相同?
l 您是否使用request.security()调用获取未来信息?
重要的是,你要了解你使用的工具是如何工作的,它们的行为是否符合你的目标,是否需要重新绘制。通过阅读本页,您将了解到重绘是一个复杂的问题。它有许多面孔和许多原因。即使你不使用 Pine Script® 编程,本页也能帮助你了解导致重绘的一系列原因,并希望能与脚本作者进行更有意义的讨论。
l 针对 Pine Script® 程序员
正如我们在上一节所讨论的,并不是所有类型的重绘行为都需要不惜一切代价避免。我们希望本页能帮助您更好地理解这些动态变化,从而为您的交易工具做出更好的设计决策。本页的内容应能帮助您避免犯最常见的编码错误,这些错误会导致重新绘制或误导绘图。
无论您的设计决定是什么,如果您发布了脚本,都应该向交易者解释这些决定,以便他们了解您的脚本是如何运行的。
我们将调查三大类重绘原因:
l ·历史计算与实时计算
l ·过去的绘图
l ·数据集变化
历史计算与实时计算
l 不稳定的数据值
历史数据不包括K线的中间价格变动记录;只有开盘、最高、最低和收盘价(OHLC)。
但是,在实时K线上(工具市场开放时运行的K线),最高价、最低价和收盘价的值并不固定;在实时K线关闭、 HLC 值固定之前,它们的值可能会多次变化。它们是不稳定的。这就导致脚本有时在历史数据和实时数据中的工作方式不同,在K线中只有开盘价不会发生变化。
任何在实时中使用high、low和close等值的脚本都会产生可能无法在历史 K 线上重复的计算结果,因此需要重新绘制。
让我们看看这个简单的脚本。它检测收盘价(在实时 K 线中,对应于交易工具的当前价格)与 EMA 的交叉点:
//@version=5
indicator("Repainting", "", true)
ma = ta.ema(close, 5)
xUp = ta.crossover(close, ma)
xDn = ta.crossunder(close, ma)
plot(ma, "MA", color.black, 2)
bgcolor(xUp ? color.new(color.lime, 80) : xDn ? color.new(color.fuchsia, 80) : na)
请注意:
· 当收盘价交叉点超过 EMA 时,脚本使用 bgcolor() 将背景颜色设置为绿色;当收盘价交叉点低于 EMA 时,背景颜色设置为红色。
· 屏幕快照显示了脚本在 30 秒图表上的实时运行情况。已检测到与 EMA 的交叉点,因此实时K线的背景是绿色的。
· 这里的问题是,没有任何东西能保证这个条件在实时K线结束前一直成立。箭头指向计时器显示实时K线还剩21秒,在此之前任何事情都有可能发生。
· 我们正在见证一个重绘脚本。
为防止这种重绘,必须重写脚本,使其不使用实时K线期间波动的值。这需要使用已过去的K线(通常是前一个K线)的值,或者使用open,因为open在实时中不会变化。
我们可以通过多种方法实现这一点。该方法为我们的交叉点检测添加了一个and barstate.isconfirmed 条件,这就要求脚本在K线的最后一次迭代中执行,即K线收盘且价格得到确认时。这是一种避免重绘的简单方法:
//@version=5
indicator("Repainting", "", true)
ma = ta.ema(close, 5)
xUp = ta.crossover(close, ma) and barstate.isconfirmed
xDn = ta.crossunder(close, ma) and barstate.isconfirmed
plot(ma, "MA", color.black, 2)
bgcolor(xUp ? color.new(color.lime, 80) : xDn ? color.new(color.fuchsia, 80) : na)
下面使用上一K线检测到的交叉点:
indicator("Repainting", "", true)
ma = ta.ema(close, 5)
xUp = ta.crossover(close, ma)[1]
xDn = ta.crossunder(close, ma)[1]
plot(ma, "MA", color.black, 2)
bgcolor(xUp ? color.new(color.lime, 80) : xDn ? color.new(color.fuchsia, 80) : na)
它只使用确认的收盘价和 EMA 值进行计算:
//@version=5
indicator("Repainting", "", true)
ma = ta.ema(close[1], 5)
xUp = ta.crossover(close[1], ma)
xDn = ta.crossunder(close[1], ma)
plot(ma, "MA", color.black, 2)
bgcolor(xUp ? color.new(color.lime, 80) : xDn ? color.new(color.fuchsia, 80) : na)
这会检测实时K线的开盘价与前几个K线的 EMA 值之间的交叉点。请注意,EMA 是使用收盘价计算的,因此会重新绘制。我们必须确保使用确认值来检测交叉点,因此交叉点检测逻辑中的 ma[1]:
//@version=5
indicator("Repainting", "", true)
ma = ta.ema(close, 5)
xUp = ta.crossover(open, ma[1])
xDn = ta.crossunder(open, ma[1])
plot(ma, "MA", color.black, 2)
bgcolor(xUp ? color.new(color.lime, 80) : xDn ? color.new(color.fuchsia, 80) : na)
请注意,所有这些方法都有一个共同点:在防止重绘的同时,它们也会比重绘脚本更晚触发信号。如果想避免重绘,这是不可避免的妥协。鱼与熊掌不可兼得。
l 调用request.security()的重绘
如果使用方法不正确,使用request.security()获取的数据在历史K线和实时K线上会有所不同。重绘request.security()调用将生成无法在实时K线中复制的历史数据和图表。让我们看一个脚本,了解重新绘制和不重新绘制request.security()调用之间的区别:
//@version=5
indicator("Repainting vs non-repainting `request.security()`", "", true)
var BLACK_MEDIUM = color.new(color.black, 50)
var ORANGE_LIGHT = color.new(color.orange, 80)
tfInput = input.timeframe("1")
repaintingClose = request.security(syminfo.tickerid, tfInput, close)
plot(repaintingClose, "Repainting close", BLACK_MEDIUM, 8)
indexHighTF = barstate.isrealtime ? 1 : 0
indexCurrTF = barstate.isrealtime ? 0 : 1
nonRepaintingClose = request.security(syminfo.tickerid, tfInput, close[indexHighTF])[indexCurrTF]
plot(nonRepaintingClose, "Non-repainting close", color.fuchsia, 3)
if ta.change(time(tfInput))
label.new(bar_index, na, "↻", yloc = yloc.abovebar, style = label.style_none, textcolor = color.black, size = size.large)
bgcolor(barstate.isrealtime ? ORANGE_LIGHT : na)
这是运行该脚本几分钟后,在 5 秒图表上的输出结果:
请注意:
l 橙色背景标识实时K线和经历的实时K线。
l 黑色弯曲箭头表示何时出现新的较高时间框架。
l 灰色粗线表示用于初始化 repaintingClose 的再绘制 request.security() 调用。
l 紫红色线条表示用于初始化 nonRepaintingClose 的非重绘 request.security() 调用。
l 在历史K线和实时K线中,重新绘制线的行为完全不同。在历史K线上,它会在完成的K线收盘时显示已完成时间框架的新值。然后保持稳定,直到另一个时间框架完成。问题是,在实时情况下,它是按照当前收盘价显示的,因此会一直移动,并在每个K线上发生变化。
l 相比之下,非重绘紫红色线的行为在历史K线和实时中的表现完全相同。它在较高时间框架完成后的K线上更新,直到另一个较高时间框架完成后的K线上才会移动。这种方法更可靠,不会误导脚本用户。请注意,虽然新的较高时间框架数据在历史K线收盘时出现,但在同一实时K线开盘时也会出现。
该脚本显示了一个nonRepaintingSecurity()函数,可用于实现与上一示例中的非重绘代码相同的功能:
//@version=5
indicator("Non-repainting `nonRepaintingSecurity()`","", true)
tfInput = input.timeframe("1")
nonRepaintingSecurity(sym, tf, src) =>
request.security(sym, tf, src[barstate.isrealtime ? 1 : 0])[barstate.isrealtime ? 0 : 1]
nonRepaintingClose = nonRepaintingSecurity(syminfo.tickerid, "1", close)
plot(nonRepaintingClose, "Non-repainting close", color.fuchsia, 3)
另一种生成非重绘较高时间框架数据的方法是这样的,它在序列上使用 [1] 的offset和lookahead:
nonRepaintingSecurityAlternate(sym, tf, src) =>
request.security(sym, tf, src[1], lookahead = barmerge.lookahead_on)
它将产生与nonRepaintingSecurity()相同的非重绘行为。lookahead = barmerge.lookahead_on和[1] offset的使用是相互依存的。如果删除其中一项,就会影响函数的功能。还要注意的是,在历史K线中,non-RepaintingSecurity()和nonRepaintingSecurityAlternate()值之间偶尔会出现一个K线的差异。
l 在较低的时间框架中使用
有些脚本使用request.security()从比图表时间框架更低的时间框架请求数据。当在较低时间框架下发送专门用于处理intrabars的函数时,这种方法非常有用。当这类用户自定义函数需要检测intrabars的第一个K线时(大多数都需要),该技术只能在历史K线上起作用。这是因为实时intrabars尚未排序。其影响是,此类脚本无法实时重现其在历史K线上的行为。例如,任何生成警报的逻辑都会有缺陷,而且需要不断刷新,将经过的实时K线重新计算为历史K线。
在比图表的时间框架更短的时间框架使用时,如果没有能够区分intrabars的专门函数,request.security()将只会返回图表K线扩张中最后一个 intrabar 的值,这通常没有用处,而且也不会实时重现,因此会导致重绘。
鉴于上述原因,除非您了解在比图表时间框架更低的时间框架内使用 request.security() 的微妙之处,否则最好避免在这些时间框架内使用该函数。质量较高的脚本会有检测此类异常的逻辑,并防止在使用较低时间框架时显示无效的结果。
l `request.security()`-未来泄漏
当lookahead = barmerge.lookahead_on与request.security()一起使用以获取价格而不按[1]偏移序列时,它将在历史K线上返回来自未来的数据,这是危险的。
虽然历史K线会在应该知道的未来价格之前神奇地显示未来价格,但在实时中不可能有lookahead,因为那里的未来是未知的,就像应该知道的那样,所以不存在未来K线。
这就是一个例子:
// 未来泄漏!请勿使用!
//@version=5
indicator("Future leak", "", true)
futureHigh = request.security(syminfo.tickerid, "D", high, lookahead = barmerge.lookahead_on)
plot(futureHigh)
注意较高的时间框架线是如何在发生之前显示时间框架的high值的。解决方法是像前面所示的 nonRepaintingSecurity() 中那样使用函数。
使用这种误导技术的公共脚本将受到审核。
l varip
使用 varip 声明模式的变量脚本会保存跨实时更新的信息,而这些信息无法在只有 OHLC 信息的历史K线上重现。此类脚本在实时中可能很有用,包括生成警报,但其逻辑无法进行回溯测试,其在历史K线上的绘图也无法反映实时中的计算。
l 内置的K线状态变量
使用K线状态的脚本可能会重绘,也可能不会重绘。如在上一节中看到的,使用barstate.isconfirmed其实是避免重绘的一种方法,因为历史K线总是"确认"的。而使用其他K线状态(如barstate.isnew)则会导致重绘。原因是在历史K线中,barstate.isew在K线收盘时为真,而在实时K线中,它在K线开盘时为真。使用其他K线状态变量通常会导致历史K线和实时K线之间出现某种行为差异。
l timenow
timenow内置变量返回当前时间。使用该变量的脚本无法显示一致的历史和实时行为,因此必须重绘。
l 策略中的重绘
使用 calc_on_every_tick = true 的策略在每次实时更新时执行,而在历史K线收盘时运行。它们很可能不会产生相同的订单执行,因此会重新绘制。请注意,发生这种情况时,回测结果也会失效,因为它们不能代表策略的实时行为。
在过去位置绘图
在5个K线之后检测枢轴的脚本通常会回到过去,在实际枢轴上绘制过去5个K线的枢轴水平或数值。这往往会导致那些对历史K线图一无所知的交易者推断,当枢轴在实时行情中出现时,枢轴上也会出现同样的图,而不是在检测到枢轴时。
让我们来看一个脚本,经过枢轴后5个K线才能检测到枢轴,所以将价格放在过去的第5个K线,来显示高枢轴的价格:
//@version=5
indicator("Plotting in the past", "", true)
pHi = ta.pivothigh(5, 5)
if not na(pHi)
label.new(bar_index[5], na, str.tostring(pHi, format.mintick) + "\n��", yloc = yloc.abovebar, style = label.style_none, textcolor = color.black, size = size.normal)
注意:
l 此脚本会重新绘制,因为一条结束的实时K线没有价格可以确定枢轴,可能会在实际枢轴出现5个K线后得到并显示价格。
l 显示效果很好,但可能会产生误导。
在为他人开发脚本时,解决这一问题的最佳方案是在默认情况下不使用偏移绘制,但为脚本用户提供通过输入打开过去绘制的选项,这样他们就必须知道脚本在做什么,例如:
//@version=5
indicator("Plotting in the past", "", true)
plotInThePast = input(false, "Plot in the past")
pHi = ta.pivothigh(5, 5)
if not na(pHi)
label.new(bar_index[plotInThePast ? 5 : 0], na, str.tostring(pHi, format.mintick) + "\n��", yloc = yloc.abovebar, style = label.style_none, textcolor = color.black, size = size.normal)
数据集的变化
l 起点
脚本从图表的第一个历史K线开始执行,然后依次执行每个K线,本手册中关于Pine Script®执行模式的页面对此进行了说明。如果第一条K线发生了变化,那么脚本的计算方式往往就会与数据集在不同时间点开始时的计算方式不同。
以下因素会影响你在图表上看到的K线数量及其起始点:
l · 您持有的账户类型
l · 数据供应商提供的历史数据
l · 决定起点的数据集排列要求
这些是特定于账户的K线限制:
l ·20000 高级计划的历史K线。
l ·10000 专业版和专业版+计划的历史K线。
l ·5000 其他计划的历史K线。
起始点使用以下规则确定,这些规则取决于图表的时间框架:
l ·1, 5, 10, 15, 30 秒:与一天的开始时间一致。
l ·1 - 14 分钟:与一周的开始时间一致。
l ·15 - 29 分钟:与一个月的开始时间一致。
l ·30 - 1439 分钟:与一年的开始时间对齐。
l ·1440分钟及以上:与第一个可用历史数据点对齐。
随着时间的推移,这些因素会导致图表的历史记录从不同的时间点开始。这通常会对脚本计算产生影响,因为早期K线计算结果的变化会波及数据集中的所有其他K线。例如,使用 ta.valuewhen()、ta.barssince() 或 ta.ema() 等函数,结果会随早期历史的变化而变化。
l 历史数据的修订
历史和实时K线使用交易所/经纪商提供的两种不同数据源构建:历史数据和实时数据。当实时K线结束时,交易所/经纪商有时会对K线价格进行通常是很小的调整,然后将其写入历史数据。当图表被刷新或脚本被重新执行时,它们将使用历史数据建立和计算,其中将包含那些通常很小的价格调整(如果有的话)。
历史数据也可能因其他原因(如股票分割)而被修改。
交易时段
简介
在Pine Script®中,交易时段信息有三种不同的使用方式:
1. 包含从开始到结束时间和日期信息的交易时段字符串,可以在函数(如time()和time_close())中使用,以检测K线何时处于特定时间段,并可选择将有效交易时段限制在特定日期。input.session()提供了一种方法,允许脚本用户通过脚本的"输入"选项卡定义交易时段值(更多信息请参阅Session input部分)。
2. 交易时段状态内置变量(如 session.ismarket)可以识别一个K线属于哪个交易时段。
3. 使用request.security()获取数据时,可以选择只从常规交易时段或扩展交易时段返回数据。在这种情况下,常规交易时段和扩展交易时段的定义由交易所确定。它是工具属性的一部分,而不是像第1点中那样由用户定义。常规交易时段和扩展交易时段的概念与图表界面中的"图表设置/符号/交易时段"字段相同。
下文将介绍Pine Script中使用交易时段信息的两种方法。
请注意:
l 并非所有TradingView的用户账户都能访问扩展交易时段信息。
l Pine Script®中没有特殊的"session"类型。相反,交易时段字符串属于"string"类型,但必须符合交易时段字符串语法。
交易时段字符串
l 交易时段字符串规格
与 time() 和 time_close() 一起使用的交易时段字符串必须具有特定格式。其语法如下:
<time_period>:<days>
其中
l <time_period> 使用 "hhmm "格式的时间,其中 "hh "为 24 小时格式,因此 1700 表示 5PM。时间段采用 "hhmm-hhmm "格式,逗号可以分隔多个时间段,以指定离散时间段的组合。
例如,- <days>是一组从1到7的数字,指定交易时段在哪天有效。
1 表示星期天,7 表示星期六。
注意:
默认天数为 1234567 在 Pine Script® v5 中与早期版本不同,早期版本使用的是 23456(工作日)。要使 v5 版本的代码重现以前版本的行为,应明确提及工作日,如 "0930-1700:23456"。
以下是交易时段字符串的示例:
"24x7"
从午夜开始的 7 天 24 小时交易时段。
"0000-0000:1234567"
等同于上一示例。
"0000-0000"
等同于前两个示例,因为默认天数是 1234567。
"0000-0000:23456"
与上例相同,但仅限周一至周五。
"2000-1630:1234567"
通宵交易时段,从 20:00 开始,到次日 16:30 结束。在一周内的所有日子都有效。
"0930-1700:146"
周日(1)、周三(4)和周五(6)9:30 开始、17:00 结束的交易时段。
"1700-1700:23456"
通宵交易时段。周一交易时段周日 17:00 开始,周一 17:00 结束。周一至周五有效。
"1000-1001:26"
每周一(2)和每周五(6)只有一分钟的奇怪交易时段。
"0900-1600,1700-2000"
从 9:00 开始,16:00 至 17:00 中断,一直持续到 20:00。适用于一周中的每一天。
l 使用交易时段字符串
使用交易时段字符串定义的交易时段属性独立于交易所定义的交易时段,后者决定了何时可以交易某一工具。程序员可以完全自由地创建适合自己目的的交易时段定义,这通常是为了检测K线何时属于特定交易时段。在Pine Script® 中,可以通过使用 time()函数的以下两种签名之一来实现这一目的:
time(timeframe, session, timezone) → series int
time(timeframe, session) → series int
在这里,我们使用带有交易时段参数的 time() 在盘中图表上显示市场的开盘最高值和最低值:
//@version=5
indicator("Opening high/low", overlay = true)
sessionInput = input.session("0930-0935")
sessionBegins(sess) =>
t = time("", sess)
timeframe.isintraday and (not barstate.isfirst) and na(t[1]) and not na(t)
var float hi = na
var float lo = na
if sessionBegins(sessionInput)
hi := high
lo := low
plot(lo, "lo", color.fuchsia, 2, plot.style_circles)
plot(hi, "hi", color.lime, 2, plot.style_circles)
请注意:·
l 我们使用交易时段输入允许用户指定他们想要检测的时间。我们只在K线上查找交易时段的开始时间,因此我们在 "0930-0935 "默认值的开始和结束时间之间使用了五分钟的间隔。·
l 我们创建一个 sessionBegins()函数来检测交易时段的开始时间。它的 time("", sess) 调用使用空字符串作为函数的时间框架参数,这意味着它使用图表的时间框架,不管它是什么。当出现以下情况时,函数返回 true:·
n 图表使用盘中时间框架(秒或分钟)。
n 脚本不在图表的第一个K线上,我们用(而不是 barstate.isfirst)来确保这一点。该检查可防止代码总是检测到交易时段从第一K线开始,因为 na(t[1]) 而不是 na(t) 在第一K线总是为真。
n 调用 time() 在前一个K线返回 na,因为它不在交易时段的时间段内,而在当前K线返回的值不是 na,这意味着该K线在交易时段的时间段内。
交易时段状态
通过三个内置变量,可以区分当前K线所属的交易时段类型。它们只对盘中时间框架有用:
l session.ismarket在K线属于常规交易时段时返回 true。
l session.ispremarket 当K线属于正常交易时间之前的扩展交易时段时,返回 true。
l 当K线属于正常交易时间之后的扩展交易时段时,·session.ispostmarket 返回 true。
request.security() 使用交易时段
当您的 TradingView 账户提供对扩展交易时段的访问权限时,您可以通过 "设置/商品/交易时段 "字段选择查看其K线。交易时段有两种类型:
l regular(不包括盘前盘后数据)和
l extended (包含盘前盘后数据)。
使用request.security()函数访问数据的脚本可以返回扩展交易时段数据,也可以不返回。这是一个只获取常规交易时段数据的示例:
//@version=5
indicator("Example 1: Regular Session Data")
regularSessionData = request.security("NASDAQ:AAPL", timeframe.period, close, barmerge.gaps_on)
plot(regularSessionData, style = plot.style_linebr)
如果希望request.security()调用返回扩展交易时段数据,必须先使用ticker.new()函数构建request.security()调用的第一个参数:
//@version=5
indicator("Example 2: Extended Session Data")
t = ticker.new("NASDAQ", "AAPL", session.extended)
extendedSessionData = request.security(t, timeframe.period, close, barmerge.gaps_on)
plot(extendedSessionData, style = plot.style_linebr)
请注意,在脚本绘制的图表中,之前图表的空隙现在已被填满。此外,请注意我们的示例脚本不会在图表上生成背景颜色;这是因为图表设置显示了延长时间。
ticker.new()函数的签名如下:
ticker.new(prefix, ticker, session, adjustment) →simple string
其中:
l prefix 是交易所前缀,如 "NASDAQ"。
l ticker 是符号名称,如 "AAPL"。
l session 可以是 session.extended 或 session.regular。请注意,这不是交易时段字符串。
l adjustment 使用不同的标准调整价格:adjustment.none、adjustment.splits、adjustment.dividends。
我们的第一个示例可以改写为:
//@version=5
indicator("Example 1: Regular Session Data")
t = ticker.new("NASDAQ", "AAPL", session.regular)
regularSessionData = request.security(t, timeframe.period, close, barmerge.gaps_on)
plot(regularSessionData, style = plot.style_linebr)
如果要使用与图表主符号相同的交易时段规格,请省略 ticker.new() 中的第三个参数;它是可选的。如果希望代码明确声明自己的意图,请使用 syminfo.session 内置变量。该变量用于保存图表主符号的交易时段类型:
//@version=5
indicator("Example 1: Regular Session Data")
t = ticker.new("NASDAQ", "AAPL", syminfo.session)
regularSessionData = request.security(t, timeframe.period, close, barmerge.gaps_on)
plot(regularSessionData, style = plot.style_linebr)
策略
简介
Pine Script®策略通过模拟历史和实时数据来执行交易,以方便对交易系统进行回测和前测。策略具有与Pine Script®指标相同的功能,可以下达、修改和取消假想订单,并对结果进行分析。
当脚本使用strategy()函数进行声明时,它将获得对 strategy.* 命名空间的访问权限,可以调用其中的函数和变量来模拟订单并访问基本的策略信息。此外,脚本还将在“策略测试器”选项卡中显示外部信息和模拟结果。
简单策略示例
下面的脚本是一个简单的策略,模拟在两条移动平均线交叉时进入做多或做空头寸:
//@version=5
strategy("test", overlay = true)
//计算两条长度不同的移动平均线。
float fastMA = ta.sma(close, 14)
float slowMA = ta.sma(close, 28)
// 当 "fastMA "上穿"slowMA "时,建立做多仓位。
if ta.crossover(fastMA, slowMA)
strategy.entry("buy", strategy.long)
// 当 "fastMA "下穿 "slowMA "时建立做空头寸.
if ta.crossunder(fastMA, slowMA)
strategy.entry("sell", strategy.short)
// 绘制移动平均线。
plot(fastMA, "Fast MA", color.aqua)
plot(slowMA, "Slow MA", color.orange)
请注意:
l strategy("test", overlay = true)声明脚本是一个名为"test"的策略,在主图表窗格上叠加视图输出。
l strategy.entry()是脚本用来模拟buy和sell订单的命令。当脚本下达订单时,它还会在图表上绘制订单ID和指示方向的箭头。
l 两个plot()函数用两种不同的颜色绘制移动平均线,以提供视觉参考。
在图表中应用策略
要测试策略,请将其应用到图表中。可以使用“指标与策略”对话框中的内置策略,也可以在Pine编辑器中编写自己的策略。点击“Pine编辑器”选项卡中“添加到图表”,将脚本应用到图表中:

编译策略脚本并应用于图表后,它将在主图表窗格中绘制订单标记,并在下面的“策略测试”选项卡中显示模拟性能结果:
默认情况下,应用于非标准图表(Heikin Ashi、Renko、Line Break、Kagi、Point & Figure和Range)的策略结果并不反映实际市场状况。在模拟过程中,策略脚本将使用这些图表中的合成价格,而这些价格往往与实际市场价格不一致,因此会产生不切实际的回测结果。因此,我们强烈建议使用标准图表类型进行策略回测。另外,在Heikin Ashi图表上,用户可以使用实际价格模拟订单,方法是在策略属性中启用“使用标准OHLC填写订单”选项,或在strategy()函数调用中使用fill_orders_on_standard_ohlc = true。
策略测试器
所有使用strategy()函数声明的脚本都可使用策略测试器模块。用户可以从图表下方的"Strategy Tester"(策略测试器)选项卡访问该模块,方便地直观显示其策略并分析假设的性能结果。
l 概览
策略测试器的“概览”选项卡显示了模拟交易序列中的基本性能指标以及净值和亏损曲线,可快速查看策略性能,而无需深入了解细节。本节的图表以初始值为中心的基线图显示策略的净值曲线,以折线图显示买入并持有的净值曲线,以柱子显示亏损曲线。用户可以使用图表下方的选项切换这些曲线图,并将其缩放为绝对值或百分比。
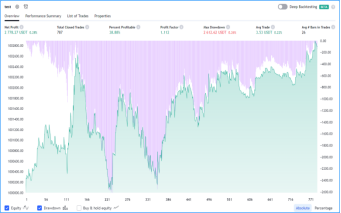
请注意:
l 概览图使用两个刻度;左侧为净值曲线,右侧为亏损曲线。
l 当用户点击这些图上的某一点时,会将主图视图导向交易平仓点。
l 绩效总结
该模块的“绩效总结”选项卡全面概述了策略的性能指标。它显示三列:一列显示全部交易,一列显示所有做多,一列显示所有做空,以便交易者更详细地了解策略的做多、做空和全部模拟交易表现。
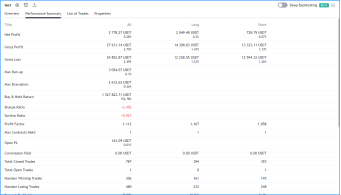
l 交易清单
“交易清单”选项卡提供了策略模拟交易的详细信息,包括执行日期和时间、使用的订单类型(进场或出场)、交易的合约/股票/手数/单位、价格以及一些关键的交易性能指标。
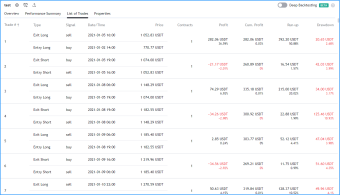
请注意:
l 用户可通过点击该清单中的特定交易,浏览其图表上的特定交易时间。
l 通过点击列表上方的“Trade #”字段,用户可以按从第一笔交易开始的升序或从最后一笔交易开始的降序排列交易。
l 属性
“属性”选项卡提供了有关策略配置及其应用数据集的详细信息。其中包括策略的日期范围、商品信息、脚本设置和策略属性。
l Date Range(日期范围)- 包括模拟交易的日期范围和总的可用回测范围。
l Symbol Info - 包含符号名称和经纪商/交易所、图表的时间框架和类型、刻度大小、图表的点值以及基础货币。
l Strategy Inputs 策略输入 - 概述策略脚本中使用的各种参数和变量,可在脚本设置的"输入"选项卡中查看。
l Strategy Properties策略属性 - 提供交易策略配置概览。其中包括初始资金、基础货币、订单大小、保证金、金字塔、佣金和滑点等基本细节。此外,该部分还强调了对策略计算行为所做的任何修改。
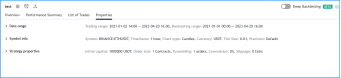
经纪人模拟器
TradingView利用经纪人模拟器来模拟交易策略的性能。与真实交易不同,模拟器严格使用可用的图表价格进行订单模拟。因此,模拟只能在K线收盘后进行历史交易,而且只能在新的价格刻度上进行实时交易。有关该行为的更多信息,请参阅Pine Script®执行模型。
由于模拟器只能使用图表数据,因此会对K线内的价格走势做出假设。它使用K线的open、high和low来推断K线内活动,同时按以下逻辑计算订单成交:
l 如果high比low更接近open,则假定价格在该K线按以下顺序移动:open → high → low → close。
l 如果low比high更接近open,则假定价格在该K线按以下顺序移动: open → low → high → close。
l 经纪商模拟器假定K线内价格之间不存在间隙;在模拟器的"眼中",所有K线内价格均可用于执行订单。
l K 线放大镜
高级账户持有者可以通过strategy()函数的use_bar_magnifier参数或脚本设置的“属性”选项卡中的“使用K线放大镜”输入,超越经纪商模拟器的K线内假设。K线放大镜会检查比图表时间框架更小的时间框架上的数据,以获取K线内价格行为的更细粒度信息,从而在模拟过程中实现更精确的订单成交。
下面的脚本在time穿过orderTime时,在entryPrice处放置buy限价单,在exitPrice处放置sell限价单,并绘制两条水平线来显示订单价格。脚本使用orderColor高亮显示背景,指示策略何时下单:
//@version=5
strategy("Bar Magnifier Demo", overlay = true, use_bar_magnifier = false)
//用于下订单的 UNIX time戳。
int orderTime = timestamp("UTC", 2023, 3, 22, 18)
//@variable 当 `time` 穿过 `orderTime` 时返回 `color.orange`, 否则返回 false。
color orderColor = na
// 进入和退出价格。
float entryPrice = hl2 - (high - low)
float exitPrice = entryPrice + (high - low) * 0.25
// 进入和退出线。
var line entryLine = na
var line exitLine = na
if ta.cross(time, orderTime)
//绘制新的进入线和退出线。
entryLine := line.new(bar_index, entryPrice, bar_index + 1, entryPrice, color = color.green, width = 2)
exitLine := line.new(bar_index, exitPrice, bar_index + 1, exitPrice, color = color.red, width = 2)
// 更新订单高亮颜色。
orderColor := color.new(color.orange, 80)
//在 "进场价格 "和 "退出价格 "下达限价单.
strategy.entry("Buy", strategy.long, limit = entryPrice)
strategy.exit("Exit", "Buy", limit = exitPrice)
// 在仓位开放时更新进入退出线。
else if strategy.position_size > 0.0
entryLine.set_x2(bar_index + 1)
exitLine.set_x2(bar_index + 1)
bgcolor(orderColor)
上图所示,在buy订单成交的K线图上,经纪商模拟器假定,K线内价格从open到high,再从high到low,然后从low到close,这意味着模拟器假定sell订单不能在同一K线上成交。然而,在声明语句中加入use_bar_magnifier = true后,我们看到的情况就不同了:
注释:
脚本可请求的最大K线数量为 100,000。在此限制下,一些历史较长的商品可能无法完全覆盖其图表起始K线,这意味着这些K线上的模拟交易不会受到K线放大镜的影响。
下单和进场
就像在现实交易中一样,Pine策略使用订单来管理头寸。在这里,订单是模拟市场行为的命令,而交易则是订单成交后的结果。因此,要使用Pine进入或退出头寸,用户必须创建带有参数的订单,这些参数指定了订单的行为方式。
让我们编写一个简单的策略脚本,来详细了解订单是如何工作的,以及它们是如何变成交易的:
//@version=5
strategy("My strategy", overlay = true, margin_long = 100, margin_short = 100)
//@function 调用时显示传给 `txt` 的文本。
debugLabel(txt) =>
label.new(
bar_index, high, text = txt, color=color.lime, style = label.style_label_lower_right,
textcolor = color.black, size = size.large
)
longCondition = bar_index % 20 == 0 // 每 20 条K线为真
if (longCondition)
debugLabel("Long entry order created")
strategy.entry("My Long Entry Id", strategy.long)
strategy.close_all()
在此脚本中,我们定义了一个longCondition,只要bar_index能被20整除,即每20个K线为真。该策略在if结构中使用该条件,用strategy.entry()模拟进场单,并用用户定义的debugLabel()函数在入市价格处绘制标签。脚本在全局范围内调用strategy.close_all(),模拟关闭任何未结头寸的市价单。让我们看看将脚本添加到图表后会发生什么:
图表上的蓝色箭头表示进场位置,紫色箭头表示策略平仓点。请注意,这些标签在实际买入点之前,而不是在同一K线出现--这就是执行中的订单。默认情况下,Pine策略会等待下一个可用价格刻度线后再执行订单,因为在同一刻度线上执行订单是不现实的。此外,它们会在每个历史K线收盘时重新计算,这意味着在这种情况下,下一个可执行订单的价位是下一个K线的open价。因此,默认情况下,所有订单都会延迟一个图表K线。
虽然脚本在全局范围内调用了strategy.close_all(),强制在每个K线执行,但如果策略模拟没有未平仓头寸,则函数调用不起任何作用。如果存在未平仓头寸,指令会发出市场指令将其平仓,并在下一个可用tick执行。例如,当做多条件在第20条K线为真时,该策略会在下一个tick(即第21条K线的开盘点)下达进场指令。一旦脚本重新计算了该K线的收盘价,函数会下达平仓指令,在第22个K线开盘时执行。
l 订单类型
Pine Script® 策略允许用户根据自己的特殊需要模拟不同的订单类型。主要有市价单、限价单、止损订单和限价止损订单。
市价单
市价单是最基本的订单类型。无论价格高低,它们都能指挥策略尽快买入或卖出证券。因此,它们总是在下一个可用价格刻度上执行。默认情况下,所有生成订单的 strategy.*()函数都会生成市价单。
当bar_index可被2*cycleLength整除时,以下脚本会模拟做多市价单。否则,当bar_index能被cycleLength除尽时,它将模拟做空市价单,从而产生一个每隔cycleLength 条K线就交替进行做多和做空交易的策略:
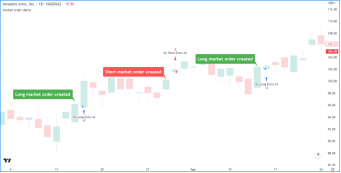
//@version=5
strategy("Market order demo", overlay = true, margin_long = 100, margin_short = 100)
//@variable 做多和做空进场之间的K线间隔数。
cycleLength = input.int(10, "Cycle length")
//@function 调用时显示传给 `txt` 的文本。
debugLabel(txt, lblColor) => label.new(
bar_index, high, text = txt, color = lblColor, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
//@variable 每隔 `2 * cycleLength` 个K线返回 `true`。
longCondition = bar_index % (2 * cycleLength) == 0
//@variable 每隔 `cycleLength` 条K线返回 `true`。
shortCondition = bar_index % cycleLength == 0
// 在`longCondition`上生成带有 `color.green` 标签的做多市价单。
if longCondition
debugLabel("Long market order created", color.green)
strategy.entry("My Long Entry Id", strategy.long)
// 否则,在`shortCondition`上生成带有 `color.red` 标签的市场空单。
else if shortCondition
debugLabel("Short market order created", color.red)
strategy.entry("My Short Entry Id", strategy.short)
限价单
限价单命令策略以特定价格或更好的价格(对于做多订单,价格低于指定价格,对于做空订单,价格高于指定价格)进入头寸。当当前市场价格高于订单命令的限价参数时,订单将成交,而无需等待市场价格达到限价水平。
要在脚本中模拟限价单,可向带有限价参数的下单指令传递价格值。下面的示例在last_bar_index之前100个K线close下方800点位置下达限价单:
//@version=5
strategy("Limit order demo", overlay = true, margin_long = 100, margin_short = 100)
//@function 调用时,显示传入`txt`文本和`price`处的水平线。
debugLabel(price, txt) =>
label.new(
bar_index, price, text = txt, color = color.teal, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
line.new(
bar_index, price, bar_index + 1, price, color = color.teal, extend = extend.right,
style = line.style_dashed
)
// 在`last_bar_index`前100个K线处,生成做多限价单及标签的和线。
if last_bar_index - bar_index == 100
limitPrice = close - syminfo.mintick * 800
debugLabel(limitPrice, "Long Limit order created")
strategy.entry("Long", strategy.long, limit = limitPrice)
请注意,脚本是如何在交易前几个K线段放置标签并开始交易的。只要价格高于限价值,订单就无法成交。一旦市场价格达到限价,策略就会在K线中间执行交易。如果我们将limitPrice设置为高于K线收盘价800点,而不是低于收盘价800点,订单就会立即成交,因为价格已经处于一个较好的价格:
//@version=5
strategy("Limit order demo", overlay = true, margin_long = 100, margin_short = 100)
//@function 调用时,显示传入`txt`文本和`price`处的水平线。
debugLabel(price, txt) =>
label.new(
bar_index, price, text = txt, color = color.teal, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
line.new(
bar_index, price, bar_index + 1, price, color = color.teal, extend = extend.right,
style = line.style_dashed
)
// 在`last_bar_index`前100个K线处,生成做多限价单及标签的和线。
if last_bar_index - bar_index == 100
limitPrice = close + syminfo.mintick * 800
debugLabel(limitPrice, "Long Limit order created")
strategy.entry("Long", strategy.long, limit = limitPrice)
止损单,它控制策略在价格达到指定止损价或更差价格(多单高于指定止损价,空单低于指定止损价)后模拟另一个指令。它们本质上与限价单相反。当目前市场价格比stop(止损)参数价格差时,策略将触发后续订单,而无需等待当前价格达到止损水平。如果下单指令包含limit(限价)参数,则后续订单将是指定值的限价单。否则,它将是一个市价单。
下面的脚本在100条K线前的close上方800点位置下达了止损单。在此示例中,当市场价格在下单后几条K线穿过到止损价时,策略进入做多头寸。请注意,下单时的初始价格优于止损价格。等价限价单会在下一个图表K线成交:
//@version=5
strategy("Stop order demo", overlay = true, margin_long = 100, margin_short = 100)
//@function 调用时显示`txt`的文本,并在图表上显示`price`水平线。
debugLabel(price, txt) =>
label.new(
bar_index, high, text = txt, color = color.teal, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
line.new(bar_index, high, bar_index, price, style = line.style_dotted, color = color.teal)
line.new(
bar_index, price, bar_index + 1, price, color = color.teal, extend = extend.right,
style = line.style_dashed
)
// 在`last_bar_index`前100个K线处,生成做多止损单及标签的和线。
if last_bar_index - bar_index == 100
stopPrice = close + syminfo.mintick * 800
debugLabel(stopPrice, "Long Stop order created")
strategy.entry("Long", strategy.long, stop = stopPrice)
同时使用限价和止损参数的下单指令会产生止损限价单。这种下单类型等待价格突破止损线,然后以指定的限制价格下设置限价单。
让我们修改之前的脚本,模拟并可视化限价止损单。在这个例子中,我们使用100条K线前的最低价作为进场指令中的限价。该脚本还会显示一个标签和价格线,以指示策略何时突破止损价,即策略何时激活限价单。请注意,市场价格最初达到限价水平,但策略并没有模拟交易,因为价格必须突破止损价,才能在限定价格处挂起限价单:
//@version=5
strategy("Stop-Limit order demo", overlay = true, margin_long = 100, margin_short = 100)
//@function 显示`txt`文本,在图表上显示`price`水平线。
debugLabel(price, txt, lblColor, lineWidth = 1) =>
label.new(
bar_index, high, text = txt, color = lblColor, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
line.new(bar_index, close, bar_index, price, style = line.style_dotted, color = lblColor, width = lineWidth)
line.new(
bar_index, price, bar_index + 1, price, color = lblColor, extend = extend.right,
style = line.style_dashed, width = lineWidth
)
var float stopPrice = na
var float limitPrice = na
// 在前100个K线处,生成做多限价止损单及标签的和水平线。
if last_bar_index - bar_index == 100
stopPrice := close + syminfo.mintick * 800
limitPrice := low
debugLabel(limitPrice, "", color.gray)
debugLabel(stopPrice, "Long Stop-Limit order created", color.teal)
strategy.entry("Long", strategy.long, stop = stopPrice, limit = limitPrice)
// 一旦策略激活限价单,画线并标注。
if high >= stopPrice
debugLabel(limitPrice, "Limit order activated", color.green, 2)
stopPrice := na
l 下单指令
Pine Script® 策略具有多种模拟下单的功能,即下单指令。每条指令都有其独特的作用和行为方式。
strategy.entry()
该命令模拟进场单。默认情况下,策略在调用此函数时下达市价单,但也可以利用stop和limit参数创建止损、限价和限价止损单。
为了简化进场操作,strategy.entry()具有几种独特的行为。其中一种行为是,该命令可以在不调用其他函数的情况下逆转未结市场头寸。当使用strategy.entry()下达的订单成交时,该函数会自动计算该策略平仓所需的金额,并默认以相反方向交易qty个合约/股票/手/单位。例如,如果一个策略在strategy.long方向有一个15股的未平仓头寸,并调用strategy.entry()在strategy.short方向下了一个市价单,那么该策略下单的交易量就是15股加上新空单的数量。
下面的示例演示了一个只使用strategy.entry()调用来下进场单的策略。它每隔100个K线创建一个数量为15股的做多市价单,每隔25个K线创建一个数量为5股的做空市价单。脚本会在出现相应的买入条件和卖出条件时,高亮显示蓝色和红色背景:
//@version=5
strategy("Entry demo", "test", overlay = true)
//@variable 在每 100 个K线时为 `true`。
buyCondition = bar_index % 100 == 0
//除可被 100 整除的K线外,每第 25 个K线都是 `true`。
sellCondition = bar_index % 25 == 0 and not buyCondition
if buyCondition
strategy.entry("buy", strategy.long, qty = 15)
if sellCondition
strategy.entry("sell", strategy.short, qty = 5)
bgcolor(buyCondition ? color.new(color.blue, 90) : na)
bgcolor(sellCondition ? color.new(color.red, 90) : na)
如上图所示,订单标记显示该策略在每个订单成交时交易了20股,而不是15股和5股。因为strategy.entry()会自动反转仓位,除非通过strategy.risk.allow_entry_in()函数另行指定。因此当它改变方向时,会将未平仓头寸大小(做多头寸为15)添加到新订单大小(做空头寸为5)中,从而产生20股的交易量。
请注意,在上述示例中,虽然卖出条件在另一个买入条件之前出现了三次,但该策略只在第一次出现时下"卖出"订单。strategy.entry()命令的另一个独特行为是,它受脚本的分层设置影响。Pyramiding指定了策略在同一方向上可以执行的连续订单数量。其默认值为1,这意味着该策略只允许在同一方向上填写一个连续订单。可以通过strategy()函数调用的pyramiding参数或脚本设置“属性”选项卡中的"Pyramiding"输入设置策略的pyramiding值。
如果我们在之前脚本的声明语句中添加pyramiding = 3,那么该策略将最多允许三次同方向的连续交易,这意味着它可以在每次出现sellCondition时模拟新的市价单:
strategy.order()
该命令模拟基本订单。与大多数包含内部逻辑简化与策略交互的下单命令不同,strategy.order()使用指定的参数,不考虑大多数额外的策略设置。strategy.order()下达的订单可以开立新仓位、修改或关闭现有仓位。
以下脚本使用strategy.order()调用来创建和修改进场。该策略模拟每100个K线15个单位的市场多单,然后每25个K线5个单位的三个空单。脚本突出显示背景的蓝色和红色,以指示该策略何时模拟buy和sell订单:
//@version=5
strategy("Order demo", "test", overlay = true)
//@variable Is `true` on every 100th bar.
buyCond = bar_index % 100 == 0
//@variable 除可被100 除的K线外,每25个K线均为true.
sellCond = bar_index % 25 == 0 and not buyCond
if buyCond // 输入 15 个单位的做多头寸.
strategy.order("buy", strategy.long, qty = 15)
if sellCond // 从做多头寸中退出 5 个单位.
strategy.order("sell", strategy.short, qty = 5)
bgcolor(buyCond ? color.new(color.blue, 90) : na)
bgcolor(sellCond ? color.new(color.red, 90) : na)
与strategy.entry()不同,strategy.order()不会自动反转头寸,因此该策略永远不会模拟做空头寸。使用该命令时,市场头寸是当前市场头寸与已成交订单数量的净和。策略执行15个单位的buy指令后,会执行三个sell指令,每个指令会将未平仓头寸减少5个单位,即15-5*3=0。同样的脚本在使用strategy.entry()命令时会有不同的表现,如上节所示的示例。
strategy.exit()
该命令模拟退场指令。它允许策略退出市场头寸,或通过loss, stop, profit, limit和trail_*参数,以止损、止盈和跟踪止损单的形式构建多种退出。
strategy.exit()命令最基本的用途是创建价格水位,水位上策略将因亏损过多(止损)、盈利足够(止盈)或两者(两侧)而退出头寸。
该命令的止损和止盈与两个参数相关。loss和profit参数止损和止盈与进场单价格相差多少的点,而stop和limit参数是止损和止盈的价格。函数调用中的绝对参数会替代相对参数:如果strategy.exit()调用包含profit和limit参数,命令将优先考虑limit(止损)值,而忽略profit(止盈)值。同样,如果函数调用包含stop和loss参数,则只考虑stop值。
注:尽管strategy.entry()和strategy.order()命令中的参数名称相同,但在strategy.exit()中,limit和stop参数的作用却不同。在strategy.entry()命令中使用limit和stop将创建一个限价止损单,在突破止损后打开限价单。而strategy.order()命令将分别创建一个限价单和一个止损单,从未结头寸中退出。
所有来自strategy.exit()并带有from_entry参数的退场指令都与相应的进场指令ID绑定;当没有未平仓头寸或与from_entry ID相关的有效进场指令时,策略无法模拟退场指令。
以下策略通过strategy.entry()下达"buy"进场单,并通过strategy.exit()命令每100个K线下达止损和止盈订单。注意脚本调用了两次strategy.exit()。exit1命令引用了"buy1"进场单,而"exit2"则引用了"buy"订单。由于"exit1"引用的订单ID并不存在,因此该策略只会模拟来自"exit2"的退场订单:
//@version=5
strategy("Exit demo", "test", overlay = true)
//@variable 在每 100 个K线时为 `true`。
buyCondition = bar_index % 100 == 0
//@variable 退出命令的止损价格。
var float stopLoss = na
//@variable 退出命令的止盈价格。
var float takeProfit = na
// 根据 `buyCondition`下订单。
if buyCondition
if strategy.position_size == 0.0
stopLoss := close * 0.99
takeProfit := close * 1.01
strategy.entry("buy", strategy.long)
strategy.exit("exit1", "buy1", stop = stopLoss, limit = takeProfit) //什么也做不了。"buy1 "订单不存在。
strategy.exit("exit2", "buy", stop = stopLoss, limit = takeProfit)
// 当价格触及"stopLoss"和"takeProfit"中的任何一个时,即策略模拟退出时,将"stopLoss"和"takeProfit"设置为"na"。
if low <= stopLoss or high >= takeProfit
stopLoss := na
takeProfit := na
plot(stopLoss, "SL", color.red, style = plot.style_circles)
plot(takeProfit,"TP", color.green, style = plot.style_circles)
l 每个退场指令的限价单和止损单并不一定以指定价格成交。策略可以以更好的价格执行止盈订单,也可以以更差的价格执行止损订单,这取决于经纪商模拟器的可用值范围。
如果用户没有在strategy.exit()中提供from_entry参数,函数将为每个未平仓头寸创建退场订单。
在下例中,策略创建了"buy1"和"buy2"进场单,并每100个K线调用strategy.exit(),而不提供from_entry参数。从图表上的订单标记可以看出,一旦市场价格达到stopLoss或takeProfit值,该策略就会为"buy1"和"buy2"进场填写退场订单:
//@version=5
strategy("Exit all", "test", overlay = true, pyramiding = 2)
//@variable 在每 100 个K线时为 `true`。
buyCondition = bar_index % 100 == 0
//@variable 退出命令的止损价格。
var float stopLoss = na
//@variable 退出命令的止盈价格。
var float takeProfit = na
// 根据条件`buyCondition`下订单。
if buyCondition
if strategy.position_size == 0.0
stopLoss := close * 0.99
takeProfit := close * 1.01
strategy.entry("buy1", strategy.long)
strategy.entry("buy2", strategy.long)
strategy.exit("exit", stop = stopLoss, limit = takeProfit) // --下单退出所有未结头寸。
// 当价格触及"stopLoss"和"takeProfit"时,即当策略模拟退出时,将"stopLoss"和"takeProfit"设置为 "na":》停止画线
if low <= stopLoss or high >= takeProfit
stopLoss := na
takeProfit := na
plot(stopLoss, "SL", color.red, style = plot.style_circles)
plot(takeProfit,"TP", color.green, style = plot.style_circles)
一个策略可以多次从同一入口ID退出,这有利于形成多级退出策略。执行多个退场指令时,每个订单的数量必须是交易数量的一部分,其总和不得超过未平仓头寸。如果函数的qty值小于当前市场头寸的大小,策略将模拟部分退出。如果qty值超过敞口头寸数量,则会减少订单,因为它无法填补比敞口头寸更多的合约/股票/手/单位。
在下面的示例中,我们修改了之前的"Exit demo"脚本,以模拟每次进场的两个止损和止盈订单。该策略下达的buy订单数量为2份,"exit1"止损和止盈订单数量为1份,"exit2"止损和止盈订单数量为3份:
//@version=5
strategy("Multiple exit", "test", overlay = true)
//@variable 在每 100 个K线时为 `true`。
buyCondition = bar_index % 100 == 0
//@variable "exit1" 命令的止损价格。
var float stopLoss1 = na
//@variable "exit2" 命令的止损价格。
var float stopLoss2 = na
//@variable "exit1" 命令的止盈价格。
var float takeProfit1 = na
//@variable "exit2" 命令的止盈价格。
var float takeProfit2 = na
// 根据 `buyCondition`下订单。
if buyCondition
if strategy.position_size == 0.0
stopLoss1 := close * 0.99
stopLoss2 := close * 0.98
takeProfit1 := close * 1.01
takeProfit2 := close * 1.02
strategy.entry("buy", strategy.long, qty = 2)
strategy.exit("exit1", "buy", stop = stopLoss1, limit = takeProfit1, qty = 1)
strategy.exit("exit2", "buy", stop = stopLoss2, limit = takeProfit2, qty = 3)
// 当价格触及"stopLoss1"和"takeProfit1"中的任何一个时设为"na"
if low <= stopLoss1 or high >= takeProfit1
stopLoss1 := na
takeProfit1 := na
// 当价格触及"stopLoss2"和"takeProfit2"中的任何一个时设为"na"
if low <= stopLoss2 or high >= takeProfit2
stopLoss2 := na
takeProfit2 := na
plot(stopLoss1, "SL1", color.red, style = plot.style_circles)
plot(stopLoss2, "SL2", color.red, style = plot.style_circles)
plot(takeProfit1, "TP1", color.green, style = plot.style_circles)
plot(takeProfit2, "TP2", color.green, style = plot.style_circles)
从图表上的订单标记可以看出,尽管指定的数量值超过了交易量,但该策略还是执行了"exit2"订单。脚本没有使用这个数量,而是缩小了订单的大小,使其与剩余头寸相匹配。
请注意:
l 调用strategy.exit()生成的所有订单都属于同一个strategy.oca.reduce组,这意味着当其中一个订单成交时,该策略会减少所有其他订单,以匹配未结头寸。
需要注意的是,由该命令生成的订单会保留部分未平仓头寸供退出。strategy.exit()不能下单退出已被其他退出命令保留的部分头寸。
下面的脚本模拟了100个K线前20股的市价buy单,"limit止盈"和"stop止损"订单分别为19股和20股。从图表中我们可以看到,该策略首先执行了"stop"订单。但是,交易量只有一股。由于脚本首先下达了"limit"订单,因此该策略保留了其qty数量(19股)以关闭未结头寸,"stop"订单只关闭了1股:
//@version=5
strategy("Reserved exit demo","test",overlay = true)
//@变量 退场订单止损价格。
var float stop = na
//@ 变量 退场订单止盈价格
var float limit = na
//@variable last_bar_index前第100 K线为 `true`。
longCondition = last_bar_index - bar_index == 100
if longCondition
stop := close * 0.99
limit := close * 1.01 //limit未执行,保留19
strategy.entry("buy", strategy.long, 20)
strategy.exit("limit", limit = limit, qty = 19)
strategy.exit("stop", stop = stop, qty = 20)
// stop执行1,因为limit保留了19
bool showPlot = strategy.position_size != 0
plot(showPlot ? stop : na, "Stop", color.red, 2, plot.style_linebr)
plot(showPlot ? limit : na, "Limit 1", color.green, 2, plot.style_linebr)
strategy.exit()函数的另一个主要特点是,它可以创建跟踪止损,即每当价格向有利方向移动到一个更好的值时,就在市场价格后方追踪一定数量的止损订单。这些订单由两个部分组成:激活水平和追踪偏移。激活水平是市场价格必须突破才能激活跟踪止损计算的值,通过trail_points参数以刻度表示,或通过trail_price参数以价格值表示。如果退出调用同时包含这两个参数,则以trail_price参数优先。跟踪偏移量是止损跟随市场价格的距离,通过trail_offset参数以刻度表示。要让strategy.exit()创建并激活跟踪止损,函数调用必须包含trail_offset和trail_price或trail_points参数。
下面的示例展示了跟踪止损的操作,并将其行为可视化。该策略在图表上最后一个K线之前100个K线模拟做多进场指令,然后在下一个K线模拟移动止损。该脚本有两个输入:一个控制激活水平的偏移量(即激活止损所需的超出市场价格的点数),另一个控制跟踪的偏移量(即当市价向预期方向移动到一个更好的值时,跟随市价的价格差)。
图表上的绿色虚线表示市场价格必须突破才能触发跟踪止损单。价格突破后,脚本会绘制一条蓝线来表示移动止损。当价格上涨到一个新的高值时,这对策略是有利的,因为这意味着头寸的价值在增加,止损也会随之上升,与当前价格保持一个trailingStopOffset ticks的距离。当价格下跌或没有达到新的高点时,止损值保持不变。最终,价格穿过低于止损点,触发离场:
//@version=5
strategy("Trailing stop order demo", overlay = true, margin_long = 100, margin_short = 100)
//@variable 偏移量,用于确定激活水平在市场价格上方多远的位置(以 ticks 为单位)。
activationLevelOffset = input(1000, "Activation Level Offset (in ticks)")
//@variable 偏移量,用于确定跟踪止损价在high下方多远的位置(以 ticks 为单位)
trailingStopOffset = input(2000, "Trailing Stop Offset (in ticks)")
//@function 调用时显示传入`txt`的文本,并在图表上显示`price`水平线。
debugLabel(price, txt, lblColor, hasLine = false) =>
label.new(
bar_index, price, text = txt, color = lblColor, textcolor = color.white,
style = label.style_label_lower_right, size = size.large
)
if hasLine
line.new(
bar_index, price, bar_index + 1, price, color = lblColor, extend = extend.right,
style = line.style_dashed
)
//@variable 跟踪止损的激活水平价格。
var float trailPriceActivationLevel = na
//@variable 跟踪止损价格。
var float trailingStop = na
//@variable 计算跟踪止损在激活时的值。
theoreticalStopPrice = high - trailingStopOffset * syminfo.mintick
// 生成多头市价单,在最后一个K线之前100个K线进场。
if last_bar_index - bar_index == 100
strategy.entry("Long", strategy.long)
// 在最后一个K线之前的 99个K线产生跟踪止损。
if last_bar_index - bar_index == 99
trailPriceActivationLevel := open + syminfo.mintick * activationLevelOffset
strategy.exit(
"Trailing Stop", from_entry = "Long",
trail_price = trailPriceActivationLevel,
trail_offset = trailingStopOffset
)
debugLabel(trailPriceActivationLevel, "Trailing Stop Activation Level", color.green, true)
// 跟踪止损机制的可视化操作。
// 如果有未结交易,检查是否已达到激活水平。
// 如果已经达到,则通过将其赋值给变量来跟踪移动止损。
if strategy.opentrades == 1
if na(trailingStop) and high > trailPriceActivationLevel
debugLabel(trailPriceActivationLevel, "Activation level crossed", color.green)
trailingStop := theoreticalStopPrice
debugLabel(trailingStop, "Trailing Stop Activated", color.blue)
else if theoreticalStopPrice > trailingStop
trailingStop := theoreticalStopPrice
// 可视化跟踪止损点的移动。
plot(trailingStop, "Trailing Stop")
strategy.close()和strategy.close_all()
这些命令使用市价单模拟退出头寸。这些函数在调用时关闭交易,而不是以特定价格关闭。
下面的示例演示了一个简单的策略,通过strategy.entry()每50个K线下一个buy订单,25个K线后使用strategy.close()使用市价单平仓:
//@version=5
strategy("Close demo", "test", overlay = true)
//@variable 在每第 50 个K线时为 `true`。
buyCond = bar_index % 50 == 0
//@variable 每25个K线为`true`,除了能被50整除的K线。sellCond = bar_index % 25 == 0 and not buyCond
if buyCond
strategy.entry("buy", strategy.long)
if sellCond
strategy.close("buy")
bgcolor(buyCond ? color.new(color.blue, 90) : na)
bgcolor(sellCond ? color.new(color.red, 90) : na)
与大多数其他下单命令不同,strategy.close() 的 id参数引用的是要退出的现有进场ID。如果指定的 ID 不存在,该命令将不会执行订单。如果头寸是由具有相同 ID 的多个进场形成的,该命令将同时退出所有进场。
为了演示,下面的脚本每25 个K线下一个buy订单。该脚本每100 个K线段关闭一次所有buy进场。我们在strategy()声明语句中加入了pyramiding = 3,以允许策略在同一方向上模拟多达三个订单:
//@version=5
strategy("Multiple close demo", "test", overlay = true, pyramiding = 3)
//@variable 每 100 个K线时为 `true`。
sellCond = bar_index % 100 == 0
//除可被 100 整除的K线外,每25 个K线都是 `true`。
buyCond = bar_index % 25 == 0 and not sellCond
if buyCond
strategy.entry("buy", strategy.long)
if sellCond
strategy.close("buy")
bgcolor(buyCond ? color.new(color.blue, 90) : na)
bgcolor(sellCond ? color.new(color.red, 90) : na)
如果脚本中有多个ID不同的进场指令,strategy.close_all()命令就会派上用场,因为它会关闭所有进场指令,而不管它们的ID如何。
下面脚本根据未平仓交易的数量依次放置"A"、"B"和"C"进场指令,然后用一个市价指令平掉所有进场:
//@version=5
strategy("Close multiple ID demo", "test", overlay = true, pyramiding = 3)
switch strategy.opentrades
0 => strategy.entry("A", strategy.long)
1 => strategy.entry("B", strategy.long)
2 => strategy.entry("C", strategy.long)
3 => strategy.close_all()
strategy.cancel()和strategy.cancel_all()
这些命令允许策略取消挂单,即由strategy.exit() strategy.order()或strategy.entry()(当它们使用限价或止损参数时)生成的挂单。
下面的策略模拟了比100个K线前的close低500点的buy限价单,然后在下一个K线取消订单。脚本在limitPrice处画了一条水平线,并将背景色染成绿色和橙色,分别表示限价单何时下达、何时取消。我们可以看到,一旦市场价格穿过限价,就不会发生任何事情,因为策略已经取消了订单:
//@version=5
strategy("Cancel demo", "test", overlay = true)
//在buy订单的 "限价 "处画一条水平线。
var line limitLine = na
//@variable 当策略发出buy订单时,返回 `color.green`;当取消订单时,返回 `color.orange`。
color bgColor = na
if last_bar_index - bar_index == 100
float limitPrice = close - syminfo.mintick * 500
strategy.entry("buy", strategy.long, limit = limitPrice)
limitLine := line.new(bar_index, limitPrice, b ar_index + 1, limitPrice, extend = extend.right)
bgColor := color.new(color.green, 50)
if last_bar_index - bar_index == 99
strategy.cancel("buy")
bgColor := color.new(color.orange, 50)
bgcolor(bgColor)
与strategy.close()一样,strategy.cancel()的 id参数指的是现有进场的ID。如果 id参数引用的ID不存在,该命令将不起作用。当有多个具有相同ID的挂单时,该命令将一次性取消所有挂单。
在本例中,我们修改了之前的脚本,在第100条K线处开始的连续三条K线上下达buy限价单。该策略会在bar_index为97的最近那条K线上取消所有订单,导致价格与任何一条限价水平线交叉时,该策略都不起作用:
//@version=5
strategy("Multiple cancel demo", "test", overlay = t rue, pyramiding = 3)
//在buy订单的 "限价 "处画一条水平线。
var line limitLine = na
//@variable 当策略发出buy订单时,返回 `color.green`;当取消订单时,返回 `color.orange`。
color bgColor = na
if last_bar_index - bar_index <= 100 and last_bar_index - bar_index >= 98
float limitPrice = close - syminfo.mintick * 500
strategy.entry("buy",strategy.long, limit =limitPrice)
limitLine := line.new(bar_index, limitPrice, bar _index + 1, limitPrice, extend = extend.right)
bgColor := color.new(color.green, 50)
if last_bar_index - bar_index == 97
strategy.cancel("buy")
bgColor := color.new(color.orange, 50)
bgcolor(bgColor)
l 我们在脚本的声明语句中添加了pyramiding = 3,以允许三个strategy.entry()订单成交。另外,脚本也可以使用strategy.order()实现相同的输出,因为它对pyramiding设置并不敏感。
strategy.cancel()和strategy.cancel_all()都不能取消市价单,因为策略会在下一个交易日立即执行这些市价单,策略不能在订单成交后取消订单。要关闭未结头寸,用strategy.close()或strategy.close_all()。
此示例模拟了100个K线前的buy市价单,然后尝试在下一个K线取消所有挂单。由于策略已经成交了buy订单,因此strategy.cancel_all()命令在这种情况下不起作用,因为没有挂单要取消:
//@version=5
strategy("Cancel market demo", "test", overlay = true)
//@variable 策略下了buy订单时“color.green”;取消//订单时, 返回color.orange color bgColor = na
if last_bar_index - bar_index == 100
strategy.entry("buy", strategy.long)
bgColor := color.new(color.green, 50)
if last_bar_index - bar_index == 99
strategy.cancel_all()
bgColor := color.new(color.orange, 50)
bgcolor(bgColor)
头寸大小
Pine Script®策略有两种设置模拟交易头寸大小的方法:
l 使用strategy()函数中的default_qty_type和default_qty_value参数为所有订单设置默认的固定数量类型和大小,同时在脚本设置的“属性”选项卡中设置默认值。
l 在调用strategy.entry()时指定qty数。当用户向函数提供该参数时,脚本会忽略策略的默认数量值和类型。
下面的示例模拟了当low等于lowest值时的买入longAmount大小的多单,当high等于highest值时的卖出shortAmount大小的空单:
//@version=5
strategy("Buy low, sell high", overlay = true, default_qty_type = strategy.cash, default_qty_value=5000)
int length = input.int(20, "Length")
float longAmount = input.float(4.0, "Long Amount")
float shortAmount = input.float(2.0, "Short Amount")
float highest = ta.highest(length)
float lowest = ta.lowest(length)
switch
low == lowest => strategy.entry("Buy", strategy.long, longAmount)
high == highest => strategy.entry("Sell", strategy.short, shortAmount)
请注意,在上述示例中,虽然我们在声明语句中指定了default_qty_type和default_qty_value参数,但脚本并没有在模拟订单中使用这些默认值。取而代之的是,它以longAmount和shortAmount单位来确定它们的大小。如果我们希望脚本使用默认类型和值,就必须删除strategy.entry()调用中的qty指定:
//@version=5
strategy("Buy low, sell high", overlay = true, default_qty_type = strategy.cash, default_qty_value = 5000)
int length = input.int(20, "Length")
float highest = ta.highest(length)
float lowest = ta.lowest(length)
switch
low == lowest => strategy.entry("Buy", strategy.long)
high == highest => strategy.entry("Sell", strategy.short)
关闭市场头寸
虽然可以模拟退出一个特定进场单(在策略测试模块的“交易清单”选项卡中显示),但所有订单都根据FIFO(先进先出)的规则相连着的。如果用户没有指定strategy.exit()调用的from_entry参数,则该策略将从打开市场头寸的第一个进场单开始退出该头寸。
下面的示例依次模拟了两个订单: 以最后第100条K线的市场价格“buy1”,一旦头寸规模与"buy1"的规模相匹配,则“buy2”。只有当仓位大小为15个单位时,该策略才会下退出单。脚本没有为strategy.exit()命令提供from_entry参数,因此每次调用该函数时,策略会从第一个开始,为所有未结头寸下达退场指令。同时在单独的窗格中绘制positionSize,作为视觉参考:

//@version=5
strategy("Exit Demo", pyramiding = 2)
float positionSize = strategy.position_size
if positionSize == 0 and last_bar_index - bar_index <= 100
strategy.entry("Buy1", strategy.long, 5)
else if positionSize == 5
strategy.entry("Buy2", strategy.long, 10)
else if positionSize == 15
strategy.exit("bracket", loss = 10, profit = 10)
plot(positionSize == 0 ? na : positionSize, "Positio n Size", color.lime, 4, plot.style_histogram)
请注意:
l 我们在脚本的声明语句中加入了pyramiding = 2,使其能够模拟两个同方向的连续订单。
假设我们想在退出“Buy1”之前退出“Buy2”。让我们看看,如果我们指示策略在"Buy1"和"Buy2"同时成交时,先平仓"Buy2",会发生什么情况:
//@version=5
strategy("Exit Demo", pyramiding = 2)
float positionSize = strategy.position_size
if positionSize == 0 and last_bar_index - bar_index <= 100
strategy.entry("Buy1", strategy.long, 5)
else if positionSize == 5
strategy.entry("Buy2", strategy.long, 10)
else if positionSize == 15
strategy.close("Buy2")
strategy.exit("bracket", "Buy1", loss = 10, profit = 10)
plot(positionSize == 0 ? na : positionSize, "Position Size", color.lime, 4, plot.style_histogram)
我们可以在策略测试器的“交易清单”选项卡中看到,由于经纪商模拟器默认遵循先进先出规则,因此它没有使用strategy.close()关闭"Buy2"仓位,而是先关闭"Buy1"的数量,即平仓订单数量的一半,然后关闭"Buy2"仓位的一半。用户可以通过在strategy()函数中指定close_entries_rule = "ANY"来改变这种行为。
OCA 组
One-Cancels-All (OCA) 组允许策略在执行下单命令(包括strategy.entry()和strategy.order())时,根据用户在函数调用中提供的oca_type参数,完全或部分取消具有相同oca_name的其他订单。
strategy.oca.cancel
strategy.oca.cancel OCA类型会在该组订单成交或部分成交时取消所有具有相同oca_name的订单。
例如,以下策略在ma1与ma2交叉时执行订单。当strategy.position_size为0时,它会分别用K线的high和low做多单和空单的止损下单进场;不为0时,调用strategy.close_all()下市价单平掉所有未结头寸。根据价格走势,该策略可能会在发出平仓指令前执行两个指令;另外,如果经纪商模拟器的K线内假设支持,两个进场单可能会在同一K线上成交。在这两种情况下,strategy.close_all()命令不起任何作用,因为脚本在执行两个订单后才能调用该操作:
//@version=5
strategy("OCA Cancel Demo", overlay=true)
float ma1 = ta.sma(close, 5)
float ma2 = ta.sma(close, 9)
if ta.cross(ma1, ma2)
if strategy.position_size == 0
strategy.order("Long", strategy.long, stop = high)
strategy.order("Short", strategy.short, stop = low)
else
strategy.close_all()
plot(ma1, "Fast MA", color.aqua)
plot(ma2, "Slow MA", color.orange)
为了消除策略在平仓指令之前就执行多单和空单的情况,我们可以指示策略在执行另一个指令时取消一个指令。在本例中,我们将两个strategy.order()命令的oca_name都设置为"Entry",将它们的oca_type都设置为strategy.oca.cancel:
//@version=5
strategy("OCA Cancel Demo", overlay=true)
float ma1 = ta.sma(close, 5)
float ma2 = ta.sma(close, 9)
if ta.cross(ma1, ma2)
if strategy.position_size == 0
strategy.order("Long", strategy.long, stop = high, oca_name = "Entry", oca_type = strategy.oca.cancel)
strategy.order("Short", strategy.short, stop = low, oca_name = "Entry", oca_type = strategy.oca.cancel)
else
strategy.close_all()
plot(ma1, "Fast MA", color.aqua)
plot(ma2, "Slow MA", color.orange)
strategy.oca.reduce
strategy.oca.reduce OCA 类型不会取消订单。而是在每次新成交时,它会按平仓合约/股/手/单位的数量减少具有相同oca_name的订单的大小,这对出场策略特别有用。
下面的示例演示了一个做多退出策略的尝试,该策略会为每个新进入的订单生成一个止损订单和两个止盈单。在两条移动平均线交叉时,使用strategy.entry()模拟了一个"做多"进场单,qty为6个单位,然后使用strategy.order()在stop、limit1和limit2上分别模拟了6、3和3个单位的止损/止盈订单。
将该策略添加到图表后,我们发现它并没有按预期运行。这个脚本的问题在于,与strategy.exit()不同,strategy.order()默认不属于OCA组。由于我们没有明确地将订单分配给OCA组,因此该策略在执行订单时不会取消或减少订单,这意味着有可能交易比未平仓头寸更大的数量,并逆转方向:
//@version=5
strategy("Multiple TP Demo", overlay = true)
var float stop = na
var float limit1 = na
var float limit2 = na
bool longCondition = ta.crossover(ta.sma(close, 5), ta.sma(close, 9))
if longCondition and strategy.position_size == 0
stop := close * 0.99
limit1 := close * 1.01
limit2 := close * 1.02
strategy.entry("Long", strategy.long, 6)
strategy.order("Stop", strategy.short, stop = stop, qty = 6)
strategy.order("Limit 1", strategy.short, limit = limit1, qty = 3)
strategy.order("Limit 2", strategy.short, limit = limit2, qty = 3)
bool showPlot = strategy.position_size != 0
plot(showPlot ? stop : na, "Stop", color.red, style = plot.style_linebr)
plot(showPlot ? limit1 : na, "Limit 1", color.green, style = plot.style_linebr)
plot(showPlot ? limit2 : na, "Limit 2", color.green, style = plot.style_linebr)
为使我们的策略按预期运行,我们必须指示它减少其他止损/止盈订单的单位数,使其不超过剩余未结头寸的大小。
在下面的示例中,将退出策略中订单的oca_name设置为"Bracket",oca_type设为strategy.oca.reduce。这些设置告诉策略在执行"Bracket"组中的一个订单时,将其数量值减去已执行的数量,以防止交易单位数量过多而导致反转:
//@version=5
strategy("Multiple TP Demo", overlay = true)
var float stop = na
var float limit1 = na
var float limit2 = na
bool longCondition = ta.crossover(ta.sma(close, 5), ta.sma(close, 9))
if longCondition and strategy.position_size == 0
stop := close * 0.99
limit1 := close * 1.01
limit2 := close * 1.02
strategy.entry("Long", strategy.long, 6)
strategy.order("Stop", strategy.short, stop = stop, qty = 6, oca_name = "Bracket", oca_type = strategy.oca.reduce)
strategy.order("Limit 1", strategy.short, limit = limit1, qty = 3, oca_name = "Bracket", oca_type = strategy.oca.reduce)
strategy.order("Limit 2", strategy.short, limit = limit2, qty = 6, oca_name = "Bracket", oca_type = strategy.oca.reduce)
bool showPlot = strategy.position_size != 0
plot(showPlot ? stop : na, "Stop", color.red, style = plot.style_linebr)
plot(showPlot ? limit1 : na, "Limit 1", color.green, style = plot.style_linebr)
plot(showPlot ? limit2 : na, "Limit 2", color.green, style = plot.style_linebr)
l 将limit2订单的数量改为6,而不是3,因为策略在执行limit1订单时会将其数量减少3。保持3的数量值会导致其降至0,并且在成交第一个限价单后永远不会成交。
strategy.oca.none
strategy.oca.none OCA类型指定订单独立于任何OCA组执行。此值是strategy.order()和strategy.entry()下单命令的默认OCA_type。
注意:
如果两个下单指令的oca_name相同,但oca_type值不同,则策略会将它们视为来自两个不同的组。也就是说,OCA组不能结合strategy.oca.cancel、strategy.oca.reduce和strategy.oca.none OCA类型。
货币
Pine Script®策略可以使用与其计算工具不同的基础货币。用户可以通过在strategy()函数中加入currency.*变量作为货币参数来指定模拟账户的基础货币,这将改变脚本的strategy.account_currency值。策略的默认货币值是currency.NONE,这意味着脚本使用图表上工具的基础货币。
当策略脚本使用指定的基础货币时,它会将模拟利润乘以前一个交易日的FX_IDC汇率。例如,下面的策略在最后500个K线中的每个K线上下达了标准手(100,000单位)的进场单,止盈目标和止损均为1点,然后在单独的窗格中将净利润与商品每日收盘价一起绘制出来。我们将基础货币设置为currency.EUR。当我们将此脚本添加到FX_IDC:EURUSD时,两个图对齐,确认该策略使用该商品的前一日汇率进行计算:
//@version=5
strategy("Currency Test", currency = currency.EUR)
if last_bar_index - bar_index < 500
strategy.entry("LE", strategy.long, 100000)
strategy.exit("LX", "LE", profit = 1, loss = 1)
plot(math.abs(ta.change(strategy.netprofit)), "1 Point profit", color = color.fuchsia, linewidth = 4)
plot(request.security(syminfo.tickerid, "D", 1 / close)[1], "Previous day's inverted price", color = color.lime)
请注意:
l 在高于日线的时间框架上进行交易时,策略将使用K线前一个交易日的收盘价来计算历史K线的跨汇率。例如,在周时间框架上,它将根据前一个周四的close来计算跨汇率,不过该策略仍将使用实时K线的每日收盘价。
改变计算行为
策略在图表中所有可用的历史K线上执行,然后在有新数据时自动继续实时计算。默认情况下,策略脚本只对每个确认的K线计算一次。我们可以通过更改strategy()函数的参数或单击脚本“属性”选项卡中“重新计算”部分的复选框来改变这种行为。
实时K线更新时计算
calc_on_every_tick是一个可选设置,用于控制实时数据的计算行为。启用该参数后,脚本将在每个新的价格刻度上重新计算其值。默认情况下,其值为假,这意味着脚本只在确认K线收盘后执行计算。
启用这种计算行为在前测时特别有用,因为它有助于进行细刻度的实时策略模拟。不过需要注意的是,这种行为会在实时模拟和历史模拟之间引入数据差异,因为历史K线不包含点数信息。用户应谨慎使用此设置,因为数据差异可能会导致策略重新绘制历史记录。
下面的脚本将在每次close触及输入的length长度的highest或lowest时模拟新订单。由于在策略声明中启用了calc_on_every_tick,因此在编译后,脚本将在每个新的实时价格刻度上模拟新订单:
//@version=5
strategy("Donchian Channel Break", overlay = true, calc_on_every_tick = true, pyramiding = 20)
int length = input.int(15, "Length")
float highest = ta.highest(close, length)
float lowest = ta.lowest(close, length)
if close == highest
strategy.entry("Buy", strategy.long)
if close == lowest
strategy.entry("Sell", strategy.short)
//@variable 实时K线的起始时间。
var realTimeStart = timenow
// 为实时K线的背景着色。
bgcolor(time_close >= realTimeStart ? color.new(color.orange, 80) : na)
plot(highest, "Highest", color = color.lime)
plot(lowest, "Lowest", color = color.red)
请注意:
l 该脚本在声明中使用了20的pyramiding值,这使得该策略最多可以模拟20笔相同方向的交易。
l 为了直观地标明哪些K线被策略作为实时K线处理,脚本会为自上次编译时点以来的所有K线着色。
将脚本应用于图表并让其计算一些实时K线后,我们可能会看到如下输出:
该脚本在条件有效的每个新的实时K线更新时都下了buy订单,导致每个K线都有多个订单。不过,不熟悉这种行为的用户在重新编译脚本后可能会惊讶地发现该策略的输出发生了变化,因为它之前执行实时计算的K线现在变成了历史K线,而历史K线不保存tick信息:
实时成交后立即计算
可选的"calc_on_order_fills"设置可以在模拟订单成交后立即重新计算策略,这样脚本就可以使用更精细的价格,并在不等待实时K线收盘就下达额外的订单。
启用此设置可以为脚本提供一般在K线收盘后才能获得的额外数据,例如未确认K线上模拟仓位的当前平均价格。
下面的示例显示了一个启用了calc_on_order_fills的简单策略,该策略在strategy.position_size为0时模拟"buy"订单。脚本使用strategy.position_avg_price计算止损和止盈,并在价格突破时模拟"exit"订单,不管该K线是否收盘。因此一旦触发退出,该策略就会重新计算并下达新的进场单,因为strategy.position_size再次等于0。一旦退出发生,该策略就会下进场单,并在退出后的下一个刻度执行订单,该刻度将是K线的OHLC值之一,具体取决于模拟的K线内变动:
//@version=5
strategy("Intrabar exit", overlay = true, calc_on_order_fills = true)
float stopSize = input.float(5.0, "SL %", minval = 0.0) / 100.0
float profitSize = input.float(5.0, "TP %", minval = 0.0) / 100.0
if strategy.position_size == 0.0
strategy.entry("Buy", strategy.long)
float stopLoss = strategy.position_avg_price * (1.0 - stopSize)
float takeProfit = strategy.position_avg_price * (1.0 + profitSize)
strategy.exit("Exit", stop = stopLoss, limit = takeProfit)
请注意:
l 关闭calc_on_order_fills后,同一策略只会在触发退场指令后进入一个K线。首先,会发生在K线中间离场,但没有进场指令。然后,一旦K线收盘,该策略将模拟进入订单,并在之后的下一个刻度线(即下一K线的开盘价)执行订单。
需要注意的是,启用calc_on_order_fills可能会产生不切实际的策略结果,因为经纪商模拟器可能会假设实时交易时不可能出现的订单价格。用户必须谨慎使用此设置,并仔细考虑脚本中的逻辑。
下面示例模拟了加载脚本时,从last_bar_index开始的25个K线窗口中,每个新订单成交和K线确认后的buy订单。启用该设置后,由于模拟器认为每个K线都有四个刻度线(开盘、高点、低点、收盘),因此该策略会模拟每个K线的四个进场,这是不现实的行为,因为订单通常不可能在一个K线的确定高点或低点成交:

//@version=5
strategy("buy on every fill", overlay = true, calc_on_order_fills = true, pyramiding = 100)
if last_bar_index - bar_index <= 25
strategy.entry("Buy", strategy.long)
收盘时执行订单
默认策略行为是在每个K线收盘时模拟订单,这意味着在下一个K线开盘时最早有机会执行订单并执行策略计算和警报。交易者可以通过启用process_orders_on_close设置,将此行为改为使用每个K线的收盘时处理策略。
在回测手动策略时,如果交易员在K线收盘前退出头寸,或者在非24x7市场中的算法交易员设置了收盘后交易功能,以便收盘后发送的警报仍有希望在次日之前执行时,这种行为最为有用。
注意:
l 关键是要注意,在实时交易环境中使用带有process_orders_on_close的策略可能会导致重绘策略,因为在市场收盘时仍会发生K线收盘时的警报,而订单可能要到下一次市场开盘时才会成交。
模拟交易成本
为使策略绩效报告包含相关、有意义的数据,交易者应努力在策略结果中考虑潜在的实际成本。忽略这一点可能会让交易者对策略绩效产生不切实际的看法,并损害测试结果的可信度。如果不模拟与交易相关的潜在成本,交易者可能会高估策略的历史盈利能力,从而可能导致在实际交易中做出次优决策。Pine Script®策略包括模拟交易成本的输入和参数。
l 佣金
佣金是指经纪商/交易所在执行交易时收取的费用。根据经纪商/交易所的不同,有些会对每笔交易或合约/股票/手/单位收取固定费用,有些则会按总交易额的一定比例收取费用。用户可以在strategy()函数中加入commission_type和commission_value参数,或在策略设置的“属性”选项卡中设置“佣金”输入,从而设置策略的佣金属性。
下面的脚本是一个简单的策略,当close等于length条K线内的最高值时,模拟2%的"做多"头寸,当close等于最低值时,关闭交易:
//@version=5
strategy("Commission Demo", overlay=true, default_qty_value = 2, default_qty_type = strategy.percent_of_equity)
length = input.int(10, "Length")
float highest = ta.highest(close, length)
float lowest = ta.lowest(close, length)
switch close
highest => strategy.entry("Long", strategy.long)
lowest => strategy.close("Long")
plot(highest, color = color.new(color.lime, 50))
plot(lowest, color = color.new(color.red, 50))
通过查看策略测试器中的结果,我们发现该策略在测试范围内的净值增长率为17.61%。但是,回测结果并没有考虑经纪人/交易所可能收取的费用。让我们看看,当我们在策略模拟中的每笔交易中都包含少量佣金时,这些结果会发生什么变化。在这个示例中,我们在strategy()声明中加入了commission_type = strategy.commission.percent和commission_value = 1,这意味着它将模拟所有已执行订单的1%佣金:
//@version=5
strategy(
"Commission Demo", overlay=true, default_qty_value = 2, default_qty_type = strategy.percent_of_equity, commission_type = strategy.commission.percent, commission_value = 1
)
length = input.int(10, "Length")
float highest = ta.highest(close, length)
float lowest = ta.lowest(close, length)
switch close
highest => strategy.entry("Long", strategy.long)
lowest => strategy.close("Long")
plot(highest, color = color.new(color.lime, 50))
plot(lowest, color = color.new(color.red, 50))
从上面的例子中我们可以看到,在回测中应用了1%的佣金后,该策略模拟的净利润大幅减少,仅为1.42%,而且股票曲线波动更大,最大亏损率更高,这突出表明了佣金模拟对策略测试结果的影响。
l 滑点和未执行限额
在实际交易中,由于波动性、流动性、订单大小和其他市场因素的影响,经纪商/交易所执行订单的价格可能与交易者的预期价格略有不同,这可能会对策略的表现产生深远影响。预期价格与经纪商/交易所执行交易的实际价格之间的差距就是我们所说的滑点。滑点是动态的、不可预测的,因此无法精确模拟。不过,在回测或前测中,将每笔交易中的少量滑点因素考虑在内,可能有助于使结果更符合实际情况。用户可以通过在strategy()声明中加入slippage参数,或在策略设置的“属性”选项卡中设置"滑点",o 策略结果中模拟滑点,其大小为固定的点数。
下面示例演示了滑点模拟如何影响策略测试中市价单的成交价。在EMA上升时,当市场价格高于EMA时,下达2%净值的"Buy"市价单;在EMA下降时,当价格跌破EMA时平仓。在strategy()函数中加入了slipage = 20,声明每个订单的价格向交易方向滑动20个点。使用strategy.opentrades.entry_bar_index()和strategy.closedtrades.exit_bar_index()获得entryIndex和exitIndex,然后利用这两个值获得订单的fillPrice。当K线位于entryIndex时,fillPrice是第一个strategy.openentrades.entry_price()值。在exitIndex处,fillPrice是最后一笔平仓的strategy
.closedtrades.exit_price()值。脚本绘制预期成交价和滑点后的模拟成交价,直观地比较两者之间的差异:
//@version=5
strategy(
"Slippage Demo", overlay = true, slippage = 20,
default_qty_value = 2, default_qty_type = strategy.percent_of_equity
)
int length = input.int(5, "Length")
//@variable 指数移动平均线,输入 `length`。
float ma = ta.ema(close, length)
//当 `ma` 增加且 `close` 大于它时返回 `true`,否则返回 `false`。
bool longCondition = close > ma and ma > ma[1]
//当 `ma` 下降且 `close` 小于它时,返回 `true`,否则返回 `false`。bool shortCondition = close < ma and ma < ma[1]
// 在 "longCondition "上输入市场做多头寸,在 "shortCondition "上平仓。
if longCondition
strategy.entry("Buy", strategy.long)
if shortCondition
strategy.close("Buy")
//@variable 仓位进场指令的 `bar_index`。
int entryIndex = strategy.opentrades.entry_bar_index(0)
//@variable 仓位平仓单补仓的 `bar_index` 。
int exitIndex = strategy.closedtrades.exit_bar_index(strategy.closedtrades - 1)
//@variable 策略模拟的填充价格。
float fillPrice = switch bar_index
entryIndex => strategy.opentrades.entry_price(0)
exitIndex => strategy.closedtrades.exit_price(strategy.closedtrades - 1)
//@variable 公开市场头寸的预期补仓价格。
float expectedPrice = fillPrice ? open : na
color expectedColor = na
color filledColor = na
if bar_index == entryIndex
expectedColor := color.green
filledColor := color.blue
else if bar_index == exitIndex
expectedColor := color.red
filledColor := color.fuchsia
plot(ma, color = color.new(color.orange, 50))
plotchar(fillPrice ? open : na, "Expected fill price", "—", location.absolute, expectedColor)
plotchar(fillPrice, "Fill price after slippage", "—", location.absolute, filledColor)
请注意:
l 由于该策略对所有订单成交应用恒定滑点,因此在模拟中,一些订单可能会在蜡烛图范围之外成交。因此,用户应谨慎使用此设置,因为过多的模拟滑点可能会产生不切实际的较差测试结果。
一些交易者可能会认为,使用限价单可以避免滑点的不利影响,因为与市价单不同,限价单不能以比指定值更差的价格执行。然而,根据现实市场的状况,即使市场价格达到了订单价格,限价单也有可能无法成交,因为限价单只有在证券有足够的流动性和价格行动围绕该价值的情况下才能成交。为了在回测中考虑未成交订单的可能性,用户可以在声明语句中指定backtest_fill_limits_assumption值,或使用“属性”选项卡中的“验证限价单价格”输入,指示策略只有在价格超过订单价格一定数量后才成交限价单。
下面的示例在K线的hlcc4位置下达了2%净值的限价单,此时高点是过去所有K线的最高值,并且没有挂单。当低点为最低值时,该策略关闭市场头寸并取消所有订单。该策略每次触发订单时,都会在limitPrice处画一条水平线,并在每个K线上更新,直至平仓或取消订单:
//@version=5
strategy(
"Verify price for limits example", overlay = true,
default_qty_type = strategy.percent_of_equity, default_qty_value = 2
)
int length = input.int(25, title = "Length")
//@variable 在最近输入订单的限价处画一条线。
var line limitLine = na
// high和low
highest = ta.highest(length)
lowest = ta.lowest(length)
//当 "high "等于 "highest "值,且 "limitLine "为 "na "时,下入订单并画新线。
if high == highest and na(limitLine)
float limitPrice = hlcc4
strategy.entry("Long", strategy.long, limit = limitPrice)
limitLine := line.new(bar_index, limitPrice, bar_index + 1, limitPrice)
//关闭公开市场仓位,取消订单,并在`low`等于`lowest`值时将`limitLine`设为`na`。
if low == lowest
strategy.cancel_all()
limitLine := na
strategy.close_all()
// 更新 `limitLine` 的 `x2` 值(如果它不是 `na`)。
if not na(limitLine)
limitLine.set_x2(bar_index + 1)
plot(highest, "Highest High", color = color.new(color.green, 50))
plot(lowest, "Lowest Low", color = color.new(color.red, 50))
默认情况下,脚本假定所有限价单都保证成交。但在实际交易中,情况往往并非如此。让我们为我们的限价单添加价格验证,以考虑潜在的未成交订单。在本例中,我们在strategy()函数调用中加入了 backtest_fill_limits_assumption = 3。我们可以看到,使用限价验证会省略一些模拟订单的成交,并改变其他订单的成交时间,因为现在只有在价格穿透限价三个刻度线后,输入订单才能成交:
注意:
需要注意的是,虽然限价单验证改变了某些订单的成交时间,但该策略仍以相同的价格模拟这些订单。这种 "时间扭曲 "效果是一种折衷方案,它保留了已验证限价单的价格,但可能导致策略模拟的成交时间在现实世界中不一定可行。用户在分析策略结果时,应谨慎使用此设置并了解其局限性。
风险管理
设计一个表现出色的策略是一项具有挑战性的任务,更不用说在各类市场中都能表现出色。大多数策略都是针对特定市场模式/条件设计的,应用于其他数据时会产生无法控制的损失。因此,策略的风险管理质量对其绩效至关重要。用户使用带有strategy.risk前缀的特殊命令在策略脚本中设置风险管理标准。
策略可以包含任意数量、组合的风险管理标准。所有风险管理命令都会在每个点和订单执行事件中执行,与策略计算行为的任何变化无关。无法在脚本运行时禁用任何这些命令。无论风险规则的位置如何,它都将始终应用于策略,除非用户从代码中删除调用。
strategy.risk.allow_entry_in()
该命令覆盖strategy.entry()命令所允许的市场方向。当用户使用该函数指定交易方向(如strategy.direction.long)时,策略将只进入该方向的交易。不过,需要注意的是,如果脚本在未平仓市场头寸的情况下调用了相反方向的进场命令,则该策略将模拟市价单退出头寸。
strategy.risk.max_cons_loss_days()
该命令会取消所有挂单,关闭未平仓市场头寸,并在策略模拟一定数量的连续亏损交易日后停止所有额外的交易操作。
strategy.risk.max_drawdown()
当策略亏损达到函数调用中指定的金额时,该命令会取消所有挂单、关闭公开市场头寸并停止所有其他交易操作。
strategy.risk.max_intraday_filled_orders()
该命令指定每个交易日(或每个图表K线,如果时间框架高于每日)的最大成交订单数。一旦策略执行了当天的最大订单数,就会取消所有挂单,关闭未结市场头寸,并停止交易活动,直到当前时段结束。
strategy.risk.max_intraday_loss()
该命令控制策略每个交易日(如果时间框架高于日线,则为每个图表K线)可承受的最大损失。当该策略的亏损达到该阈值时,它将取消所有挂单、平仓并停止所有交易活动,直到当前交易时段结束。
strategy.risk.max_position_size()
该命令用于指定使用 strategy.entry() 命令时的最大持仓量。如果进场指令的数量导致市场头寸超过该阈值,则策略将减少订单数量,使所产生的头寸不超过限制值
保证金
保证金是交易者必须在其账户中持有的市场头寸的最低百分比,是从经纪人获得并维持贷款以实现所需的杠杆率的抵押。strategy()声明中的margin_long和margin_short参数以及脚本设置“属性”选项卡中的“做多/做空头寸保证金”允许策略指定做多和做空头寸的保证金百分比。例如,交易者将做多头寸的保证金设置为25%,那么他们必须有足够的资金来支付未平仓做多头寸的25%。这个保证金百分比也意味着交易者有可能在交易中花费高达400%的资金。
如果模拟资金无法弥补保证金交易的损失,经纪商模拟器就会触发追加保证金通知,强行平仓全部或部分头寸。模拟器清算的合约/股票/手数/单位的确切数量是弥补亏损所需的四倍,防止后续K线不断追加保证金。模拟器通过以下算法计算这一数额:
1.计算在头寸上花费的资金:Money Spent = Quantity * Entry Price
2.计算证券市值 (MVS):MVS = Position Size * Current Price
3.计算未平仓利润,即MVS与Money Spent之间的差额。如果是做空头寸,则乘以-1。
4.计算策略的权益价值:Equity = Initial Capital + Net Profit + Open Profit
5.计算保证金比率:Margin Ratio = Margin Percent / 100
6.计算保证金值,即弥补交易者头寸部分所需的现金:Margin = MVS * Margin Ratio
7. 计算可用资金:Available Funds = Equity - Margin
8.计算交易者损失的资金总额:Loss = Available Funds / Margin Ratio
9.计算交易者需要清算多少合约/股票/手/单位才能弥补损失。我们将该值截断到与当前符号最小持仓量相同的十进制精度:Cover Amount = TRUNCATE(Loss / Current Price)。
10.计算经纪商将清算多少单位来弥补损失:Margin Call = Cover Amount * 4
要详细查看此计算,让我们在1D时间框架的NASDAQ:TSLA图表上添加内置的超级趋势策略,并在策略设置的“属性”选项卡中将“订单大小”设为净值的 300%,将“做多仓位保证金”设为25%:
第一次入市发生在2010年9月16日K线open。该策略以4.43美元(入市价)买入682 438股(头寸规模)。然后,在2010年9月23日,当价格跌至3.9(当前价格)时,模拟器通过追加保证金强行平仓了111,052股。
Money spent: 682438 * 4.43 = 3023200.34
MVS: 682438 * 3.9 = 2661508.2
Open Profit: −361692.14
Equity: 1000000 + 0 − 361692.14 = 638307.86
Margin Ratio: 25 / 100 = 0.25
Margin: 2661508.2 * 0.25 = 665377.05
Available Funds: 638307.86 - 665377.05 = -27069.19
Money Lost: -27069.19 / 0.25 = -108276.76
Cover Amount: TRUNCATE(-108276.76 / 3.9) = TRUNCATE(-27763.27) = -27763
Margin Call Size: -27763 * 4 = - 111052
Pine Script®指标有两种不同的机制来设置自定义警报条件:alertcondition()函数和alert()函数。前者可在每次函数调用时跟踪一个特定条件,后者可同时跟踪所有调用,但在调用次数、警报信息等方面具有更大的灵活性。
Pine Script®策略不支持alertcondition()调用,但支持通过alert()函数生成自定义警报。此外,每个创建订单的函数都有自己的内置警报功能,无需额外代码即可实现。因此,任何使用下单指令的策略都能在订单执行时发出警报。《用户手册》中"警报"页面的"订单成交事件"部分介绍了此类内置警报的精确机制。
当策略同时使用创建订单的函数和alert()函数时,警报创建对话框提供了触发条件的选择:可以在alert()事件、订单成交事件或两者同时发生时触发。
对于许多交易策略而言,触发条件与实时交易之间的延迟可能是一个关键的性能因素。默认情况下,策略脚本只能在实时K线收盘时执行alert()函数调用,认为它们使用了alert.freq_once_per_bar_close,而不管调用中的freq参数是什么。用户可以通过在strategy()调用中包含calc_on_every_tick = true或在创建警报前在策略设置的“属性”选项卡中选择"在每个tick时重新计算"来更改警报频率。不过,根据脚本的不同,这也可能会对策略的行为产生不利影响,因此在使用这种方法时要谨慎,并注意其局限性。
在向第三方发送警报以实现策略自动化时,我们建议使用订单成交警报而不是alert()函数,因为它们不会受到同样的限制;订单成交事件产生的警报会立即执行,不受脚本的calc_on_every_tick设置的影响。用户可以通过@strategy_alert_message编译器注解设置订单成交警报的默认信息。该注解提供的文本将填充警报创建对话中订单成交的“信息”字段。
下面的脚本展示了一个默认订单成交警报信息的简单示例。在strategy()声明语句的上方,它使用了 @strategy_alert_message,并为消息文本中的交易操作、仓位大小、股票代码和成交价值设置了占位符:
//@version=5
//@strategy_alert_message {{strategy.order.action}} {{strategy.position_size}} {{ticker}} @ {{strategy.order.price}}
strategy("Alert Message Demo", overlay = true)
float fastMa = ta.sma(close, 5)
float slowMa = ta.sma(close, 10)
if ta.crossover(fastMa, slowMa)
strategy.entry("buy", strategy.long)
if ta.crossunder(fastMa, slowMa)
strategy.entry("sell", strategy.short)
plot(fastMa, "Fast MA", color.aqua)
plot(slowMa, "Slow MA", color.orange)
当用户从“条件”下拉选项卡中选择警报名称时,该脚本将以默认信息填充警报创建对话框:
警报触发后,策略将在警报信息中用相应的值填充占位符。例如:
交易者通常会在历史和实时市场条件下测试和调整自己的策略,因为许多人认为,分析结果可以为了解策略的特点、潜在弱点以及可能的未来潜力提供有价值的见解。但是,交易者应始终注意模拟策略结果的偏差和局限性,尤其是在使用模拟结果支持实时交易决策时。本节概述了与策略验证和调整相关的一些注意事项,以及减轻其影响的可能解决方案。
注意:
虽然根据现有数据测试策略可以为交易者提供有关策略质量的有用信息,但必须注意的是,过去和现在都不能保证未来。金融市场可能瞬息万变,难以预测,这可能导致策略遭受无法控制的损失。此外,模拟结果可能无法完全考虑影响交易表现的其他现实因素。因此,我们建议交易者在评估回测和前测时彻底了解其局限性和风险,并在验证过程中将其视为“整体的一部分”,而不是仅根据结果做出决策。
回测是交易者用来评估交易策略或模型历史表现的一种技术,通过模拟和分析其过去在历史市场数据上的结果;这种技术假定对策略在过去数据上的结果进行分析,可以深入了解其优缺点。在进行回测时,许多交易者会调整策略参数,试图优化其结果。对历史结果进行分析和优化有助于交易者更深入地了解某一策略。但是,交易者在根据优化后的回测结果做出决策时,应始终了解其风险和局限性。
进行回测的同时,审慎的交易系统开发通常还包括将实时分析作为评估交易系统前瞻性的工具。前测旨在衡量策略在实时、真实市场条件下的表现,在这种条件下,交易成本、滑点和流动性等因素都会对其表现产生有意义的影响。前测的明显优势是不会受到某些类型的偏差(如前视偏误或 "未来数据泄漏")的影响,但缺点是测试的数据量有限。因此,它通常不是一个独立的策略验证解决方案,但能为策略在当前市场条件下的表现提供有用的见解。
回测和前测是同一枚硬币的两面,因为这两种方法都旨在验证策略的有效性并找出其优缺点。通过将回测和前测相结合,交易者或许可以弥补一些局限性,并对其策略的表现有更清晰的认识。不过,交易者有责任对自己的策略和评估流程进行清理,以确保洞察力尽可能与现实保持一致。
在对某些策略进行回测时,即那些要求交替使用时间框架数据、使用重新绘制变量(如 timenow)或改变计算行为以实现K线内订单成交的策略,会遇到一个典型的问题,那就是在评估过程中将未来数据泄露到过去,这就是所谓的前视偏误。这种偏差不仅是导致不切实际的策略结果的常见原因,因为未来实际上永远无法事先知晓,而且也是策略重绘的典型原因之一。交易者通常可以通过对系统进行前测来确认这种偏差,因为前视偏误不适用于实时数据,在实时数据中,当前K线以外不存在任何已知数据。用户可以通过以下方法消除策略中的这种偏差:确保不使用将未来泄露到过去的重绘变量;request.*()函数不包含barmerge.lookahead_on而不偏移数据序列(如重绘页面本节所述);使用现实的计算行为。
选择偏差是许多交易者在测试策略时经常遇到的问题。当交易者只分析特定工具或时间框架的结果,而忽略其他工具或时间框架时,就会出现这种情况。这种偏差会导致对策略稳健性的认识出现偏差,从而影响交易决策和性能优化。交易者可以通过在多个(最好是不同的)符号和时间框架上评估其策略来减少选择偏差的影响,在分析中不要忽略性能不佳的结果,也不要挑剔测试范围。
在优化回测时,一个常见的陷阱是可能出现过拟合("曲线拟合"),这是指针对特定数据定制的策略无法在新的、未见过的数据上很好地泛化。一种广泛使用的有助于降低过拟合可能性并提高泛化效果的方法是,将工具的数据分成两部分或更多部分,在用于优化的样本之外测试策略,也就是所谓的"样本内"(IS)和"样本外"(OOS)回测。在这种方法中,交易者使用IS数据进行策略优化,而OOS部分则用于在新数据上测试和评估 IS 优化后的性能,而无需进一步优化。虽然这种方法和其他更稳健的方法可以让人一窥策略优化后的表现,但交易者应谨慎行事,因为未来本质上是不可知的。无论用于测试和优化的数据如何,任何交易策略都不能保证未来的表现。
表格
l ·简介
l ·创建表格
l ·提示
简介
表格是一种可以在脚本的视觉空间中将信息放置在特定固定位置的对象。与 Pine Script®中绘制的所有其他图表或对象相反,表格并不固定在特定的K线上;无论是在叠加模式或窗格模式下,还是在研究或策略中,表格都会浮动在脚本空间中,与所查看的图表K线或所使用的缩放系数无关。
表格包含按列和行排列的单元格,很像电子表格。表格的创建和填充分为两个不同的步骤:
1.使用table.new()定义表格的结构和关键属性,它返回一个表格ID,就像标签、行或数组ID一样,该ID就像表格的指针。table.new()调用将创建表格对象,但不会显示它。
2.创建表格后,必须为每个单元格调用table.cell()才能显示表格。表格单元格可以包含文本,也可以不包含文本。第二步是定义单元格的宽度和高度。
可以使用table.set_*()设置函数更改先前创建的表格的大部分属性。可以使用table.cell_set_*()函数修改已填充单元格的属性。
通过将表格锚定到九个参考点之一(四个角或中点,包括中心点),可将表格定位在指标空间中。表格是通过从其锚点向外扩展来定位的,因此锚定在position.middle_right引用上的表格将通过从该锚点向上、向下和向左扩展来绘制。
有两种模式可用于确定表格单元格的宽度/高度:
l 默认的自动模式使用列/行中最宽/最高的文本计算单元格的宽度/高度。
l 显式模式允许程序员使用指标可用的x/y空间的百分比来定义单元格的宽度/高度。
显示的表格内容始终代表表格的最后状态,即在脚本最后一次执行时,在数据集的最后一条K线上绘制的表格。因此,与数据窗口或指标值中显示值相反,表格中显示的变量内容不会随着脚本用户将光标移动到特定图表K线而改变。因此,强烈建议将所有table.*()调用的执行时间限制在数据集的第一条或最后一条K线上:
l 使用var关键字声明表格。
l 在if barstate.islast块中关闭所有其他调用。
在一个脚本中可以使用多个表格,只要它们分别锚定到不同的位置。每个表格对象都有自己的ID。所有表格中单元格数量的限制取决于一个脚本中使用的单元格总数。
创建表格
使用table.new()创建表格时,有三个参数是必须的:表格的位置、列数和行数。其他五个参数为可选参数:表格的背景颜色、表格外框的颜色和宽度,以及所有单元格(不包括外框)边框的颜色和宽度。除了列数和行数外,所有表格属性都可以使用设置函数进行修改:table.set_position()、table.set_bgcolor()、table.set_frame_color()、table.set_frame_width()、table.set_border_color()和table.set_border_width()。
使用 table.delete()可以删除表格,使用table.clear()可以有选择地删除表格内容。
使用table.cell()填充单元格时,必须为四个必选参数提供参数:单元格所属的表id、以零为起点的列和行索引以及单元格包含的文本字符串(可以为空)。其他七个参数为可选参数:单元格的宽度和高度、文本属性(颜色、水平和垂直对齐方式、大小)以及单元格的背景颜色。所有单元格属性都可以使用设置函数修改:table.cell_set_text()、table.cell_set_width(), table.cell_set_height(), table.cell_set_text_color(), table.cell_set_text_halign(), table.cell_set_text_valign(), table.cell_set_text_size() 和 table.cell_set_bgcolor()。
记住,每次连续调用table.cell()都会重新定义单元格的所有属性,删除之前在同一单元格上调用table.cell()设置的任何属性。
l 在固定位置放置单个值
让我们创建第一个表格,将 ATR 值放在图表的右上角。我们首先创建一个单单元格表格,然后填充该单元格:
//@version=5
indicator("ATR", "", true)
// 我们使用 `var` 只在第一个K线时初始化表格。
var table atrDisplay = table.new(position.top_right, 1, 1)
// 我们在 "if "代码块外调用"ta.atr()",这样它就会在每个K线上执行.
myAtr = ta.atr(14)
if barstate.islast
// 我们只在最后一个K线上填充表格.
table.cell(atrDisplay, 0, 0, str.tostring(myAtr))
l 在使用 table.new() 创建表格时,我们使用了 var 关键字。
l 我们使用 table.cell() 在 if barstate.islast 块内填充单元格。
l 在填充单元格时,我们没有指定宽度或高度。因此,单元格的宽度和高度将根据其包含的文本自动调整。
l 在进入 if 代码块之前,我们调用了 ta.atr(14),这样它就会在每个K线上进行求值。如果我们在 if 代码块中使用 str.tostring(ta.atr(14)),函数将无法正确求值,因为它将在数据集最后一个K线时调用,而没有计算前几个K线的必要值。
让我们提高脚本的可用性和美观性吧:
//@version=5
indicator("ATR", "", true)
atrPeriodInput = input.int(14, "ATR period", minval = 1, tooltip = "Using a period of 1 yields True Range.")
var table atrDisplay = table.new(position.top_right, 1, 1, bgcolor = color.gray, frame_width = 2, frame_color = color.black)
myAtr = ta.atr(atrPeriodInput)
if barstate.islast
table.cell(atrDisplay, 0, 0, str.tostring(myAtr, format.mintick), text_color = color.white)
请注意:
l 我们使用 table.new() 定义了背景颜色、框架颜色及其宽度。
l 使用 table.cell() 填充单元格时,我们将文本设置为白色显示。
l 我们将format.mintick作为str.tostring()函数的第二个参数,将ATR的精度限制为图表的刻度线精度。
l 我们现在使用输入法让脚本用户指定ATR周期。该输入还包含一个工具提示,用户将鼠标悬停在脚本"设置/输入"选项卡中的"i"图标上时即可看到。
l 为图表背景着色
本示例使用单格表格为RSI牛熊状态的图表背景着色:
//@version=5
indicator("Chart background", "", true)
bullColorInput = input.color(color.new(color.green, 95), "Bull", inline = "1")
bearColorInput = input.color(color.new(color.red, 95), "Bear", inline = "1")
// ————— RSI 牛市/熊市状态下的功能颜色图标.
colorChartBg(bullColor, bearColor) =>
var table bgTable = table.new(position.middle_center, 1, 1)
float r = ta.rsi(close, 20)
color bgColor = r > 50? bullColor : r < 50 ? bearColor : na
if barstate.islast
table.cell(bgTable, 0, 0, width = 100, height = 100, bgcolor = bgColor)
colorChartBg(bullColorInput, bearColorInput)
请注意:
l 我们为用户提供输入,允许他们指定背景使用的牛/熊颜色,并将这些输入颜色作为参数发送到我们的 colorChartBg() 函数。
l 我们只创建一次新表格,使用 var 关键字声明表格。
l 我们只在最后一个K线上使用 table.cell(),以指定单元格的属性。我们将单元格设置为指标空间的宽度和高度,因此它覆盖了整个图表。
l 创建显示面板
表格是创建复杂显示面板的理想工具。表格不仅可以使显示面板始终在固定位置可见,还可以提供更灵活的格式,因为每个单元格的属性都可以单独控制:背景、文本颜色、大小和对齐方式等。
在这里,我们创建了一个基本的显示面板,显示用户选择的MAs值数量。我们在第一列显示它们的周期,然后用绿色/红色/灰色背景显示它们的值,该背景随价格相对于每个MA的位置而变化。当价格高于/低于MA时,单元格的背景颜色为牛市/熊市颜色。当MA位于当前K线的open和close之间时,单元格背景为中性色。
//@version=5
indicator("Price vs MA", "", true)
var string GP1 = "Moving averages"
int masQtyInput = input.int(20, "Quantity", minval = 1, maxval = 40, group = GP1, tooltip = "1-40")
int masStartInput = input.int(20, "Periods begin at", minval = 2, maxval = 200, group = GP1, tooltip = "2-200")
int masStepInput = input.int(20, "Periods increase by", minval = 1, maxval = 100, group = GP1, tooltip = "1-100")
var string GP2 = "Display"
string tableYposInput = input.string("top", "Panel position", inline = "11", options = ["top", "middle", "bottom"], group = GP2)
string tableXposInput = input.string("right", "", inline = "11", options = ["left", "center", "right"], group = GP2)
color bullColorInput = input.color(color.new(color.green, 30), "Bull", inline = "12", group = GP2)
color bearColorInput = input.color(color.new(color.red, 30), "Bear", inline = "12", group = GP2)
color neutColorInput = input.color(color.new(color.gray, 30), "Neutral", inline = "12", group = GP2)
var table panel = table.new(tableYposInput + "_" + tableXposInput, 2, masQtyInput + 1)
if barstate.islast
// Table header.
table.cell(panel, 0, 0, "MA", bgcolor = neutColorInput)
table.cell(panel, 1, 0, "Value", bgcolor = neutColorInput)
int period = masStartInput
for i = 1 to masQtyInput
// ————— 在每个K线上呼叫 MA。
float ma = ta.sma(close, period)
// ————— 只在最后一个K线上执行表格代码。
if barstate.islast
// 左栏中的句号。
table.cell(panel, 0, i, str.tostring(period), bgcolor = neutColorInput)
//如果 MA 位于open和close之间,则使用中性色。如果close低于/高于 MA,则使用牛市/熊市颜色。
bgColor = close > ma ? open < ma ? neutColorInput : bullColorInput : open > ma ? neutColorInput : bearColorInput
// 右栏中的 MA 值。
table.cell(panel, 1, i, str.tostring(ma, format.mintick), text_color = color.black, bgcolor = bgColor)
period += masStepInput
请注意:
l 用户可以从输入中选择表格的位置,以及右栏单元格背景使用的牛/熊/中性色。
l 表格的行数由用户选择显示的 MA 数量决定。我们为列标题添加一行。
l 尽管我们只在最后一K线填充表格单元格,但我们需要在每一K线执行对 ta.sma() 的调用,这样才能产生正确的结果。编译代码时出现的编译器警告可以忽略不计。
l 我们使用 group 将输入分为两部分,并使用 inline 将相关输入连接到同一行。我们使用工具提示来记录某些字段的限制。
l 显示热图
我们的下一个项目是热图,它将显示当前价格相对于过去价格的牛熊关系。为此,我们在图表底部使用一个表格。我们将只显示颜色,因此表格中将不包含文本;我们只需为单元格的背景着色,即可生成热图。热图使用用户可选的回溯周期。它在该期间内循环,以确定价格是否高于/低于过去的每个K线,并随着时间的推移,显示强度逐渐变浅的牛市/熊市颜色:
//@version=5
indicator("Price vs Past", "", true)
var int MAX_LOOKBACK = 300
int lookBackInput = input.int(150, minval = 1, maxval = MAX_LOOKBACK, step = 10)
color bullColorInput = input.color(#00FF00ff, "Bull", inline = "11")
color bearColorInput = input.color(#FF0080ff, "Bear", inline = "11")
// ————— 函数绘制热图,显示当前 `_src`相对于其过去 `_lookBack` 值的位置。
drawHeatmap(src, lookBack) =>
// float src:已评估的价格序列。
// int lookBack:已评估的过去K线的数量。
// 依赖性: MAX_LOOKBACK
// 强制历史缓冲区达到足够的大小。
max_bars_back(src, MAX_LOOKBACK)
// 只在最后一个K线上运行表格代码。
if barstate.islast
var heatmap = table.new(position.bottom_center, lookBack, 1)
for i = 1 to lookBackInput
float transp = 100. * i / lookBack
if src > src[i]
table.cell(heatmap, lookBack - i, 0, bgcolor = color.new(bullColorInput, transp))
else
table.cell(heatmap, lookBack - i, 0, bgcolor = color.new(bearColorInput, transp))
drawHeatmap(high, lookBackInput)
请注意:
l 将最大回溯周期定义为 MAX_LOOKBACK 常量。这是一个非常重要的值,我们使用它有两个目的:指定我们将在单行表中创建的列数,以及指定函数中 _src 参数所需的回溯周期,这样我们就可以强制 Pine Script® 创建一个历史缓冲区,使我们能够在 for 循环中参考 _src 过去值的所需数量。
l 我们为用户提供了在输入中配置牛/熊颜色的可能性,并使用内联方式将颜色选择放在同一行。
l 在我们的函数中,我们将表格创建代码封装在 if barstate.islast 结构中,以便只在图表的最后一个K线上运行。
l 表格的初始化在 if 语句中完成。因此,加上使用了 var 关键字,初始化只在脚本第一次执行最后一个K线时进行。请注意,这种行为不同于通常在脚本全局范围内的 var 声明,在全局范围内,初始化发生在数据集的第一个条形图上,即 bar_index 为零时。
l 我们在调用 table.cell() 时没有为文本参数指定参数,因此使用的是空字符串。
l 我们计算透明度的方式是,随着时间的推移,颜色的强度会逐渐降低。
l 我们使用动态颜色生成功能,根据需要为基本颜色创建不同的透明度。
l 与 Pine 脚本中显示的其他对象相反,该热图的单元格并不与图表K线相连。配置的回看周期决定了热图包含多少表格单元格,而且热图不会因图表水平平移或缩放而改变。
l scritp 可视空间中可显示的最大单元格数取决于查看设备的分辨率和图表所使用的显示部分。分辨率较高的屏幕和较宽的窗口可以显示更多的表格单元格。
小技巧
l 在策略脚本中创建表格时,请记住,除非策略使用 calc_on_every_tick = true,否则if barstate.islast 块中的表格代码不会在每次实时更新时执行,因此表格不会如您所期望的那样显示。
l 请记住连续调用 table.cell() 会覆盖之前调用 table.cell() 指定的单元格属性。请使用 setter 函数修改单元格的属性。
l 切记明智地控制表格代码的执行,将其限制在必要的K线内。这样既能节省服务器资源,又能加快图表显示速度,一举两得。
简介
Pine Script®可以用五种不同的方式显示文本或图形:
l plotchar()
l plotshape()
l plotarrow()
l 使用 label.new() 创建的标签
l 使用 table.new() 创建表格(参见表格)
使用哪种方法取决于您的需求:
l Tables 可以在图表的不同相对位置显示文本,当用户水平滚动或缩放图表时,文本不会移动。其内容与K线无关。相比之下,使用 plotchar()、plotshape() 或 label.new() 显示的文本总是与特定K线绑定,因此会随着K线在图表上的位置移动。有关表格的更多信息,请参见表格页面。
l 有三个函数可以显示预定义的形状:plotshape()、plotarrow() 和使用 label.new()创建的标签。
l plotarrow()不能显示文本,只能显示向上或向下箭头。
l plotchar()和plotshape()可以在图表的任意条形图或所有条形图上显示非动态(非series形式)文本。
l plotchar() 只能显示一个字符,而 plotshape() 可以显示字符串,包括换行符。
l label.new() 最多可以在图表上显示 500 个标签。其文本可以包含动态文本或 "系列字符串"。标签文本也支持换行。
l plotchar() 和 plotshape() 可以在过去或未来的固定偏移位置显示文本,在脚本执行过程中无法更改,而每次调用 label.new() 时都可以使用一个可以即时计算的series偏移位置。
关于 Pine Script® 字符串,需要注意以下几点:
l 由于 plotchar() 和 plotshape() 中的文本参数都需要一个 "const string "参数,因此不能包含价格等只能在K线("系列字符串")中获知的值。
l 要在使用label.new()显示的文本中包含series值,首先需要使用 str.tostring() 将其转换为字符串。
l Pine中字符串的连接运算符是+。它用于将字符串成分连接成一个字符串,例如msg = "Chart symbol:" + syminfo.tickerid(其中syminfo.tickerid是一个内置变量,以字符串格式返回图表的交易所和交易品种信息)。
l 所有这些函数显示的字符都可以是 Unicode 字符,其中可能包括Unicode符号。请参阅"探索 Unicode 脚本",了解如何使用Unicode字符。
l 有时可以使用函数参数控制文本的颜色或大小,但无法进行内联格式化(粗体、斜体、monospace 等)。
l 来自 Pine 脚本的文本总是以 Trebuchet MS 字体显示在图表上,包括本脚本在内的许多 TradingView 文本都使用这种字体。
该脚本使用 Pine Script® 中可用的四种方法显示文本:
//@version=5
indicator("Four displays of text", overlay = true)
plotchar(ta.rising(close, 5), "`plotchar()`", "��", location.belowbar, color.lime, size = size.small)
plotshape(ta.falling(close, 5), "`plotchar()`", location = location.abovebar, color = na, text = "•`plotshape()•`\n��", textcolor = color.fuchsia, size = size.huge)
if bar_index % 25 == 0
label.new(bar_index, na, "•LABEL•\nHigh = " + str.tostring(high, format.mintick) + "\n��", yloc = yloc.abovebar, style = label.style_none, textcolor = color.black, size = size.normal)
printTable(txt) => var table t = table.new(position.middle_right, 1, 1), table.cell(t, 0, 0, txt, bgcolor = color.yellow)
printTable("•TABLE•\n" + str.tostring(bar_index + 1) + " bars\nin the dataset")
请注意:
l 用于显示每个文本字符串的方法与文本一起显示,但使用 plotchar() 显示的石灰向上箭头除外,因为它只能显示一个字符。
l Label 和表格调用可以插入条件结构以控制其执行时间,而 plotchar() 和 plotshape() 则不能。它们的条件绘图必须使用第一个参数来控制,该参数是一个 "系列 bool",其真假值决定何时显示文本。
l 表格和标签中显示的数值首先使用 str.tostring() 转换为字符串。
l 我们使用 + 运算符来连接字符串组件。
l plotshape() 用于显示带有文字的形状。它的 size 参数控制形状的大小,而不是文字的大小。我们使用 na 作为其颜色参数,这样形状就不可见了。
l 与其他文本相反,表格文本不会随着滚动或缩放图表而移动。
l 某些文本字符串包含 �� Unicode 箭头 (U+1F807)。
l 某些文本字符串包含表示新行的 ��序列。
该函数用于在K线上显示单个字符。其语法如下:
plotchar(series, title, char, location, color, offset, text, textcolor, editable, size, show_last, display) → void
有关其参数的详细信息,请参阅《参考手册》中 plotchar() 的进场。
正如我们的调试页面的 "当必须保留脚本的刻度时 "部分所述,该函数可用于显示和检查数据窗口中的值,或图表中脚本名称右侧显示的指标值:
//@version=5
indicator("", "", true)
plotchar(bar_index, "Bar index", "", location.top)
请注意:
l 光标位于图表的最后一个K线。
l 该条上的 bar_index 值会显示在指标值 (1) 和数据窗口 (2) 中。
l 我们使用 location.top,因为默认的 location.abovebar 会在脚本的刻度中显示价格,这通常会干扰其他图表。
plotchar()还能很好地识别图表上的特定点,或验证我们预期的条件是否为真。本示例在close、high和成交量均连续两格上涨的K线下显示一个向上箭头:
//@version=5
indicator("", "", true)
bool longSignal = ta.rising(close, 2) and ta.rising(high, 2) and (na(volume) or ta.rising(volume, 2))
plotchar(longSignal, "Long", "▲", location.belowbar, color = na(volume) ? color.gray : color.blue, size = size.tiny)
请注意:
l 我们使用(na(volume)或ta.rising(volume,2)),因此我们的脚本可以在没有成交量数据的符号上运行。如果我们不对没有成交量数据的情况做出规定(na(volume)的作用就是在没有成交量的情况下为真),那么longSignal变量的值就永远不会为真,因为在这些情况下ta.rising(volume, 2)的结果是假的。
l 当没有成交量时,我们将箭头显示为灰色,以提醒我们三个基本条件都不满足。
l 由于 plotchar() 现在要在图表上显示一个字符,因此我们使用 size = size.tiny 来控制其大小。
l 我们调整了位置参数,以便在K线下显示字符。
如果不介意只绘制圆形,也可以使用 plot() 达到类似效果:
//@version=5
indicator("", "", true)
longSignal = ta.rising(close, 2) and ta.rising(high, 2) and (na(volume) or ta.rising(volume, 2))
plot(longSignal ? low - ta.tr : na, "Long", color.blue, 2, plot.style_circles)
这种方法的不便之处在于,由于 plot() 没有相对定位机制,因此必须使用类似 ta.tr(K 线的 "真实范围")的方法将圆向下移动:
`plotshape()`
该函数用于在K线上显示预定义的形状and/or文本。其语法如下
plotshape(series, title, style, location, color, offset, text, textcolor, editable, size, show_last, display) → void
有关其参数的详细信息,请参见《参考手册》中plotshape()的进场。
让我们使用该函数来实现与上一节第二个示例大致相同的结果:
//@version=5
indicator("", "", true)
longSignal = ta.rising(close, 2) and ta.rising(high, 2) and (na(volume) or ta.rising(volume, 2))
plotshape(longSignal, "Long", shape.arrowup,location.belowbar)
请注意,这里我们使用的样式参数不是箭头字符,而是shape.arrowup参数。
可以使用不同的 plotshape()调用在K线上叠加文本。你需要在 \n 后跟一个特殊的非打印字符,该字符不会被删除,以保留换行的功能。这里我们使用的是一个Unicode零宽度空格(U+200E)。虽然在下面的代码字符串中看不到它,但它是存在的,可以复制/粘贴。当文本向上移动时,该特殊Unicode字符需要位于字符串的最后一个;当在K线下绘图且文本向下移动时,该特殊Unicode字符需要位于字符串的第一个:
//@version=5
indicator("Lift text", "", true)
plotshape(true, "", shape.arrowup, location.abovebar, color.green, text = "A")
plotshape(true, "", shape.arrowup, location.abovebar, color.lime, text = "B\n")
plotshape(true, "", shape.arrowdown, location.belowbar, color.red, text = "C")
plotshape(true, "", shape.arrowdown, location.belowbar, color.maroon, text = "\nD")
可与样式参数一起使用的形状有:
plotarrow()`
plotarrow 函数根据函数第一个参数中使用的序列的相对值,显示长度可变的向上或向下箭头。其语法如下:
plotarrow(series, title, colorup, colordown, offset, minheight, maxheight, editable, show_last, display) →void
有关 plotarrow() 参数的详细信息,请参见《参考手册》中的 plotarrow() 进场。
plotarrow() 中的 series 参数不是 plotchar() 和 plotshape() 中的 "series bool";它是一个 "series int/float",而且它不仅仅是一个决定何时绘制箭头的简单真假值。这是控制提供给 series 的参数如何影响 plotarrow() 行为的逻辑:
l series > 0:显示向上箭头,其长度与该K线上的序列相对于其他序列的相对值成正比。
l series < 0:显示向下箭头,大小与规则相同。
l series == 0 或 na(系列): 不显示箭头。
可以使用 minheight 和 maxheight 参数控制箭头的最大和最小尺寸(以像素为单位)。
下面是一个简单的脚本,说明plotarrow()如何工作:
//@version=5
indicator("", "", true)
body = close - open
plotarrow(body, colorup = color.teal, colordown = color.orange)
请注意箭头的高度与K线体的相对大小成正比。
您可以使用任何序列来绘制箭头。在这里,我们使用“Chaikin Oscillator”的值来控制箭头的位置和大小:
//@version=5
indicator("Chaikin Oscillator Arrows", overlay = true)
fastLengthInput = input.int(3, minval = 1)
slowLengthInput = input.int(10, minval = 1)
osc = ta.ema(ta.accdist, fastLengthInput) - ta.ema(ta.accdist, slowLengthInput)
plotarrow(osc)
请注意,我们在图表下方的窗格中显示了实际的“Chaikin Oscillator”,因此您可以看到用于确定箭头位置和大小的值。
标签
标签仅适用于Pine Script® v4及更高版本。它们的工作原理与plotchar()和plotshape()截然不同。
标签是一种对象,就像线条、方框或表格一样。与它们一样,标签也使用一个ID,这个ID就像一个指针。标签ID属于"label类型。与其他对象一样,标签ID也是"时间序列",所有用于管理标签的函数都接受"series"参数,因此非常灵活。
注意事项
在 TradingView 图表中,一整套绘图工具允许用户使用鼠标操作创建和修改绘图。虽然它们有时看起来与使用Pine Script®代码创建的绘图对象相似,但它们是毫不相关的实体。使用Pine代码创建的绘图对象无法通过鼠标操作进行修改,而Pine脚本也无法看到图表用户界面中的手绘绘图。
标签的优势在于:
l 允许将series值转换为文本并放置在图表上。这意味着它们非常适合用于显示无法预先知道的值,如价格值、支撑位和阻力位,以及脚本计算的任何其他值。
l 与 plot*() 函数相比,它们的定位选项更加灵活。
l 它们提供更多显示模式。
l 与 plot*() 函数相反,标签处理函数可以插入到条件或循环结构中,从而更容易控制其行为。
l 可以为标签添加工具提示。
与 plotchar() 和 plotshape() 相比,使用标签的一个缺点是只能在图表上绘制有限数量的标签。默认值为 ~50,但可以在指标()或策略()声明语句中使用 max_labels_count 参数,指定最多 500 个。标签与线条和方框一样,使用垃圾回收机制进行管理,该机制会删除图表上最旧的标签,因此只有最近绘制的标签才可见。
用于管理标签的内置工具箱都在标签命名空间中。包括:
l label.new() 用于创建标签。
l label.set_*() 函数用于修改现有标签的属性。
l label.get_*() 函数用于读取现有标签的属性。
l label.delete() 用于删除标签
l The label.all 数组始终包含图表上所有可见标签的 ID。数组的大小取决于脚本的最大标签数和绘制的标签数量。aray.size(label.all) 将返回数组的大小。
创建和修改标签
label.new() 函数创建一个新标签。其签名如下:
label.new(x, y, text, xloc, yloc, color, style, textcolor, size, textalign, tooltip) → series label
允许更改标签属性的设置函数有:
它们都有类似的签名。label.set_color()的签名是:
label.set_color(id, color) → void
其中:
l id 是要修改属性的标签 ID。
l 下一个参数是要修改的标签属性。label.set_xy()修改了两个属性,因此有两个这样的参数。
这就是创建标签的最简单方法:
//@version=5
indicator("", "", true)
label.new(bar_index, high)
请注意:
l 标签是用参数 x = bar_index(当前K线的索引,bar_index)和 y = high(该K线的最高值)创建的。
l 不为函数的文本参数提供参数。其默认值为空字符串,因此不会显示任何文本。
l 我们的标签.new()调用不受任何逻辑控制,因此每个K线都会创建标签。
l 由于我们的 indicator()调用没有使用 max_labels_count 参数指定 ~50 默认值以外的其他值,因此只显示最后 54 个标签。
l 标签会一直存在于K线中,直到脚本使用 label.delete() 将其删除,或者垃圾回收将其移除。
在下一个示例中,我们将在最近 50 个K线中最高值的条形图上显示一个标签:
//@version=5
indicator("", "", true)
//找出最近 50 条K线中的最高 "high "值及其偏移量。将其符号改为正数。
LOOKBACK = 50
hi = ta.highest(LOOKBACK)
highestBarOffset = - ta.highestbars(LOOKBACK)
//只在零号K线上创建标签。
var lbl = label.new(na, na, "", color = color.orange, style = label.style_label_lower_left)
// 发现新的高点后,将标签移动到该高点,并更新其文本和工具提示。
if ta.change(hi)
// 创建标签和工具提示字符串。
labelText = "High: " + str.tostring(hi, format.mintick)
tooltipText = "Offest in bars: " + str.tostring(highestBarOffset) + "\nLow: " + str.tostring(low[highestBarOffset], format.mintick)
// 更新标签的位置、文本和工具提示。
label.set_xy(lbl, bar_index[highestBarOffset], hi)
label.set_text(lbl, labelText)
label.set_tooltip(lbl, tooltipText)
请注意:
l 仅通过使用 var 关键字声明包含标签 ID 的 lbl 变量,在第一个K线上创建标签。调用 label.new() 时的 x、y 和 text 参数无关紧要,因为标签将在以后的K线中更新。不过,我们会注意为标签使用我们想要的颜色和样式,这样以后就不需要更新了。
l 在每个K线中,我们都会通过检测 hi 值的变化来检测是否出现了新高。
l 当高点值发生变化时,我们就用新信息更新标签。为此,我们使用三次 label.set*()调用来更改标签的相关信息。我们使用包含标签 ID 的 lbl 变量来引用标签。因此,脚本在所有K线中都保持同一个标签,但在检测到新高时会移动标签并更新其信息。
在这里,我们在每个K线上创建一个标签,但根据K线的极性有条件地设置其属性:
//@version=5
indicator("", "", true)
lbl = label.new(bar_index, na)
if close >= open
label.set_text( lbl, "green")
label.set_color(lbl, color.green)
label.set_yloc( lbl, yloc.belowbar)
label.set_style(lbl, label.style_label_up)
else
label.set_text( lbl, "red")
label.set_color(lbl, color.red)
label.set_yloc( lbl, yloc.abovebar)
label.set_style(lbl, label.style_label_down)
定位标签
标签根据x(K线)和y(价格)标在图表上定位。有五个参数会影响这种行为:x、y、xloc、yloc和style:
x
是条形图索引或时间值。使用条形图索引时,该值可以偏移过去或未来(最多偏移未来 500 条)。使用时间值时,也可以计算过去或未来的偏移量。现有标签的 x 值可以使用 label.set_x() 或 label.set_xy() 进行修改。
xloc
是 xloc.bar_index(默认值)或 xloc.bar_time。对于 xloc.bar_index,x 必须是绝对的K线索引。如果使用 xloc.bar_time,x 必须是一个 UNIX time(以毫秒为单位),与K线打开的时间值相对应。现有标签的 xloc 值可以使用 label.set_xloc() 进行修改。
y
是标签所在位置的价格水平。只有默认yloc值为 yloc.price 时才会考虑该值。如果yloc为yloc.aboveba 或yloc.belowbar,则忽略y参数。现有标签的y值可以使用label.set_y()或label.set_xy()进行修改。
yloc
可以是yloc.price(默认值)、yloc.abovebar或yloc.belowbar。只有在使用yloc.price时才会考虑y的参数。现有标签的yloc值可以使用label.set_yloc()进行修改。
style样式
当使用 yloc.abovebar 或 yloc.belowbar 时,使用的参数会影响标签的视觉外观以及相对于由 y 值或K线顶部/底部决定的参考点的位置。现有标签的样式可以使用 label.set_style() 进行修改。
这些是可用的样式参数:

使用xloc.bar_time时,x必须是以毫秒为单位的UNIX时间戳。更多信息请参阅时间页面。当前K线的开始时间可以从time内置变量中获取。之前K线的开始时间为time[1]、time[2],以此类推。还可以使用时间戳功能将时间设置为绝对值。您可以增加或减少时间段来实现相对时间偏移。
从上一K线的日期开始定位一天前的标签:
//@version=5
indicator("")
daysAgoInput = input.int(1, tooltip = "Use negative values to offset in the future")
if barstate.islast
MS_IN_ONE_DAY = 24 * 60 * 60 * 1000
oneDayAgo = time - (daysAgoInput * MS_IN_ONE_DAY)
label.new(oneDayAgo, high, xloc = xloc.bar_time, style = label.style_label_right)
请注意,由于时间间隙不同以及市场休市时缺少K线,标签的定位不一定总是准确的。这种时间偏移在24x7市场上往往更可靠。
您也可以使用K线指数来偏移 x 值,例如:
label.new(bar_index + 10, high)
label.new(bar_index - 10, high[10])
label.new(bar_index[10], high[10])
读取标签属性
以下获取器函数可用于标签:
它们都有类似的签名。label.get_text() 的签名是:
label.get_text(id) → series string
其中 id 是要检索文本的标签。
复制标签
label.copy() 函数用于克隆标签。其语法如下:
label.copy(id) → void
删除标签
label.delete() 函数用于删除标签。其语法如下:
label.delete(id) → void
要在图表上只保留用户定义数量的标签,可以使用类似这样的代码:
//@version=5
MAX_LABELS = 500
indicator("", max_labels_count = MAX_LABELS)
qtyLabelsInput = input.int(5, "Labels to keep", minval = 0, maxval = MAX_LABELS)
myRSI = ta.rsi(close, 20)
if myRSI > ta.highest(myRSI, 20)[1]
label.new(bar_index, myRSI, str.tostring(myRSI, "#.00"), style = label.style_none)
if array.size(label.all) > qtyLabelsInput
label.delete(array.get(label.all, 0))
plot(myRSI)
请注意:
l 定义了 MAX_LABELS 常量,用于保存脚本可容纳的最大标签数量。我们使用该值设置 indicator() 调用中的 max_labels_count 参数值,并将其作为 input.int() 调用中的 maxval 值,以限制用户值。
l 在 RSI 突破过去 20 个K线的最高值时创建一个新标签。注意我们在 if myRSI > ta.highest(myRSI, 20)[1] 中使用的偏移量 [1]。这是必要的。如果没有偏移量,ta.highest() 返回的值将始终包括 myRSI 的当前值,因此 myRSI 永远不会高于函数的返回值。
l 之后,我们删除 label.all 数组中最老的标签,该数组由 Pine Script® 运行时自动维护,包含脚本绘制的所有可见标签的 ID。我们使用 array.get() 函数获取索引为零的数组元素(最旧的可见标签 ID)。然后,我们使用 label.delete() 删除与该 ID 相连的标签。
请注意,如果只想在最后一个K线上定位标签,那么创建和删除标签是不必要的,也是无效的,因为脚本会在所有K线上执行,因此只保留最后一个标签:
// 无效的!
//@version=5
indicator("", "", true)
lbl = label.new(bar_index, high, str.tostring(high, format.mintick))
label.delete(lbl[1])
这是实现相同任务的有效方法:
//@version=5
indicator("", "", true)
if barstate.islast
// 创建一次标签,即在最后一个K线执行块的第一次。
var lbl = label.new(na, na)
// 在最后一个K线的所有脚本迭代中,更新标签的信息。
label.set_xy(lbl, bar_index, high)
label.set_text(lbl, str.tostring(high, format.mintick))
实时行为
标签会受到提交和回滚动作的影响,这两个动作会影响脚本在实时K线中执行时的行为。请参阅 Pine Script® 的执行模型页面。
本脚本演示了在实时栏中运行时回滚的效果:
//@version=5
indicator("", "", true)
label.new(bar_index, high)
在实时条形图上,label.new() 会在每次脚本更新时创建一个新标签,但由于回滚过程的存在,同一条形图上上次更新时创建的标签会被删除。只有在实时K线收盘前创建的最后一个标签才会被提交,从而持续存在。
时间
导言
四种参照
在 Pine Script® 中使用日期和时间值时,有四种不同的参照:
1.UTC时区:Pine Script®中时间值的本地格式是以毫秒为单位的Unix时间。Unix时间是从1970年1月1日Unix纪元开始计算的时间。有关以秒为单位的当前Unix时间,请参见此处;有关Unix时间的更多信息,请参见此处。Unix时间的值称为时间戳。Unix时间戳总是以UTC(或"GMT",或"GMT+0")时区表示。时间戳是从一个固定的参考点(即Unix时区)开始测量的,不会随时区而变化。一些内置程序使用UTC时区作为参考。
2.交易所时区: 对于交易者来说,第二个与时间相关的关键参考是交易工具所在交易所的时区。一些内置程序默认以交易所时区返回小时值。
3.时区参数: 一些函数(如 hour())通常以交易所时区返回值,其中包含一个时区参数,允许您将函数结果调整为其他时区。其他函数(如 time())同时包含交易时段和时区参数。在这种情况下,时区参数适用于交易时段参数的解释方式,而不是函数返回的时间值。
4.Chart 的时区: 这是用户使用 "图表设置/符号/时区 "字段从图表中选择的时区。该设置只影响图表上日期和时间的显示。它不会影响 Pine 脚本的行为,而且它们对该设置也没有可见性。
在讨论变量或函数时,我们会注意它们是否以 UTC 或交换时区返回日期或时间。脚本无法查看用户在图表上的时区设置。
内置时间
Pine Script®内置了以下变量:
l 获取当前K线的时间戳信息(UTC 时区):time 和 time_close
l 获取当前交易日开始的时间戳信息(UTC 时区):time_tradingday
l 以一秒为增量获取当前时间(UTC 时区):timenow
l 从K线获取日历和时间值(交换时区):年、月、年之周、月之日、周之日、小时、分钟和秒
l 使用 syminfo.timezone 返回图表符号的交易所时区
还有一些内置函数可以
l 使用 time() 和 time_close()从其他时间框架返回K线的时间戳,无需调用 request.security()
l 从任何时间戳中检索日历和时间值,这些值可与时区偏移:年()、月()、年之周()、月之日()、周之日()、小时()、分钟()和秒()
l 使用 timestamp() 创建时间戳
l 使用 str.format()将时间戳转换为格式化的日期/时间字符串以便显示
l 输入数据和时间值。请参阅 "输入 "部分。
l 处理交易时段信息。
时区
TradingViewer可以更改用于在图表上显示K线的时区。Pine脚本对此设置为不可见。虽然有一个syminfo.timezone变量可以返回图表交易工具所在交易所的时区,但却没有与之对应的chart.timezone。
在图表上显示时间时,这就为用户提供了一种将脚本时间值调整为图表时间值的方法。这样,您显示的时间就能与交易者在图表上使用的时区相匹配:
//@version=5
indicator("Time zone control")
MS_IN_1H = 1000 * 60 * 60
TOOLTIP01 = "Enter your time zone's offset (+ or −), including a decimal fraction if needed."
hoursOffsetInput = input.float(0.0, "Timezone offset (in hours)", minval = -12.0, maxval = 14.0, step = 0.5, tooltip = TOOLTIP01)
printTable(txt) =>
var table t = table.new(position.middle_right, 1, 1)
table.cell(t, 0, 0, txt, text_halign = text.align_right, bgcolor = color.yellow)
msOffsetInput = hoursOffsetInput * MS_IN_1H
printTable(
str.format("Last bar''s open time UTC: {0,date,HH:mm:ss yyyy.MM.dd}", time) +
str.format("\nLast bar''s close time UTC: {0,date,HH:mm:ss yyyy.MM.dd}", time_close) +
str.format("\n\nLast bar''s open time EXCHANGE: {0,date,HH:mm:ss yyyy.MM.dd}", time(timeframe.period, syminfo.session, syminfo.timezone)) +
str.format("\nLast bar''s close time EXCHANGE: {0,date,HH:mm:ss yyyy.MM.dd}", time_close(timeframe.period, syminfo.session, syminfo.timezone)) +
str.format("\n\nLast bar''s open time OFFSET ({0}): {1,date,HH:mm:ss yyyy.MM.dd}", hoursOffsetInput, time + msOffsetInput) +
str.format("\nLast bar''s close time OFFSET ({0}): {1,date,HH:mm:ss yyyy.MM.dd}", hoursOffsetInput, time_close + msOffsetInput) +
str.format("\n\nCurrent time OFFSET ({0}): {1,date,HH:mm:ss yyyy.MM.dd}", hoursOffsetInput, timenow + msOffsetInput))
l 我们使用msOffsetInput将以小时为单位的用户偏移量转换为毫秒。然后,我们将偏移量添加到UTC格式的时间戳中,再将其转换为显示格式,例如time + msOffsetInput 和 timenow + msOffsetInput。
l 我们使用工具提示为用户提供说明。
l 我们提供了 minval 和 maxval 值来保护输入字段,并提供了 0.5 的step值,这样当用户使用字段的向上/向下箭头时,就能直观地发现可以使用小数。
l str.format()函数格式化了我们的时间值,即上一K线的时间和当前时间。
有些函数通常以交易所所在的时区返回值,这些函数提供了通过时区参数将结果调整到其他时区的方法。本脚本说明了如何使用 hour() 实现这一功能:
//@version=5
indicator('`hour(time, "GMT+0")` in orange')
color BLUE_LIGHT = #0000FF30
plot(hour, "", BLUE_LIGHT, 8)
plot(hour(time, syminfo.timezone))
plot(hour(time, "GMT+0"),"UTC", color.orange)
请注意:
l hour变量和hour()函数通常返回交易所时区的值。因此,hour和hour(time,syminfo.timezone)的蓝色图重叠。因此,如果需要交易所的小时,使用带有syminfo.timezone的函数形式是多余的。
l 但是绘制hour(time, "GMT+0")的橙色线返回的是条形图在UTC或"GMT+0"时间的小时数,在本例中比交易所时间少4小时,因为MSFT在纳斯达克交易,而纳斯达克的时区是UTC-4。
时区字符串
在time()、timestamp()、hour()等函数中,用于时区参数的参数可以是不同的格式,您可以在 IANA 时区数据库名称参考页面中找到这些格式。可以使用该页面表格中“时区数据库名称”、“UTC偏移量±hh:mm”和“UTC DST偏移量±hh:mm”列的内容。
要表示UTC+5.5小时的偏移量,参考页面中的这些字符串都是等价的:
· "GMT+05:30"
· "Asia/Calcutta" -"亚洲/加尔各答"
· "Asia/Colombo" -"亚洲/科伦坡"
· "Asia/Kolkata" -"亚洲/加尔各答"
非分数偏移可以用 "GMT+5 "形式表示。不允许使用 "GMT+5.5"。
时间变量
time和time_close
让我们先绘制time和time_close,即K线开盘和收盘时间的Unix时间戳(以毫秒为单位):
//@version=5
indicator("`time` and `time_close` values on bars")
plot(time, "`time`")
plot(time_close, "`time_close`")
l The time 和 time_close 变量返回 UNIX time的时间戳,与用户在图表上选择的时区无关。在这种情况下,图表的时区设置是交易所时区,因此无论图表上的符号是什么,其交易所时区都将用于显示图表光标上的日期和时间值。纳斯达克的时区是 UTC-4,但这只影响图表显示日期/时间值,并不影响脚本绘制的值。
l 刻度中显示的绘图最后时间值是从1970年1月1日00:00:00 UTC开始到K线开盘时间所经过的毫秒数。它对应于2021年9月27日17:30。然而,由于图表使用UTC-4时区(纳斯达克时区),它显示的时间是13:30,比UTC时间早四个小时。
l 因为我们是在1H 图表上,所以最后一个K线上两个数值的差值是一小时内的毫秒数(1000 * 60 * 60 = 3,600,000)。
time_tradingday(tradingday时间)在符号的隔夜交易时段交易时非常有用,因为这些交易时段在不同的日历日开始和结束。例如,在外汇市场上,交易时段可能在周日17:00开始,周一17:00结束。
在1D及以下的时间框架中使用时,变量会以UNIX time返回交易日开始的时间。在高于1D的时间框架使用时,它将返回K线中最后一个交易日的开始时间(例如,在1W时,它将返回本周最后一个交易日的开始时间)。
timenow以UNIX time为单位返回当前时间。它不仅在实时情况下有效,在脚本执行历史K线时也同样有效。在实时情况下,脚本只有在更新时才会感知到变化。没有更新时,脚本处于空闲状态,因此无法更新显示内容。更多信息,请参阅Pine Script®的执行模型页面。
该脚本使用timenow和time_close的值来计算日内K线的实时倒计时。与图表上的倒计时不同,这个倒计时只有在进给更新导致脚本执行另一次迭代时才会更新:
//@version=5
indicator("", "", true)
printTable(txt) =>
var table t = table.new(position.middle_right, 1, 1)
table.cell(t, 0, 0, txt, text_halign = text.align_right, bgcolor = color.yellow)
printTable(str.format("{0,time,HH:mm:ss.SSS}", time_close - timenow))
日历日期和时间
日历日期和时间变量(如year, month, weekofyear, dayofmonth, dayofweek, hour, minute和second )可用于测试特定日期或时间,也可用作 timestamp() 的参数。
测试特定日期或时间时,需要考虑到时间框架可能无法检测到测试条件,或者不存在符合特定要求的K线。例如,我们想检测每月的第一个交易日。该脚本显示了在使用周线图或每月1日不进行交易时,仅使用dayofmonth是如何不起作用的:
//@version=5
indicator("", "", true)
firstDayIncorrect = dayofmonth == 1
firstDay = ta.change(time("M"))
plotchar(firstDayIncorrect, "firstDayIncorrect", "•", location.top, size = size.small)
bgcolor(firstDay ? color.silver : na)
请注意:
l 使用 ta.change(time("M"))更稳健,因为它对所有月份都有效(#1和#2),显示为银色背景,而使用dayofmonth==1 检测到的蓝点在 9 月份的第一个交易日为 2 日时不起作用(#1)。
l Dayofmonth == 1 条件在每月 1 日的所有区间都为真,但 ta.change(time("M"))只在第一个区间为真。
如果您希望脚本只显示2020年及以后的时间,可以使用:
//@version=5
indicator("", "", true)
plot(year >= 2020 ? close : na, linewidth = 3)
syminfo.timezone()
syminfo.timezone 返回图表符号所在交易所的时区。当函数中有timezone参数时,如果想明确说明使用的是交易所的时区,使用该参数会很有帮助。这通常是多余的,因为如果没有为timezone提供参数,则会假定使用交易所的时区。
时间函数
time()和time_close()
time()和time_close()函数的签名如下:
time(timeframe, session, timezone) → series int
time_close(timeframe, session, timezone) →series int
它们接受三个参数:
timeframe时间框架
时间框架格式的字符串。
session交易时段
交易时段规范格式的可选字符串: "hhmm-hhmm[:days]",其中[:days]部分为可选项。更多信息请参阅交易时段页面。
timezone时区
可选值,用于限定交易时段参数的交易时段。
更多信息,请参见《参考手册》中的time()和time_close()。
time()函数最常用于:
1.测试某一K线是否处于特定时段,这就需要使用交易时段参数。在这种情况下,通常会使用timeframe.period,即图表的时间框架作为第一个参数。这样使用函数时,当K线不属于交易时段参数中指定的时段时,我们可以依靠函数返回na。
2.通过使用更高的时间框架作为时间框架参数来检测比图表的时间框架更高的时间框架的变化。为此使用该函数时,我们要寻找返回值的变化,这意味着较高时间框架的K线发生了变化。这通常需要使用ta.change()进行测试,例如,ta.change(time("D"))将返回新的较高时间框架条形图出现时的时间变化,因此在条件表达式中使用时,表达式的结果将被转换为"bool"值。当出现变化时,"bool"值将为true,而当没有变化时,"bool"值将为false。
l 交易时段测试
让我们来看第一个案例的示例,我们想确定K线的起始时间是否属于11:00到13:00之间的时段:
//@version=5
indicator("Session bars", "", true)
inSession = not na(time(timeframe.period, "1100-1300"))
bgcolor(inSession ? color.silver : na)
请注意:
l 使用 time(timeframe.period, "1100-1300"),该函数表示:“如果当前K线的开盘时间在11:00至13:00之间(包括11:00和13:00),则检查图表的时间框架”。如果条形图在交易时段内,函数将返回其开盘时间。如果不在交易时段中,函数将返回na。
l 我们感兴趣的是识别time()不返回na的情况,因为这意味着K线在交易时段内,因此我们测试not na(...)。当time()不返回na时,我们不会使用它的实际返回值;我们只对它是否返回na感兴趣。
l 测试更高时间框架的变化
检测更高的时间框架内的变化通常很有帮助。例如,您可能想在日内图表中检测交易日的变化。在这种情况下,您可以使用time("D") 返回1DK线的开盘时间这一事实,即使图表处于1H等日内时间框架:
//@version=5
indicator("", "", true)
bool newDay = ta.change(time("D"))
bgcolor(newDay ? color.silver : na)
newExchangeDay = ta.change(dayofmonth)
plotchar(newExchangeDay, "newExchangeDay", "��", location.top, size = size.small)
请注意:
l The newDay变量检测1DK线开盘时间的变化,因此它遵循图表符号的约定,使用17:00至17:00的隔夜交易时段。当有新的交易时段出现时,它就会改变值。
l 因为newExchangeDay会检测日历日中月日的变化,所以当图表上的日发生变化时,它也会发生变化。
l 只有在没有交易的日子里,这两种变化检测方法才会在图表上重合。例如这里的周日,两种检测方法都会检测到变化,因为日历日从最后一个交易日(周五)变为新一周的第一个日历日,即周日,此时周一的隔夜交易时段从17:00开始。
日历日期和时间函数
日历日期和时间函数(如year()、month()、weekofyear()、dayofmonth()、dayofweek()、hour()、minute()和second())可用于测试特定日期或时间。它们的签名都与这里显示的dayofmonth()类似:
dayofmonth(time) → series int
dayofmonth(time, timezone) → series int
这将绘制出2021年1月1日00:00时间位于其time和time_close值之间的K线开盘日:
//@version=5
indicator("")
exchangeDay = dayofmonth(timestamp("2021-01-01"))
plot(exchangeDay)
该值将是31日或1日,具体取决于图表符号交易时段开放的日历日。在使用UTC时区的交易所24x7交易的符号,日期为1号。对于在UTC-4时区交易所交易的商品,日期将是31日。
timestamp()
timestamp()函数有几种不同的签名:
timestamp(year, month, day, hour, minute, second) → simple/series int
timestamp(timezone, year, month, day, hour, minute, second) → simple/series int
timestamp(dateString) → const int
前两个参数的唯一区别是时区参数。其默认值为syminfo.timezone。有关有效值,请参阅本页的时区字符串部分。
第三种形式在input.time()中用作defval值。更多信息,请参阅《参考手册》中的timestamp()进场。
timestamp()用于生成特定日期的时间戳。要生成2021年1月1日的时间戳,请使用以下方法:
//@version=5
indicator("")
yearBeginning1 = timestamp("2021-01-01")
yearBeginning2 = timestamp(2021, 1, 1, 0, 0)
printTable(txt) => var table t = table.new(position.middle_right, 1, 1), table.cell(t, 0, 0, txt, bgcolor = color.yellow)
printTable(str.format("yearBeginning1: {0,date,yyyy.MM.dd hh:mm}\nyearBeginning2: {1,date,yyyy.MM.dd hh:mm}", yearBeginning1, yearBeginning1))
您可以在timestamp()参数中使用偏移量。在这里,我们用日期参数提供的值减去2,得到两天前图表最后一个K线的日期/时间。需要注意的是,由于各种工具的K线排列方式不同,虽然函数的返回值是正确的,但图表上标识的K线不一定总是48小时前的:
//@version=5
indicator("")
twoDaysAgo = timestamp(year, month, dayofmonth - 2, hour, minute)
printTable(txt) => var table t = table.new(position.middle_right, 1, 1), table.cell(t, 0, 0, txt, bgcolor = color.yellow)
printTable(str.format("{0,date,yyyy.MM.dd hh:mm}", twoDaysAgo))
格式化日期和时间
时间戳可以使用str.format()格式化。以下是各种格式的示例:
//@version=5
indicator("", "", true)
print(txt, styl) =>
var alignment = styl == label.style_label_right ? text.align_right : text.align_left
var lbl = label.new(na, na, "", xloc.bar_index, yloc.price, color(na), styl, color.black, size.large, alignment)
if barstate.islast
label.set_xy(lbl, bar_index, hl2[1])
label.set_text(lbl, txt)
var string format =
"{0,date,yyyy.MM.dd hh:mm:ss}\n" +
"{1,date,short}\n" +
"{2,date,medium}\n" +
"{3,date,long}\n" +
"{4,date,full}\n" +
"{5,date,h a z (zzzz)}\n" +
"{6,time,short}\n" +
"{7,time,medium}\n" +
"{8,date,'Month 'MM, 'Week' ww, 'Day 'DD}\n" +
"{9,time,full}\n" +
"{10,time,hh:mm:ss}\n" +
"{11,time,HH:mm:ss}\n" +
"{12,time,HH:mm:ss} Left in bar\n"
print(format, label.style_label_right)
print(str.format(format,
time, time, time, time, time, time, time,
timenow, timenow, timenow, timenow,
timenow - time,time_close - timenow),label.style_label_left)
时间框架
简介
时间框架也称为间隔或分辨率,是图表上一个K线所代表的时间单位。所有标准图表类型都使用时间框架:“Bars”, “Candles”, “Hollow Candles”, “Line”, “Area”和“Baseline”。有一种非标准图表类型也使用时间框架:"Heikin Ashi"。
有兴趣从多个时间框架访问数据的程序员需要熟悉Pine Script®中如何表达时间框架,以及如何使用。
时间框架字符串会在不同的情况下发挥作用:
l 从其他商品或时间框架请求数据时,必须在 request.security()中使用。请参阅其他时间框架和数据页面,了解request.security()的使用。
l 它们可用作time()和time_close()函数的参数,以返回较高时间框架的K线时间。这反过来又可用于从图表的时间框架检测更高时间框架的变化,而无需使用 request.security()。请参阅“测试更高时间框架的变化”部分了解如何做到这一点。
l input.timeframe()函数提供了一种方法,允许脚本用户通过脚本的 "输入"选项卡定义时间框架(更多信息请参阅 "时间框架输入"部分)。
l indicator()声明语句有一个可选的时间框架参数,可用于为简单脚本提供多时间框架功能,而无需使用 request.security()。
l 许多内置变量都提供了脚本运行的图表所使用的时间框架信息。有关它们的更多信息,请参阅图表时间框架部分,其中包括以Pine Script®的时间框架规范格式返回字符串的timeframe.period。
时间框架字符串遵循以下规则:·
l 它们由乘数和时间框架单位组成,例如"1S"、"30"(30 分钟)、"1D"(一天)、"3M"(三个月)。
l 单位用一个字母表示,分钟不用字母:S "表示秒,"D"表示天,"W"表示周,"M"表示月。·
l 不使用乘数时,假定为1。如此,S相当于"1S","D"相当于"1D",等等。如果只使用"1",则解释为 "1min",因为分钟不使用单位字母标识符。·
l 没有"小时"单位;"1H"无效。一小时的正确格式是 "60"(记住分钟不指定单位字母)。·
l 每个时间框架单位的有效乘数各不相同:·
· 对于秒,只有离散的1、5、10、15 和30倍数有效。
· 对于分钟,1 至 1440。
· 对于天,1 至 365。
· 对于周,1 至 52。
· 对于月,1 至 12。
比较不同的时间框架字符串可能很有用,例如,可以确定图表上使用的时间框架是否低于脚本中使用的较高时间框架,因为使用低于图表的时间框架通常不是一个好主意。更多相关信息,请参阅“请求较低时间框架的数据”部分。
将时间框架字符串转换为以分数分钟为单位的表示法,提供了一种使用通用单位进行比较的方法。此脚本使用timeframe.in_seconds()函数将时间框架转换为浮动秒,然后将结果转换为分钟:
//@version=5
indicator("Timeframe in minutes example", "", true)
string tfInput = input.timeframe(defval = "", title = "Input TF")
float chartTFInMinutes = timeframe.in_seconds() / 60
float inputTFInMinutes = timeframe.in_seconds(tfInput) / 60
var table t = table.new(position.top_right, 1, 1)
string txt = "Chart TF: " + str.tostring(chartTFInMinutes, "#.##### minutes") +
"\nInput TF: " + str.tostring(inputTFInMinutes, "#.##### minutes")
if barstate.isfirst
table.cell(t, 0, 0, txt, bgcolor = color.yellow)
else if barstate.islast
table.cell_set_text(t, 0, 0, txt)
if chartTFInMinutes > inputTFInMinutes
runtime.error("The chart's timeframe must not be higher than the input's timeframe.")
请注意:
· 我们使用内置的timeframe.in_seconds()函数将图表和input.timeframe()函数转换为秒,然后除以60转换为分钟。
· 初始化chartTFInMinutes和inputTFInMinutes 时,使用了两次对timeframe.in_seconds()函数的调用。在第一次调用中,我们没有为其时间框架参数提供参数,因此函数返回图表的时间框架(秒)。在第二次调用中,我们提供脚本用户通过调用input.timeframe()选择的时间框架。
· 接下来,我们将验证时间框架,确保输入的时间框架等于或高于图表的时间框架。如果不是,我们就会生成运行时错误。
编写脚本
风格指南
风格指南就如何以标准的方式命名变量和组织Pine脚本提供了建议。遵循我们最佳实践的脚本将更易于阅读、理解和维护。
您可以在平台的TradingView和PineCoders账户中看到使用这些指南发布的脚本。
我们建议使用:
l camelCase用于所有标识符,即变量或函数名称:ma, maFast, maLengthInput, maColor, roundedOHLC(), pivotHi()。
l 大写SNAKE_CASE用于常量: bull_color、bear_color、max_lookback。
l 如果限定后缀能为变量的类型或来源提供有价值的线索,则使用限定后缀:maShowInput、bearColor、bearColorInput、volumesArray、maPlotID、resultsTable、levelsColorArray。
Pine Script® 编译器对脚本中特定语句的位置或版本编译器注释非常宽容。虽然其他排列方式在语法上也是正确的,但我们建议按以下方式组织脚本:
<license>
<version>
<declaration_statement>
<import_statements>
<constant_declarations>
<inputs>
<function_declarations>
<calculations>
<strategy_calls>
<visuals>
<alerts>
如果您在TradingView上公开发布您的开源脚本(也可私下发布脚本),您的开源代码默认受Mozilla许可证保护。您可以选择任何其他许可证。
这些脚本代码的重复使用受我们的《脚本发布规则》管辖,该规则优先于作者的许可证。
脚本开头的标准许可注释为:
// 本源代码受 Mozilla 公共许可证 2.0 条款的约束,网址为 https://mozilla.org/MPL/2.0/。
// © 用户名
这是编译器注释,定义了脚本将使用的 Pine Script® 版本。如果没有,则使用 v1。对于 v5 版本,请使用
//@version=5
这是强制声明语句,用于定义脚本的类型。它必须是对indicator()、strategy()或library()的调用。
如果你的脚本使用了一个或多个 Pine Script® 库,你的导入语句就属于这里。
虽然 Pine Script® 中有“constant”形式,但没有正式的“constant”类型。尽管如此,我们还是使用“constant”来表示符合这些条件的任何类型的变量:
l 它们的初始化使用字面形式(如 100 或 "AAPL")或内置的"const"形式(如 color.green)。
l 它们的值在脚本执行过程中不会改变,这意味着它们的值永远不会使用 := 重新定义。
我们使用 SNAKE_CASE 来命名这些变量,并将它们的声明放在脚本顶部附近。例如:
// ————— 常数
int MS_IN_MIN = 60 * 1000
int MS_IN_HOUR = MS_IN_MIN * 60
int MS_IN_DAY = MS_IN_HOUR * 24
color GRAY = #808080ff
color LIME = #00FF00ff
color MAROON = #800000ff
color ORANGE = #FF8000ff
color PINK = #FF0080ff
color TEAL = #008080ff
color BG_DIV = color.new(ORANGE, 90)
color BG_RESETS = color.new(GRAY, 90)
string RST1 = "No reset; cumulate since the beginning of the chart"
string RST2 = "On a stepped higher timeframe (HTF)"
string RST3 = "On a fixed HTF"
string RST4 = "At a fixed time"
string RST5 = "At the beginning of the regular session"
string RST6 = "At the first visible chart bar"
string RST7 = "Fixed rolling period"
string LTF1 = "Least precise, covering many chart bars"
string LTF2 = "Less precise, covering some chart bars"
string LTF3 = "More precise, covering less chart bars"
string LTF4 = "Most precise, 1min intrabars"
string TT_TOTVOL = "The 'Bodies' value is the transparency of the total volume candle bodies. Zero is opaque, 100 is transparent."
string TT_RST_HTF = "This value is used when '" + RST3 +"' is selected."
string TT_RST_TIME = "These values are used when '" + RST4 +"' is selected.
A reset will occur when the time is greater or equal to the bar's open time, and less than its close time.\nHour: 0-23\nMinute: 0-59"
string TT_RST_PERIOD = "This value is used when '" + RST7 +"' is selected."
l RST* 和 LTF* 常量将用作 input.*() 调用的选项参数中的元组元素。
l TT_* 常量将用作 input.*() 调用中的工具提示参数。请注意我们是如何为长字符串字面量使用续行符的。
l 我们不使用 var 来初始化常量。Pine Script® 的运行时经过优化,可以处理每个K线的声明,但由于 var 变量需要在以后的K线中进行维护,因此仅在首次声明变量时使用 var 来初始化变量,会对脚本性能造成轻微影响。
请注意:
l 在脚本中不止一处使用的字面变量应始终声明为常量。使用常量而不是字面变量,如果给它一个有意义的名称,会使它更易读,而且这种做法也使代码更易于维护。即使一天中毫秒的数量在将来不太可能改变,MS_IN_DAY 也比 1000 * 60 * 60 * 24 更有意义。
l 仅在函数或 if、while 等语句的局部代码块中使用的常数,可以在该局部代码块中声明。
当脚本的所有输入都在同一代码段中时,阅读起来会更容易。将输入放在脚本的开头,即在执行脚本的其他部分之前,也反映了脚本在运行时的处理方式。
在输入变量名后加上输入后缀,在脚本后面使用时更容易识别:maLengthInput、bearColorInput、showAvgInput等。
// ————— Inputs
string resetInput = input.string(RST2, "CVD Resets", inline = "00", options = [RST1, RST2, RST3, RST4, RST5, RST6, RST7])
string fixedTfInput = input.timeframe("D", " Fixed HTF: ", tooltip = TT_RST_HTF)
int hourInput = input.int(9, " Fixed time hour: ", inline = "01", minval = 0, maxval = 23)
int minuteInput = input.int(30, "minute", inline = "01", minval = 0, maxval = 59, tooltip = TT_RST_TIME)
int fixedPeriodInput = input.int(20, " Fixed period: ", inline = "02", minval = 1, tooltip = TT_RST_PERIOD)
string ltfModeInput = input.string(LTF3, "Intrabar precision", inline = "03", options = [LTF1, LTF2, LTF3, LTF4])
所有用户定义的函数必须在脚本的全局范围内定义;Pine Script® 不允许嵌套函数定义。
最佳的函数设计应尽量减少在函数作用域中使用全局变量,因为全局变量会破坏函数的可移植性。在无法避免的情况下,这些函数必须遵循代码中的全局变量声明,这就意味着它们不能总是放在 <function_declarations> 部分。这种对全局变量的依赖最好能在函数注释中记录下来。
记录下函数的对象、参数和结果,会对读者有所帮助。库中使用的语法也可用于记录函数。如果您决定将函数移植到库中,这将使移植变得更加容易。
//@version=5
indicator("<function_declarations>", "", true)
string SIZE_LARGE = "Large"
string SIZE_NORMAL = "Normal"
string SIZE_SMALL = "Small"
string sizeInput = input.string(SIZE_NORMAL, "Size", options = [SIZE_LARGE, SIZE_NORMAL, SIZE_SMALL])
// @function 用于生成内置函数中 `size` 参数的参数。
// @param userSize (简单字符串) 用户选择的大小。
// @returns `size.*` 内置常量之一。
// 依赖关系: size_large, size_normal, size_small
getSize(simple string userSize) =>
result =
switch userSize
SIZE_LARGE => size.large
SIZE_NORMAL => size.normal
SIZE_SMALL => size.small
=> size.auto
if ta.rising(close, 3)
label.new(bar_index, na, yloc = yloc.abovebar, style = label.style_arrowup, size = getSize(sizeInput))
此处应放置脚本的核心计算和逻辑。如果将变量声明放在使用变量的代码段附近,代码会更容易阅读。有些程序员喜欢将所有非常量变量的声明放在这一部分的开头,但这并不总是可行的,因为有些变量可能需要在声明之前执行一些计算。
如果将策略调用归类到脚本的同一部分,则更易于阅读。
理想情况下,这部分应该包括所有产生脚本视觉效果的语句,无论是绘图、图纸、背景颜色、蜡烛图等。关于如何确定视觉效果的相对深度,请参阅《Pine Script®用户手册》的相关章节。
提示代码通常要求脚本的计算在其之前执行,因此将其放在脚本的末尾是合理的。
除单值运算符 (如,-1) 外,所有运算符两侧都应使用空格。在所有逗号后以及使用命名的函数参数时,也建议使用空格,如 plot(series = close)。
int a = close > open ? 1 : -1
var int newLen = 2
newLen := min(20, newlen + 1)
float a = -b
float c = d > e ? d - e : d
int index = bar_index % 2 == 0 ? 1 : 2
plot(close, color = color.red)
换行可以让长行更容易阅读。换行是通过使用非四倍的缩进级别来定义的,因为四个空格或一个制表符用于定义局部块。这里我们使用两个空格:
plot(
series = close,
title = "Close",
color = color.blue,
show_last = 10
)
使用制表符或空格进行垂直对齐,对于包含许多类似行(如常量声明或输入)的代码段非常有用。使用 Pine Script® 编辑器的多光标功能(ctrl + alt + ↑/↓),可以更方便地进行大量编辑:
// Colors used as defaults in inputs.
color COLOR_AQUA = #0080FFff
color COLOR_BLACK = #000000ff
color COLOR_BLUE = #013BCAff
color COLOR_CORAL = #FF8080ff
color COLOR_GOLD = #CCCC00ff
在声明变量时加入变量类型并不是必需的,而且对于小型脚本来说通常是矫枉过正;我们不会系统地使用它。显式类型对于更清楚地说明函数结果的类型,以及区分变量的声明(使用 =)和重赋值(使用 :=)非常有用。使用显式类型还能让读者在较大的脚本中更容易找到方向。
调试
TradingView将Pine Script®编辑器与图表紧密结合,可对Pine Script®代码进行高效的交互式调试。一旦程序员了解了在各种情况下使用的最合适的技术,他们就能快速、彻底地调试脚本。本页展示了调试Pine Script®代码最有用的技术。
如果你还不熟悉Pine Script®的执行模型,请务必阅读本《用户手册》中的执行模型页面,以了解你的调试代码在Pine Script®环境中是如何运行的。
Pine 脚本绘制的数值可以显示在四个不同的位置:
1.脚本名称旁边(由"图表设置>状态线"Chart settings/Status Line选项卡中的Indicator Values"指标>数值"复选框控制)。
2.在脚本窗格中,无论脚本是图表叠加还是单独窗格。
3.在刻度中(只显示最后一个K线的值,由"图表设置/刻度"选项卡中的"指标最后值标签"复选框控制)。
4.在"数据窗口"中(使用图表右侧向下的第四个图标即可调出)。
 请注意前面截图中的以下内容:
请注意前面截图中的以下内容:
l 图表的光标位于数据集的第一条K线,其中 bar_index 为零。该值反映在指标名称旁边和数据窗口中。在其他K线上移动光标会更新这些值,使它们始终代表该K线上的绘图值。这是在脚本执行过程中逐条检查变量值的好方法。
l 我们调用 plot() 时的标题参数"Bar Index"将用作数据窗口中数值的图例。
l 数据窗口中显示值的精度取决于图表符号的刻度值。您可以通过以下两种方式进行修改
n 更改脚本"设置/样式"选项卡中"精度"字段的值。使用这种方法最多可以获得八位数的精度。
n 在脚本的indicator()或strategy()声明语句中使用精度参数。该方法最多可指定16位精度。
l 脚本中的plot()调用会在指标窗格中绘制bar_index的值,显示变量值的增加。
l 脚本窗格的缩放比例会自动调整,以适应脚本中所有plot()调用绘制的最小和最大值。
前面截图中的脚本使用了最简单的方法来查看数值调用 plot()在脚本的显示区域绘制一条与变量值相对应的线。我们的示例脚本绘制了内建变量bar_index的值,该变量包含K线的编号,数据集第一个K线的编号从0开始,以后每个K线的编号增加 1。我们使用plot()调用来绘制要检查的变量,因为我们的脚本并没有绘制其他任何东西;我们并没有刻意保留比例尺,以便其他绘图继续正常绘制。这就是我们使用的脚本:
//@version=5
indicator("Plot `bar_index`")
plot(bar_index, "Bar Index")
在脚本显示区域绘制数值并非总是可行。当我们已经在绘制其他图时,如果在脚本绘制边界之外添加变量值的调试图,就会导致图无法读取,这时如果我们想保留其他图的比例,就必须使用另一种技术来检查数值。
假设我们想继续检查 bar_index 的值,但这次是在同时绘制 RSI 的脚本中:
//@version=5
indicator("Plot RSI and `bar_index`")
r = ta.rsi(close, 20)
plot(r, "RSI", color.black)
plot(bar_index, "Bar Index")
在包含大量K线的数据集上运行该脚本,会得到如下结果:
其中:
1.黑色的 RSI 线是平的,因为它在 0 和 100 之间变化,但指标窗格按比例显示了 bar_index 的最大值,即 25692.0000。
2.光标所在K线的bar_index值显示在指标名称旁边,其在脚本窗格中的蓝色绘图是平的。
3.刻度中显示的 25692.0000 的 bar_index 值代表其在最后一根K线上的值,因此数据集包含 25693 根K线。
4.光标所在K线的 bar_index 值也会显示在数据窗口中,同时显示的还有该K线上方的 RSI 值。
为了保留RSI的绘图,同时还能查看bar_index的值,我们将使用plotchar()绘制该变量,如下所示:
//@version=5
indicator("Plot RSI and `bar_index`")
r = ta.rsi(close, 20)
plot(r, "RSI", color.black)
plotchar(bar_index, "Bar index", "", location.top)
其中:
l 因为在脚本窗格中不再绘制 bar_index 值,所以窗格的边界现在是 RSI 的边界,显示正常。
l plotchar()绘制的值显示在脚本名称旁边和数据窗口中。
l 我们调用plotchar()时没有绘制字符,因此第三个参数是空字符串(" ")。我们还指定location.top作为位置参数,这样在计算显示区域的边界时就不会影响符号的价格。
显示字符串必须使用 Pine Script® 标签。标签只出现在脚本的显示区域;标签中显示的字符串不会出现在数据窗口或其他任何地方。
下面演示了重复绘制显示符号名称的标签的最简单方法:
//@version=5
indicator("Simple label", "", true)
label.new(bar_index, high, syminfo.ticker)
默认情况下,图表上只显示最后50个标签。可以在脚本的indicator()或strategy()声明语句中使用max_labels_count参数,将标签数增加到最多500个。例如:
indicator("Simple label", "", true, max_labels_count = 500)
在Pine脚本中操作的字符串通常不会逐K线改变,因此最常用的可视化方法是在数据集的最后一条K线上绘制标签。这里,我们使用一个函数来创建一个只出现在图表最后一个K线上的标签。print()函数只有一个参数,即显示的文本字符串:
//@version=5
indicator("print()", "", true)
print(txt) =>
// 在第一个K线上创建标签.
var lbl = label.new(bar_index, na, txt, xloc.bar_index, yloc.price, color(na), label.style_none, color.gray, size.large, text.align_left)
// 在接下来的K线中,更新标签的 x 和 y 位置以及显示的文字.
label.set_xy(lbl, bar_index, ta.highest(10)[1])
label.set_text(lbl, txt)
print("Multiplier = " + str.tostring(timeframe.multiplier) + "\nPeriod = " + timeframe.period + "\nHigh = " + str.tostring(high))
print("Hello world!\n\n\n\n")
请注意最后一个代码示例中的以下内容:
l 我们使用print()函数来封装标签绘制代码。虽然每个K线都会调用该函数,但由于我们在函数中声明lbl变量时使用了var关键字,因此标签只在数据集的第一个K线时创建。创建标签后,我们只更新标签的x坐标、y坐标和每个连续K线的文本。如果我们不更新这些值,标签就会保留在数据集的第一个K线上,并且只会在该K线上显示文本字符串的值。最后请注意,我们使用ta.highest(10)[1]来垂直定位标签,通过使用前10个K线的最高点,我们可以防止标签在实时K线中移动。在其他情况下,您可能需要调整这个y位置。
l 我们调用 print() 函数两次,以说明如果因为调试多个字符串更容易而进行多次调用,可以通过使用正确数量的换行符(\n)分隔每个字符串来叠加它们的文本。
l 使用 str.tostring() 函数将数值转换为字符串,以便包含在要显示的文本中。
可以使用许多方法来显示满足条件的情况。本代码显示了六种识别 RSI 小于 30 的K线的方法:
//@version=5
indicator("Single conditions")
r = ta.rsi(close, 20)
rIsLow = r < 30
hline(30)
// Method #1: Change the plot's color.
plot(r, "RSI", rIsLow ? color.fuchsia : color.black)
// Method #2: 在显示屏底部区域绘制字符.
plotchar(rIsLow, "rIsLow char at bottom", "▲", location.bottom, size = size.small)
// Method #3: 在 RSI 线上绘制字符.
plotchar(rIsLow ? r : na, "rIsLow char on line", "•", location.absolute, color.red, size = size.small)
// Method #4: 在显示屏顶部区域绘制图形.
plotshape(rIsLow, "rIsLow shape", shape.arrowup, location.top)
// Method #5: Plot an arrow绘制箭头.
plotarrow(rIsLow ? 1 : na, "rIsLow arrow")
// Method #6: Change the background's color.
bgcolor(rIsLow ? color.new(color.green, 90) : na)
请注意:
l 我们在 rIsLow 布尔变量中定义了我们的条件,并在每个K线中进行评估。用于给变量赋值的 r < 30 表达式会求值为 true 或 false(当 r 为 na 时,则为 na,数据集的第一个K线就是这种情况)。
l 方法#1使用RSI图形颜色的变化来判断条件。每当曲线图的颜色发生变化时,就会从上一K线开始为曲线图着色。
l 方法#2使用plotchar()在指标显示的底部绘制一个向上三角形。使用不同的位置和字符组合,在单个K线上同时识别多个条件。这是在图表上识别条件的首选方法之一。
l Method #3也使用plotchar()调用,但这次字符被放置在RSI线上。为此,我们使用location.absolute和Pine Script®的 ?: 三元条件运算符定义了一个条件表达式,只有当rIsLow条件为真时,才会使用y位置。如果不为真,则使用na,因此不会显示任何字符。
l 方法 #4 使用 plotshape() 在满足条件时,在指标显示区域的顶部绘制蓝色向上箭头。
l Method #5 使用 plotarrow() 在满足条件时,在显示区域的底部绘制一个绿色的向上箭头。
l 方法 #6 使用 bgcolor() 在满足条件时更改背景颜色。三元运算符再次用于评估我们的条件。当 rIsLow 为 true 时,它将返回 color.green,而当 rIsLow 为 false 或 na 时,它将返回 na 颜色(不给背景着色)。
l 最后,请注意布尔变量的真值在数据窗口中显示为1,假值显示为0。
程序员需要识别满足一个以上条件的情况,必须使用and逻辑运算符将单个条件聚合起来,从而建立复合条件。因为只有在单个条件正确触发的情况下,复合条件才会按照预期执行,所以如果在代码中使用复合条件之前先验证单个条件的行为,就可以省去很多麻烦。
多个单个条件的状态可以通过类似下面这种技术来显示,其中四个单个条件用于构建bull复合条件:
//@version=5
indicator("Compound conditions")
periodInput = input.int(20)
bullLevelInput = input.int(55)
r = ta.rsi(close, periodInput)
// Condition #1.
rsiBull = r > bullLevelInput
// Condition #2.
hiChannel = ta.highest(r, periodInput * 2)[1]
aboveHiChannel = r > hiChannel
// Condition #3.
channelIsOld = hiChannel >= hiChannel[periodInput]
// Condition #4.
historyIsBull = math.sum(rsiBull ? 1 : -1, periodInput * 3) > 0
// 复合条件.
bull = rsiBull and aboveHiChannel and channelIsOld and historyIsBull
hline(bullLevelInput)
plot(r, "RSI", color.black)
plot(hiChannel, "High Channel")
plotchar(rsiBull ? bullLevelInput : na, "rIsBull", "1", location.absolute, color.green, size = size.tiny)
plotchar(aboveHiChannel ? r : na, "aboveHiChannel", "2", location.absolute, size = size.tiny)
plotchar(channelIsOld, "channelIsOld", "3", location.bottom, size = size.tiny)
plotchar(historyIsBull, "historyIsBull", "4", location.top, size = size.tiny)
bgcolor(bull ? not bull[1] ? color.new(color.green, 50) : color.new(color.green, 90) : na)
请注意:
l 我们使用 plotchar() 调用来显示每个条件的编号,注意将它们安放在指标的y空间内,以免重叠。
l 前两个plotchar()使用绝对定位来放置条件编号,以便帮助我们记住相应的条件。例如,第一个调用在RSI高于用户定义的牛市水平时显示"1",将"1"定位在牛市水平上。
l 我们使用两种不同深浅的绿色作为背景色:较亮的绿色表示复合条件成真的第一个K线,较浅的绿色表示复合条件继续成真的后续K线。
l 虽然从严格意义上讲,并不总是有必要将单个条件赋值给变量,因为它们可以直接用于布尔表达式中,但如果将条件赋值给变量名,就会使代码更具可读性,因为变量名会提醒您和读者它所代表的含义。在这种情况下,应始终优先考虑可读性,因为将条件赋值给变量名对性能的影响微乎其微,甚至没有影响。
函数中的变量是函数的局部变量,因此无法在脚本的全局范围内进行绘制。在本脚本中,我们编写了 hlca() 函数来计算加权平均值:
//@version=5
indicator("Debugging from inside functions", "", true)
hlca() =>
var float avg = na
hlca = math.avg(high, low, close, nz(avg, close))
avg := ta.sma(hlca, 20)
h = hlca()
plot(h)
在函数逐条计算时,我们需要检查函数局部域中hlca的值。我们无法从脚本的全局域访问函数内部使用的hlca变量。因此,我们需要另一种机制来从函数的局部域中获取该变量的值,同时还能使用函数的结果。我们可以利用Pine Script®的功能,让函数返回一个元组来访问变量:
//@version=5
indicator("Debugging from inside functions", "", true)
hlca() =>
var float avg = na
instantVal = math.avg(high, low, close, nz(avg, close))
avg := ta.sma(instantVal, 20)
// 返回两个值而不是一个值.
[avg, instantVal]
[h, instantVal] = hlca()
plot(h, "h")
plot(instantVal, "instantVal", color.black)
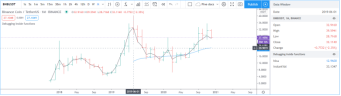
与全局域变量相反,全局定义数组的数组元素可以在函数中修改。可以利用这一特性编写功能等同的脚本:
//@version=5
indicator("Debugging from inside functions", "", true)
// 创建一个只包含一个浮点元素的数组.
instantValGlobal = array.new_float(1)
hlca() =>
var float avg = na
instantVal = math.avg(high, low, close, nz(avg, close))
// 将数组中唯一的元素设置为 `_instantVal`的当前值.
array.set(instantValGlobal, 0, instantVal)
avg := ta.sma(instantVal, 20)
h = hlca()
plot(h, "h")
// 读取在函数内部设置的数组唯一元素的值.
plot(array.get(instantValGlobal, 0), "instantValGlobal", color.black)
在循环中调用plot()无法绘制for循环内部的值。与函数一样,这些变量也是循环作用域的局部变量。下面,我们将从这个代码示例开始,探讨三种不同的技术,以检查源于for循环的变量值,该示例用于计算回溯周期内比当前K线具有更高/更低真实范围值的K线的余额:
//@version=5
indicator("Debugging from inside `for` loops")
lookbackInput = input.int(20, minval = 0)
float trBalance = 0
for i = 1 to lookbackInput
trBalance := trBalance + math.sign(ta.tr - ta.tr[i])
hline(0)
plot(trBalance)
如果要查看循环中某个变量的单点值,我们可以保存它,并在退出循环后绘制曲线。在这里,我们将 tr 的值保存在循环最后一次迭代时的 val 变量中:
//@version=5
indicator("Debugging from inside `for` loops", max_lines_count = 500, max_labels_count = 500)
lookbackInput = input.int(20, minval = 0)
float val = na
float trBalance = 0
for i = 1 to lookbackInput
trBalance := trBalance + math.sign(ta.tr - ta.tr[i])
if i == lookbackInput
val := ta.tr[i]
hline(0)
plot(trBalance)
plot(val, "val", color.black)
当我们想从多个循环迭代中提取数值时,可以使用线条和标签。在这里,我们画一条线,对应每个循环迭代中使用的 ta.tr 值。我们还使用标签来显示每一行的循环索引和该行的值。这样我们就能大致了解每个循环迭代中使用的值:
//@version=5
indicator("Debugging from inside `for` loops", max_lines_count = 500, max_labels_count = 500)
lookbackInput = input.int(20, minval = 0)
float trBalance = 0
for i = 1 to lookbackInput
trBalance := trBalance + math.sign(ta.tr - ta.tr[i])
line.new(bar_index[1], ta.tr[i], bar_index, ta.tr[i], color = color.black)
label.new(bar_index, ta.tr[i], str.tostring(i) + "•" + str.tostring(ta.tr[i]), style = label.style_none, size = size.small)
hline(0)
plot(trBalance)
请注意:
l 为了显示更多细节,前面截图中的比例尺是通过点击并拖动比例尺区域手动扩大的。
l 我们在indicator()声明语句中使用max_lines_count = 500、max_labels_count = 500来显示最大线条数和标签数。
l 每次循环迭代不一定会产生一个不同的 ta.tr 值,这就是为什么我们可能看不到每个K线有 20 条不同的线。
l 如果只想显示一个级别,我们可以使用相同的技术,同时像前面的示例那样隔离特定的循环迭代。
我们还可以从循环迭代中提取多个值,方法是创建一个字符串,在循环执行后使用标签显示:
//@version=5
indicator("Debugging from inside `for` loops", max_lines_count = 500, max_labels_count = 500)
lookbackInput = input.int(20, minval = 0)
string = ""
float trBalance = 0
for i = 1 to lookbackInput
trBalance := trBalance + math.sign(ta.tr - ta.tr[i])
string := string + str.tostring(i, "00") + "•" + str.tostring(ta.tr[i]) + "\n"
label.new(bar_index, 0, string, style = label.style_none, size = size.small, textalign = text.align_left)
hline(0)
plot(trBalance)

请注意:
l 前面截图中的刻度是通过点击并拖动刻度区域手动展开的,这样就可以垂直移动指标显示区域的内容,使其只显示相关部分。
l 我们使用 str.tostring(i, "00") 强制将循环的索引显示为零填充的两位数,使其整齐对齐。
当迭代次数较多的循环无法显示所有值时,可以对迭代次数的子集进行采样。这段代码使用 %(modulo)运算符包含了循环每两次迭代的值:
for i = 1 to i_lookBack
lowerRangeBalance := lowerRangeBalance + math.sign(ta.tr - ta.tr[i])
if i % 2 == 0
string := string + str.tostring(i, "00") + "•" + str.tostring(ta.tr[i]) + "\n"
我们在调试 Pine Script® 代码时最常用的两种技术是:
plotchar(v, "v", "", location.top, size = size.tiny)
用于在指标值和数据窗口中绘制 float、int 或 bool 类型的变量,而我们的 print() 函数的单行版本则用于调试字符串:
print(txt) => var _label = label.new(bar_index, na, txt, xloc.bar_index, yloc.price, color(na), label.style_none, color.gray, size.large, text.align_left), label.set_xy(_label, bar_index, ta.highest(10)[1]), label.set_text(_label, txt)
print(stringName)
由于我们使用 Windows 版 AutoHotkey 来加快重复性工作的速度,因此我们在 AutoHotkey 脚本中加入了这些行(这不是 Pine Script® 代码):
; ————— 这是 AHK 代码,而不是 Pine Script®. —————^+f:: SendInput plotchar(^v, "^v", "", location.top, size = size.tiny){Return}^+p:: SendInput print(txt) => var lbl = label.new(bar_index, na, txt, xloc.bar_index, yloc.price, color(na), label.style_none, color.gray, size.large, text.align_left), label.set_xy(lbl, bar_index, highest(10)[1]), label.set_text(lbl, txt)`nprint(){Left}
当我们使用 ctrl + shift + f 时,第二行将键入一个调试 plotchar() 调用,其中包括先前复制到剪贴板的表达式或变量名。将 variableName 变量名或 close > open 条件表达式复制到剪贴板并点击 ctrl + shift + f 将分别产生结果:
plotchar(variableName, "variableName", "", location.top, size = size.tiny)
plotchar(close > open, "close > open", "", location.top, size = size.tiny)
第三行通过 ctrl + shift + p 触发,在脚本中键入我们的单行 print() 函数,并在第二行空调用该函数,同时放置光标,因此只需键入我们要显示的字符串即可:
print(txt) => var lbl = label.new(bar_index, na, txt, xloc.bar_index, yloc.price, color(na), label.style_none, color.gray, size.large, text.align_left), label.set_xy(lbl, bar_index, ta.highest(10)[1]), label.set_text(lbl, txt)
print()
注意:AutoHotkey 仅适用于 Windows 系统。在苹果系统上可以用 Keyboard Maestro 或其他软件代替。
发布脚本
程序员如果希望与其他交易员分享自己的 Pine 脚本,可以将其发布。
如果您编写的脚本仅供个人使用,则无需发布;您可以将脚本保存在Pine脚本编辑器中,然后使用“添加到图表”按钮将脚本添加到图表中。
发布脚本时,你可以控制其可见性和访问权限:
l 通过选择公开发布或私密发布来控制可见性。详情请参阅帮助中心中的“ How do private ideas and scripts differ from public ones?”。当您编写的脚本对TradingViewers有用时,请公开发布。公开脚本会受到审核。为避免审核,请确保您的发布符合我们的《内部规则》和《脚本发布规则》。当您不想让其他用户看到您的脚本,只想与几个朋友分享时,请私下发布。
l 访问权限决定了用户是否能看到你的源代码,以及他们如何使用你的脚本。有三种访问类型:开放、受保护(保留给付费账户)或仅限邀请(保留给高级账户)。详情请参阅帮助中心中的“What are the different types of published scripts?”
l 发布脚本的标题由脚本的 indicator() 或 strategy() 声明语句中标题参数所使用的参数决定。当TradingViewers搜索脚本名称时,也会使用该标题。
l 图表上的脚本名称将是脚本的 indicator() 或 strategy() 声明语句中shorttitle参数的参数,或library()中的title参数。
l 脚本必须有说明,解释脚本的作用和使用方法。
l 您在发布时使用的图表将在您的发布页中可见,包括上面的任何其他脚本或绘图。发布脚本前,请从图表中删除无关的脚本或绘图。
l 您的脚本代码以后可以更新。每次更新都可以包含发布说明,这些说明将在您的原始描述下显示,并注明日期。
l 脚本可以被其他用户收藏、分享、评论或报告。
l 您发布的脚本会显示在用户配置文件的"脚本"选项卡下。
l 我们会为您的脚本创建脚本小部件和脚本页面。脚本 Widget 是您的脚本占位符,显示在平台上的脚本源中。它包含脚本的标题、图表和前几行说明。当用户点击脚本部件时,脚本页面就会打开。该页面包含与脚本相关的所有信息。
公开
当您发布公开脚本时:
l 您的脚本将被包含在我们的社区脚本中,所有国际版本网站上的数百万 TradingViewers 都可以看到它。
l 您发布的脚本必须遵守网站规则和脚本发布规则。
l 如果您的脚本是受邀脚本,您必须遵守我们的供应商要求。
l 可通过脚本搜索功能访问。
l 您将无法编辑您的原始描述或标题,也无法更改其公开/私密可见性或访问类型(开源、受保护、仅限邀请)。
l 您将无法删除您的出版物。
私密
当您发布私密脚本时:
l 除非与其他用户共享网址,否则其他用户无法看到脚本。
l 您可以在用户配置文件的"脚本"选项卡中看到该脚本。
l "X"和"lock"图标位于脚本窗口的右上方,可以识别私密脚本。"X"用于删除脚本。
l 除非您出售其访问权限或将其公开,否则不会对其进行审核,因为这样它就不再是"私密"的了。
l 您可以更新其原始描述和标题。
l 您不能从任何公开的 TradingView 内容(观点、脚本描述、评论、聊天等)链接或提及它。
l 通过脚本搜索功能无法访问该脚本。
公开或私密脚本可以使用三种访问类型之一发布:公开、受保护或仅邀请。您可以选择的访问类型将随您持有的帐户类型而变化。
开放式
所有用户均可看到公开发布的脚本的Pine Script®代码。TradingView的开源脚本默认使用Mozilla许可证,但您也可以选择任何许可证。您可以在GitHub上找到有关许可证的信息。
受保护
受保护脚本的代码是隐藏的,除作者外任何人都无法访问。虽然无法访问脚本代码,但任何用户都可以自由使用受保护的脚本。只有专业版、专业版+ 或高级版账户才能发布公开的受保护脚本。
仅限邀请
只邀请访问类型既保护脚本代码,也保护脚本的使用。只接受邀请脚本的发布者必须明确授予单个用户访问权限。只接受邀请的脚本主要用于为脚本提供付费访问权限的脚本供应商。只有高级账户才能发布只接受邀请的脚本,并且必须符合我们的供应商要求。
TradingView不会从脚本销售中获益。有关只接受邀请的脚本的交易仅在用户和供应商之间进行,不涉及TradingView。
公开的只接受邀请的脚本是唯一允许供应商在TradingView上要求付款的脚本。
在只接受邀请的脚本页面上,作者会看到一个"管理访问"按钮。通过"管理访问"窗口,作者可以控制谁可以访问他们的脚本。
1.即使您打算公开发布,最好也先从私密发布开始,因为您可以用它来验证最终发布的内容。您可以编辑私人出版物的标题、说明、代码或图表,而且与公开脚本不同,您可以在不需要私密脚本时将其删除,因此私密脚本是在公开分享脚本之前进行练习的最佳途径。有关编写脚本说明的更多信息,请参阅出版物《我们如何编写和格式化脚本说明》。
2.准备图表 将脚本加载到图表上,并移除其他无助于用户理解脚本的脚本或图画。脚本的绘图应易于在图表上识别,并与图表一起发布。
3.在 Pine 编辑器中加载您的代码(如果还没有的话)。在编辑器中点击"发布脚本"按钮:
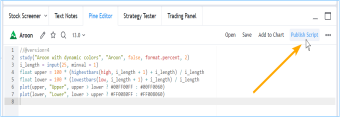
4.弹出一个提示窗口,提醒您如果公开发布,请务必遵守发布规则。弹出提示后,请在脚本标题下方的字段中输入您的描述。出版物的默认标题是脚本代码中的标题字段。最好始终使用该标题;如果您的脚本是公开的,它能让用户更容易搜索到您的脚本。选择出版物的可见性。我们要发布的是私密发布,因此要选中"发布脚本"窗口右下方的"私密脚本"复选框:
5.为脚本选择访问类型:开放、受保护或仅受邀请。我们选择“Open”表示开源。

6.为脚本选择适当的类别(至少一个是必选项),并输入可选的自定义标签。
 7.点击窗口右下方的"发布私密脚本"按钮。发布完成后,将显示已发布脚本的页面。发布完成!您可以进入"用户配置文件",查看"脚本"选项卡,确认发布。在那里,您可以打开脚本页面,使用脚本页面右上方的"编辑"按钮编辑您的私人出版物。请注意,您也可以更新私人出版物,就像更新公开出版物一样。如果您想与朋友分享您的私人出版物,请从您的脚本页面私下向她发送网址。请记住,您不能在公共 TradingView 内容中分享私人出版物的链接。
7.点击窗口右下方的"发布私密脚本"按钮。发布完成后,将显示已发布脚本的页面。发布完成!您可以进入"用户配置文件",查看"脚本"选项卡,确认发布。在那里,您可以打开脚本页面,使用脚本页面右上方的"编辑"按钮编辑您的私人出版物。请注意,您也可以更新私人出版物,就像更新公开出版物一样。如果您想与朋友分享您的私人出版物,请从您的脚本页面私下向她发送网址。请记住,您不能在公共 TradingView 内容中分享私人出版物的链接。
无论您是打算私下发布还是公开发布,首先都要按照上一节的步骤进行。如果您打算私下发布,那么您的工作就完成了。如果您打算公开发布,并对验证私密发布的准备过程感到满意,请按照上述相同步骤操作,但不要勾选"私密脚本"复选框,然后单击"发布脚本"页面右下方的"发布公开脚本"按钮。
发布新的公开脚本后,您有 15 分钟的时间修改说明或删除发布内容。之后,您将无法更改出版物的标题、描述、可见性或访问类型。如果您出错了,请向 PineCoders 版主账户发送消息;他们负责管理脚本出版物,并会提供帮助。
更新出版物
您可以更新公开或私密的脚本出版物。更新脚本时,其代码必须与之前发布版本的代码不同。您可以在更新时添加发布说明。它们将出现在脚本页面中脚本原始描述的后面。
默认情况下,更新时使用的图表将取代脚本页面中先前的图表。不过,也可以选择不更新脚本页面的图表。注意,虽然可以更新页面中显示的图表,但小部件中的图表不会更新。
与先发布私密脚本再验证公开发布的方式相同,您也可以先验证私密发布上的更新,然后再在公开发布上进行更新。更新已发布脚本的过程对于公共脚本和私密脚本都是一样的。
如果您打算更新已发布脚本的代码和图表,请按照新发布脚本的方法准备图表。在下面的示例中,我们将不更新出版物的图表:
1.像制作新出版物一样,在编辑器中加载脚本,然后单击“发布脚本”按钮。
2.进入“发布脚本”窗口后,选择"更新现有脚本"按钮。然后从“选择脚本”下拉菜单中选择要更新的脚本:
3.在文本字段中输入您的发布说明。代码中的不同之处会在发布说明下方突出显示。
4.不想更新出版物的图表,可以选中“不更新图表”复选框:
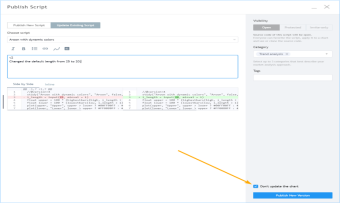
5.点击“发布新版本”按钮。这样就完成了。
限制
· 正如我们的欢迎页面所述:
由于每个脚本都使用云中的计算资源,我们必须施加限制,以便在用户之间公平共享这些资源。我们努力设置尽可能少的限制,但当然也会根据平台顺利运行的需要设置尽可能多的限制。限制适用于从附加符号请求的数据量、执行时间、内存使用量和脚本大小。
如果你使用 Pine Script® 开发复杂的脚本,迟早会遇到我们的一些限制。本节将概述你可能会遇到的限制。目前,Pine Script®程序员还无法获得脚本所消耗资源的数据。我们希望将来能改变这种状况。
同时,在考虑大型项目时,最稳妥的做法是进行概念验证,以评估脚本在项目后期遇到限制的可能性。
以下是 Pine Script® 环境中的限制。
在图表上执行脚本之前,必须对其进行编译。当你从编辑器中保存脚本或在图表中添加脚本时,都需要编译脚本。编译时间有两分钟的限制,这取决于脚本的大小和复杂程度,以及是否有之前编译的缓存版本。当编译时间超过两分钟限制时,系统会发出警告。请注意该警告,缩短脚本的长度,因为连续三次警告后,一小时内禁止尝试编译。优化代码时首先要考虑的是避免重复,使用函数封装经常使用的代码段,并调用函数而不是重复代码。
脚本编译完成后即可执行。有关触发脚本执行的事件列表,请参阅 "触发脚本执行的事件"。脚本在数据集所有K线上的执行时间因账户类型而异。 基本账户的限时为 20 秒,其他账户为 40 秒。
任何单个K线循环的执行时间限制为500毫秒。嵌入式循环的外循环算作一个循环,因此会首先超时。请记住,即使一个循环在给定K线上的执行时间低于500毫秒限制,但它在数据集所有K线上的执行时间仍可能导致脚本超过总执行时间限制。例如,总执行时间限制会使脚本无法在20,000条数据集的每条K线上执行400毫秒的循环,因为脚本需要8000秒才能执行完毕。
每个脚本最多允许64个图表数。生成图表计数的函数有:
· plot()
· fill(),但前提是其颜色为系列形式。
以下函数不会生成绘图计数:
· ·hline()
· ·line.new()
· ·label.new()
· ·table.new()
· ·box.new()
一个函数调用最多可生成7个绘图计数,具体取决于函数及其调用方式。当脚本超过64个绘图计数的上限时,运行时错误信息将显示脚本生成的绘图计数。达到这一上限后,可以通过在脚本中注释函数调用来确定函数调用产生的绘图次数。只要脚本仍会出错,您就能看到注释掉一行后实际绘图次数的减少情况。
下面的示例显示了不同的函数调用以及每个函数调用产生的绘图次数:
//@version=5
indicator("Plot count example")
bool isUp = close > open
color isUpColor = isUp ? color.green : color.red
bool isDn = not isUp
color isDnColor = isDn ? color.red : color.green
// 各使用一个绘图计数.
p1 = plot(close, color = color.white)
p2 = plot(open, color = na)
// 为 "close "和 "color "系列使用两个绘图计数器.
plot(close, color = isUpColor)
// 为 "close "系列使用一个绘图计数.
plotarrow(close, colorup = color.green, colordown = color.red)
// 为 "close "和 "colorup "系列使用两个绘图计数器.
plotarrow(close, colorup = isUpColor)
// 为 "close"、"colorup "和 "colordown "系列使用三个绘图计数器.
plotarrow(close - open, colorup = isUpColor, colordown = isDnColor)
// 为`open`, `high`, `low`, and `close`系列使用四个绘图计数器.
plotbar(open, high, low, close, color = color.white)
// 使用五个绘图计数来进行 `open`, `high`, `low`,`close`, `color`
plotbar(open, high, low, close, color = isUpColor)
// 4个绘图计数 `open`, `high`, `low`, and `close` series.
plotcandle(open, high, low, close, color = color.white, wickcolor = color.white, bordercolor = color.purple)
//5个计数`open`, `high`, `low`, `close`, and `color` series.
plotcandle(open, high, low, close, color = isUpColor, wickcolor = color.white, bordercolor = color.purple)
//6个计数 `open`, `high`, `low`, `close`, `color`, and `wickcolor` series.
plotcandle(open, high, low, close, color = isUpColor, wickcolor = isUpColor , bordercolor = color.purple)
// Uses seven plot counts for the `open`, `high`, `low`, `close`, `color`, `wickcolor`, and `bordercolor` series.
plotcandle(open, high, low, close, color = isUpColor, wickcolor = isUpColor , bordercolor = isUp ? color.lime : color.maroon)
// Uses one plot count for the `close` series.
plotchar(close, color = color.white, text = "|", textcolor = color.white)
// Uses two plot counts for the `close`` and `color` series.
plotchar(close, color = isUpColor, text = "—", textcolor = color.white)
// Uses three plot counts for the `close`, `color`, and `textcolor` series.
plotchar(close, color = isUpColor, text = "O", textcolor = isUp ? color.yellow : color.white)
// Uses one plot count for the `close` series.
plotshape(close, color = color.white, textcolor = color.white)
// Uses two plot counts for the `close` and `color` series.
plotshape(close, color = isUpColor, textcolor = color.white)
// Uses three plot counts for the `close`, `color`, and `textcolor` series.
plotshape(close, color = isUpColor, textcolor = isUp ? color.yellow : color.white)
// Uses one plot count.
alertcondition(close > open, "close > open", "Up bar alert")
// Uses one plot count.
bgcolor(isUp ? color.yellow : color.white)
// Uses one plot count for the `color` series.
fill(p1, p2, color = isUpColor)
本例生成的绘图次数为56。如果再增加两次对plotcandle()的最后一次调用,脚本就会出错,说明脚本现在使用了70个绘图计数,因为每增加一次对plotcandle()的调用就会生成7个绘图计数,56 + (7 * 2) 就是70。
与可以覆盖整个数据集的plot绘图相反,默认情况下,图表上只能看到脚本绘制的最后50条线。方框和标签也是如此。indicator()或strategy()声明语句中的max_line_count、max_boxes_count或max_labels_count参数,可以将图表上保留绘制对象数量增加到最多500个。
在本示例中,我们将图表上显示的最后一个标签的最大数量设置为100:
//@version=5
indicator("Label limits example", max_labels_count = 100, overlay = true)
label.new(bar_index, high, str.tostring(high, format.mintick))
需要注意的是,当你将绘图对象的任何属性设置为na时,它仍然算作图表上的绘图,并因此计入脚本的绘图总数。为了演示这一点,下面的脚本在每个K线上绘制了一个"买入"和"卖出"标签,其x值由longCondition和shortCondition变量决定。当K线指数为偶数时,"买入"标签的x值为na;当K线指数为奇数时,"卖出"标签的x值为na。虽然本例中的max_labels_count为10,但我们可以看到,由于带有na值的标签也计入总数,因此脚本在图表上显示的标签少于10个:
//@version=5
// 标签图纸的大约最大数量
MAX_LABELS = 10
indicator("labels with na", overlay = false, max_labels_count = MAX_LABELS)
// 为最后一个 MAX_LABELS 条添加背景色.
bgcolor(bar_index > last_bar_index - MAX_LABELS ? color.new(color.green, 80) : na)
longCondition = bar_index % 2 != 0
shortCondition = bar_index % 2 == 0
// 在每个新 K 线上添加 "买入 "和 "卖出 "标签.
label.new(longCondition ? bar_index : na, 0, text = "Buy", color = color.new(color.green, 0), style = label.style_label_up)
label.new(shortCondition ? bar_index : na, 0, text = "Sell", color = color.new(color.red, 0), style= label.style_label_down)
plot(longCondition ? 1 : 0)
plot(shortCondition ? 1 : 0)
如果我们想让脚本显示所需的标签数,就需要删除那些 x 值为 na 的标签,这样就不会增加脚本的标签数。本示例有条件地绘制了"Buy"和"Sell"标签,而不是在交替的 K 线中总是绘制并将其属性设置为 na:
//@version=5
// 标签图纸的大约最大数量
MAX_LABELS = 10
indicator("conditional labels", overlay = false, max_labels_count = MAX_LABELS)
// 为最后一个 MAX_LABELS 条添加背景色.
bgcolor(bar_index > last_bar_index - MAX_LABELS ? color.new(color.green, 80) : na)
longCondition = bar_index % 2 != 0
shortCondition = bar_index % 2 == 0
// 当 "longCondition"为真时,添加 "Buy"标签.
if longCondition
label.new(bar_index, 0, text = "Buy", color = color.new(color.green, 0), style = label.style_label_up)
// 当 `shortCondition` 为真时,添加 "Sell"标签.
if shortCondition
label.new(bar_index, 0, text = "Sell", color = color.new(color.red, 0), style = label.style_label_down)
plot(longCondition ? 1 : 0)
plot(shortCondition ? 1 : 0)
一个脚本最多可显示九个表格,每个位置可显示一个:position.bottom_center, position.bottom_left, position.bottom_right, position.middle_center, position.middle_left, position.middle_right, position.top_center, position.top_left或 position.top_right。如果将两个表格放在同一位置,则只有最近添加的表格可见。
脚本对request.*()函数的调用次数不能超过40次。所有调用这些函数的情况都会被计算在内,即使它们包含在代码块中或脚本逻辑中从未实际使用过的函数中。受此限制的函数:request.security(), request.security_lower_tf(), request.quandl(), request.financial(), request.dividends(), request.earnings() and request.splits()。
使用request.security()或request.security_lower_tf()访问较低时间框架时,计算中最多可使用100,000个内部K线。
100,000个intrabars所覆盖的图表K线数量将随图表时间框架与所使用的较低时间框架的比率以及每个图表K线所包含的intrabars平均数量而变化。例如,在使用1分钟下部时间框架时,活跃的24x7市场 60 分钟时间框架的图表K线通常每个K线包含 60 个K线内柱。由于 100,000 / 60 = 1666.67,100,000 个K线内柱所覆盖的图表条数通常为1666。在市场上,60分钟图K线并不总是包含60个1分钟图K线,因此会覆盖更多的图K线。
一个脚本中的所有request.*()函数返回的元组值不能超过127个。下面的示例显示了导致这一错误的原因以及解决方法:
//@version=5
indicator("Tuple values error")
// CAUSES ERROR:
[v1, v2, v3,...] = request.security(syminfo.tickerid, "1D", [s1, s2, s3,...])
// Works fine:
type myType
int v1
int v2
int v3
...
myObj = request.security(syminfo.tickerid, "1D", myType.new())
请注意:
l 在本例中,我们的元组中至少有三个值的request.security()函数,而我们的上述元组中可能有超过127个值,或者多个request.security()函数之间有超过127个值,从而引发此错误。
l 我们只需创建一个User-defined对象,它就可以保存相同的值,而不会引发错误。
l 使用myType.new() 函数的功能与在[s1,s2,s3,...]元组中列出相同值的功能相同。
在脚本执行之前,它会被编译成标记化的中间语言(IL)。使用中间语言,Pine Script®可以在脚本执行前对其进行各种优化,以适应较长的脚本。每个指标、策略和库的编译形式都被限制为68,000个标记。当脚本导入库时,所有导入库的标记总数不能超过100万。无法检查编译过程中创建的标记数;只有当编译器达到限制时,你才会知道你的脚本超过了限制。
用函数调用代替代码重复,以及使用库来减轻工作量,是减少编译后脚本产生的标记数的最有效方法。
变量名和注释的大小不会影响编译后的标记数。
局部代码块是在函数定义或if、switch、for或while结构中使用的缩进代码段,允许使用一个或多个局部代码块。
脚本限制为500个局部代码块。
每个作用域最多允许使用1000个变量。Pine脚本始终包含一个全局作用域,并可包含零个或多个局部作用域。局部作用域由缩进代码创建,如函数或if、switch、for或while结构中的缩进代码,这些代码允许创建一个或多个局部块。每个局部块算作一个局部作用域。
使用 ?: 三元运算符的条件表达式的分支不算作局部块。
Pine Script® 集合(数组、矩阵和映射)最多可包含 100,000 个元素。映射中的每个键值对包含两个元素,这意味着映射最多可包含 50,000 个键值对。
使用[]历史引用操作符对过去值的引用取决于 Pine Script® 运行时维护的历史缓冲区的大小,该缓冲区最大限制为 5000 条 K 线。本帮助中心页面将讨论历史缓冲区,以及如何使用 max_bars_back 参数或 max_bars_back() 函数改变历史缓冲区的大小。
使用 xloc.bar_index 定位绘图时,可以使用大于当前 K 线的 K 线索引值作为 x 坐标。最多可以引用未来 500 条 K 线。
本示例展示了我们如何使用 input.int() 函数调用中的 maxval 参数,为我们绘制投影线的用户定义的向前条数设置上限,使其永远不会超过限制:
//@version=5
indicator("Max bars forward example", overlay = true)
// 该函数使用 K 线索引 x 坐标绘制一条 "线"。.
drawLine(bar1, y1, bar2, y2) =>
// 仅在最后一个 K 线执行此代码.
if barstate.islast
// 仅在最后一个 K 线第一次执行该函数时创建该线.
var line lin = line.new(bar1, y1, bar2, y2, xloc.bar_index)
// 在最后一 K 线的所有脚本执行中更改该线的属性。
line.set_xy1(lin, bar1, y1)
line.set_xy2(lin, bar2, y2)
// 决定我们向前绘制 `line` 的输入。
int forwardBarsInput = input.int(10, "Forward Bars to Display", minval = 1, maxval = 500)
// 计算直线的左点和右点.
int leftBar = bar_index[2]
float leftY = high[2]
int rightBar = leftBar + forwardBarsInput
float rightY = leftY + (ta.change(high)[1] * forwardBarsInput)
// 该函数调用在所有 K 线段上执行,但只在最后一个 K 线段上绘制`line.
drawLine(leftBar, leftY, rightBar, rightY)
图表上出现的 K 线数量取决于图表符号和时间框架的可用历史数据数量,以及您持有的账户类型。当所需的历史日期可用时,图表条数最少为:
l ·20,000 条(高级计划)。
l ·10,000 条,适用于专业版和专业版+计划。
l ·5000 条(其他计划)。
回测策略时最多可下达 9000 个订单。使用深度回溯测试时,限额为 200,000。
常见问题
· ·在 Heikin Ashi 图表上获取真实 OHLC 价格
· ·在标准图表上获取非标准 OHLC 值
· ·在图表上绘图箭头
· ·绘图动态水平线
· ·根据条件绘图垂直线
· ·获取前值
· ·获取 5 天高点
· · 计算数据集中的K线
· · 列举一天中的 K 线
· ·查找整个数据集中的最高值和最低值
· · 查询最后一个非 NA 值
在 Heikin Ashi 图表上获取真实的 OHLC 价格
假设我们有一个Heikin Ashi图表(或Renko、Kagi、PriceBreak等),并在上面添加了一个Pine脚本:
//@version=5
indicator("Visible OHLC", overlay=true)
c = close
plot(c)
您可能会看到,变量c是Heikin Ashi收盘价,与实际OHLC价格不同。因为内置的收盘价变量总是与图表上的可见K线(或蜡烛)相对应。
如果图表类型是非标准的,如何在Pine Script®代码中获取真实的OHLC呢?我们应该使用request.security函数和ticker.new函数。如下例:
//@version=5
indicator("Real OHLC", overlay = true)
t = ticker.new(syminfo.prefix, syminfo.ticker)
realC = request.security(t, timeframe.period, close)
plot(realC)
同样,我们还可以获得其他OHLC价格:开盘价、最高价和最低价。
不建议在非标准图表类型(如Heikin Ashi或Renko)上进行回测,因为这类图表上的K线并不代表您在交易时会遇到的真实价格走势。如果您希望您的策略以真实价格进入和退出,但仍然使用基于Heikin Ashi的信号,您可以使用相同的方法在普通蜡烛图上获取Heikin Ashi值:
//@version=5
strategy("BarUpDn Strategy", overlay = true, default_qty_type = strategy.percent_of_equity, default_qty_value = 10)
maxIdLossPcntInput = input.float(1, "Max Intraday Loss(%)")
strategy.risk.max_intraday_loss(maxIdLossPcntInput, strategy.percent_of_equity)
needTrade() => close > open and open > close[1] ? 1 : close < open and open < close[1] ? -1 : 0
trade = request.security(ticker.heikinashi(syminfo.tickerid), timeframe.period, needTrade())
if trade == 1
strategy.entry("BarUp", strategy.long)
if trade == -1
strategy.entry("BarDn", strategy.short)
使用带有shape.arrowup和shape.arrowdown样式的plotshape:
//@version=5
indicator('Ex 1', overlay = true)
condition = close >= open
plotshape(condition, color = color.lime, style = shape.arrowup, text = "Buy")
plotshape(not condition, color = color.red, style = shape.arrowdown, text = "Sell")
您可以对任何unicode字符使用plotchar函数:
//@version=5
indicator('buy/sell arrows', overlay = true)
condition = close >= open
plotchar(not condition, char='↓', color = color.lime, text = "Buy")
plotchar(condition, char='↑', location = location.belowbar, color = color.red, text = "Sell")
Pine Script®有一个函数hline,但它只能绘制恒定值。下面是一个简单脚本,可以通过变通方法绘制不断变化的 hline:
//@version=5
indicator("Horizontal line", overlay = true)
plot(close[10], trackprice = true, offset = -9999)
// `trackprice = true` 在 close[10] 上绘制水平线
// `offset = -9999` 隐藏绘图
plot(close, color = #FFFFFFFF) // 强制显示
//@version=5
indicator("Vertical line", overlay = true, scale = scale.none)
// scale.none表示不调整图表大小以适应该绘图
// 如果正在评估的 K 线是图表中的最后一个 K 线(最近的 K 线),则条件为 true
cond = barstate.islast
// 当 cond 为真时,用高度值为 100,000,000,000,000,000.00 的直线绘制直方图
//(10 到 20 的幂)
// 当 cond 为假时,不绘制数值直方图(不绘制任何内容)
// 使用直方图的样式,即垂直 K 线
plot(cond ? 10e20 : na, style = plot.style_histogram)
//@version=5
//...
s = 0.0
s := nz(s[1]) // Accessing previous values
if (condition)
s := s + 1
从当前 K 线回溯 5 天,找到最高的 K 线,在当前 K 线上方的该价位绘制星形字符:
//@version=5
indicator("High of last 5 days", overlay = true)
// 5 天内的毫秒数: 毫秒 * 秒 * 分 * 小时 * 天
MS_IN_5DAYS = 1000 * 60 * 60 * 24 * 5
// 范围检查从当前时间的 5 天后开始.
leftBorder = timenow - time < MS_IN_5DAYS
// 范围在图表的最后一个 K 线结束.
rightBorder = barstate.islast
// ————— 跟踪范围内最高的 `high`。
// 仅在第 0 个 K 线用 `var` 初始化 `maxHi` 。
// 这样,它的值就会一直保持在 K 线之间。.
var float maxHi = na
if leftBorder
if not leftBorder[1]
// 范围的第一个 K 线.
maxHi := high
else if not rightBorder
// 在范围内的其他 K 线上,跟踪最高的 `high.
maxHi := math.max(maxHi, high)
// 绘制最后一个 K 线的最高 "高点 "水平线.
plotchar(rightBorder ? maxHi : na, "Level", "—", location.absolute, size = size.normal)
// 在范围内时,给背景上色。
bgcolor(leftBorder and not rightBorder ? color.new(color.aqua, 70) : na)
对加载数据集中的所有 K 线进行计数。这可能有助于根据 K 线的数量计算灵活的回溯周期。
//@version=5
indicator("Bar Count", overlay = true, scale = scale.none)
plot(bar_index + 1, style = plot.style_histogram)
列举一天中的 K 线
//@version=5
indicator("My Script", overlay = true, scale = scale.none)
isNewDay() =>
d = dayofweek
na(d[1]) or d != d[1]
plot(ta.barssince(isNewDay()), style = plot.style_cross)
找出整个数据集的最高值和最低值
//@version=5
indicator("", "", true)
allTimetHi(source) =>
var atHi = source
atHi := math.max(atHi, source)
allTimetLo(source) =>
var atLo = source
atLo := math.min(atLo, source)
plot(allTimetHi(close), "ATH", color.green)
plot(allTimetLo(close), "ATL", color.red)
您可以使用下面的脚本来避免系列中出现间隙:
//@version=5
indicator("")
series = close >= open ? close : na
vw = fixnan(series)
plot(series, style = plot.style_linebr, color = color.red) // series has na values
plot(vw) // 所有 na 值将被最后一个非空值替换
错误信息·
if 语句太长
如果编译器认为if语句中的缩进代码过长,就会出现此错误。由于编译器的工作方式,你不会收到一条信息,告诉你到底有多少行代码超过了限制。现在唯一的解决办法是将if语句分解成更小的部分(函数或更小的if语句)。下面的示例显示了一个相当长的if语句;理论上,这将会抛出第4行:if语句太长。
//@version=5
indicator("My script")
var e = 0
if barstate.islast
a = 1
b = 2
c = 3
d = 4
e := a + b + c + d
plot(e)
要修复这段代码,可以将这几行移到它们自己的函数中:
//@version=5
indicator("My script")
var e = 0
doSomeWork() =>
a = 1
b = 2
c = 3
d = 4
result = a + b + c + d
if barstate.islast
e := doSomeWork()
plot(e)
脚本请求过多证券
脚本中证券的最大数量限制为 40 个。如果将一个变量声明为 request.security 函数调用,然后将该变量用作其他变量和计算的输入,则不会导致多次 request.security 调用。但如果你声明了一个调用 request.security 的函数,那么对该函数的每次调用都将算作一次 request.security 调用。
要知道源代码中会调用多少次 security 并不容易。下面的示例在编译后有 3 次调用 request.security:
//@version=5
indicator("Securities count")
a = request.security(syminfo.tickerid, '42', close) // (1) 第一个独特的安全呼叫
b = request.security(syminfo.tickerid, '42', close) // 与上述调用相同,优化后不会产生新的安全调用
plot(a)
plot(a + 2)
plot(b)
sym(p) => // 此线路无安全呼叫
request.security(syminfo.tickerid, p, close)
plot(sym('D')) // (2) 一次间接呼叫保安
plot(sym('W')) // (3) 对安全的又一次间接呼吁
request.security(syminfo.tickerid, timeframe.period, open) // 这一行的结果永远不会被使用,会被优化掉
脚本无法翻译自: null
study($)
这种错误通常出现在第一版 Pine 脚本中,意味着代码不正确。版本 2(或更高)的 Pine Script® 能更好地解释此类错误。因此,你可以在第一行添加一个特殊属性,尝试切换到版本 2。你会看到第 2 行:在字符"$"处没有可行的选择。
// @version=2
study($)
第2行:在字符"$"处没有可行的替代字符
这条错误信息提示了问题所在。$代表带有脚本标题的字符串。例如:
// @version=2
study("title")
输入<...>预期<???>不匹配
与无可行替代方案相同,但已知该位置应输入什么内容。举例说明:
//@version=5
indicator("My Script")
plot(1)
第 3 行:"plot "输入不匹配,预期为 "行尾无续行"。
解决这个问题,应用plot开始新的一行,不要缩进:
//@version=5
indicator("My Script")
plot(1)
循环时间过长(>500 毫秒)
我们限制每个历史 K 线和实时刻度线的循环计算时间,以保护服务器免受无限循环或超长循环的影响。这一限制也会使计算时间过长的指标失效。例如,如果您有 5000 条 K 线,而指标在每条 K 线上的计算时间为 500 毫秒,那么加载时间将超过 16 分钟。
//@version=5
indicator("Loop is too long", max_bars_back = 101)
s = 0
for i = 1 to 1e3 // to make it longer
for j = 0 to 100
if timestamp(2017, 02, 23, 00, 00) <= time[j] and time[j] < timestamp(2017, 02, 23, 23, 59)
s := s + 1
plot(s)
也许可以通过优化算法来克服这一错误。在这种情况下,算法可以这样优化:
//@version=5
indicator("Loop is too long", max_bars_back = 101)
bar_back_at(t) =>
i = 0
step = 51
for j = 1 to 100
if i < 0
i := 0
break
if step == 0
break
if time[i] >= t
i := i + step
i
else
i := i - step
i
step := step / 2
step
i
s = 0
for i = 1 to 1e3 // to make it longer
s := s - bar_back_at(timestamp(2017, 02, 23, 23, 59)) + bar_back_at(timestamp(2017, 02, 23, 00, 00))
s
plot(s)
脚本有太多局部变量
如果脚本太大而无法编译,则会出现此错误。语句 var=expression 会为 var 创建一个局部变量。除此之外,需要注意的是,在编译脚本的过程中还可以隐式创建辅助变量。该限制既适用于显式创建的变量,也适用于隐式创建的变量。1000 个变量的限制适用于每个函数。事实上,放置在脚本全局作用域中的代码也会隐式封装到主函数中,因此 1000 个变量的限制也适用于它。您可以尝试一些重构方法来避免这个问题:
var1 = expr1
var2 = expr2
var3 = var1 + var2
可以转换为:
var3 = expr1 + expr2
Pine Script® 无法确定系列的引用长度。请尝试在指标或策略函数中使用max_bars_back。
当Pine Script®错误地自动检测脚本中使用的系列的最大长度时,就会出现该错误。当脚本的执行流程不允许 Pine Script® 检查在条件语句(if、iff 或 ?)的分支中使用系列时,Pine Script® 无法自动检测系列的引用时间。下面是一个导致此问题的脚本示例:
//@version=5
indicator("Requires max_bars_back")
test = 0.0
if bar_index > 1000
test := ta.roc(close, 20)
plot(test)
为了帮助 Pine Script® 进行检测,应在脚本的指标或策略函数中添加 max_bars_back 参数:
//@version=5
indicator("Requires max_bars_back", max_bars_back = 20)
test = 0.0
if bar_index > 1000
test := ta.roc(close, 20)
plot(test)
您也可以通过将有问题的表达式从条件分支中移除来解决这个问题,在这种情况下,就不需要 max_bars_back 参数了:
//@version=5
indicator("My Script")
test = 0.0
roc20 = ta.roc(close, 20)
if bar_index > 1000
test := roc20
plot(test)
如果问题是由变量而不是内置函数(例如vwma)引起的,可以使用max_bars_back函数来明确定义该变量的引用长度。好处是所需的运行时资源较少,但需要确定有问题的变量,例如下面示例中的变量s:
//@version=5
indicator("My Script")
f(off) =>
t = 0.0
s = close
if bar_index > 242
t := s[off]
t
plot(f(301))
这种情况可以使用max_bars_back函数来解决,该函数只定义变量s的引用长度,而不是脚本中所有变量的引用长度:
//@version=5
indicator("My Script")
f(off) =>
t = 0.0
s = close
max_bars_back(s, 301)
if bar_index > 242
t := s[off]
t
plot(f(301))
当使用通过bar_index[n]和xloc = xloc.bar_index引用以前K线的绘图时,从该K线接收的时间序列将用于在时间轴上定位绘图。因此,如果无法确定缓冲区的正确大小,就可能出现这种错误。要避免这种情况,需要使用max_bars_back(time,n)。有关绘图的章节将详细介绍这种行为。